
その情報、ChatGPTに読み込ませても大丈夫? 自治体DXの専門的立場から考える(3/3 ページ)
すぐにでも情報資産の分類をしたいのなら
「そんなに長い期間待ってられない」「すぐにでも情報資産の分類をしたい」と言うのならば、現在のファイルサーバの中を自動的に検索して判別する仕組みが必要となります。
以前、私が開発した「PIスキャナー」というシステムがあります。このシステムはネットワーク分離環境でレベル2ネットワークからレベル1ネットワークへ情報資産を持ち出す際に内容をチェックするというものです。3種類のチェック方法があり、
- あらかじめ登録していたキーワードの有無を確認する方法
- 日本語コーパス(辞書)に基づき単語を検知する方法
- 過去に判別した文書の傾向と似ている文書をブロックする方法
を組み合わせるというものでしたが、特に過去の文章の傾向を分析してブロックするには、ブロックすべき文章を数多く学習させておかなればならないこともあり、ビジネス的にはイマイチな結果となっていました。
ところが最近の生成AIでは、事前学習なしで文書の判別ができそうだということで紹介したのが前回の機密性判別のプロンプトでした。そうは言っても、結局、最初の疑問に戻っている状態なので、もう少し技術的に解決する方法も考えてみましょう。
以前の記事で「ローカルLLM」という分野があることを書いたのですが、覚えているでしょうか。
(関連記事:「弱者の戦略」がDX成功の鍵に 生成AIに「できない理由」を投げてみると……?)
外部のサービスであるChatGPTに情報資産を持ち出すことが難しいのならば、庁内で動く生成AIを使うことで、この問題を解決できるかもしれません。
例えば、カナダの新興Cohere(コーヒア)社から提供されている「Command R+」というモデルは日本語処理の性能も高いとのことですし、 東大発のAIスタートアップELYZA社の「Llama-3-ELYZA-JP」というモデルも、GPT-4を上回る高い性能を持つと発表されています(なお、Command R+は商用利用不可なので、あくまでも非営利、研究目的利用となります)。これらを組み合わせることで、
ファイルサーバ内のファイルを順次取得
→取得したファイルからテキストデータを抽出
→事前登録キーワード判別などの下処理
→ローカルLLMでの判別
→判別結果に基づいたファイルのラベリング
――という処理を継続的に動作させることで、少しずつ庁内のファイルサーバの整理を進めていくことは、現実味を帯びてきているともいえます。
ちなみに私自身もこの仕組みは未検証ですが、来年あたりにGPUを多めに積んだサーバを準備して検証環境を作ってみたいと思います。
次回は「自治体における情報セキュリティの考え方」について、総務省のガイドラインのうち、2024年10月に改定された点を中心に考えを整理していきましょう。自治体にとって、なるべく人的負担や金銭的な負担をかけずに、どこまで実効性の高い対策を進められるかについて私も知恵を絞りたいと思います。
関連記事
 ChatGPTを使って「文書機密レベル」を判別する方法 自治体の情報セキュリティについて考える
ChatGPTを使って「文書機密レベル」を判別する方法 自治体の情報セキュリティについて考える
今回は「自治体における情報セキュリティの考え方」について見ていきたい。情報資産の「重要性レベル」をいかに判別していくべきなのか。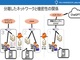 ChatGPTに重要な情報を送っても安全か? 自治体のネットワーク分離モデルから考える
ChatGPTに重要な情報を送っても安全か? 自治体のネットワーク分離モデルから考える
自治体における生成AIの利活用、今回は「送信された情報の管理の問題」、つまり「ChatGPTに重要な情報を送信しても安全なのか?」という点について考えたい。 自治体を苦しめてきた「オープンデータ公開」 負担軽減へ生成AIが秘める可能性とは?
自治体を苦しめてきた「オープンデータ公開」 負担軽減へ生成AIが秘める可能性とは?
今回は「自治体のオープンデータへの取り組みと生成AIの関係」について考える。長年、自治体職員の負担となってきたオープンデータの運用。生成AIの登場が現状を打開するきっかけとなる可能性があるという。 自治体の「DX推進計画」が失敗するのはなぜ? 評価指標を生成AIで正しく設定する方法
自治体の「DX推進計画」が失敗するのはなぜ? 評価指標を生成AIで正しく設定する方法
 プロンプトの悩み不要 自治体で使うべき「ChatGPT Plus」の機能とは?
プロンプトの悩み不要 自治体で使うべき「ChatGPT Plus」の機能とは?
生成AIを業務に導入する自治体が増える一方で、依然として活用に二の足を踏む自治体も。何がハードルになっているのか。
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PR注目記事ランキング
アイティメディアからのお知らせ



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。