ディープラーニングの広がりを可視化、予測する:約2000件を分析(3/6 ページ)
» 2015年08月03日 08時00分 公開
[深澤祐援,Credo]
今後注目される可能性が高い研究内容を予測する
では、その中でも今後有望視される可能性が高い分野とはどこかを予測してみます。
今回は、分析対象とするディープラーニングもその一部である機械学習を用います。中でも、「教師あり学習」という手法を用いました。
あらかじめ正解例を学習させてデータを分類する教師あり学習ですが、今回は正解例として、ネットワーク上において影響力が強い、または弱い点に関するデータを用いています(※2)。
※2=先行研究として“大規模学術論文データの共著ネットワーク分析に基づく萌芽領域の中心研究者予測に関する研究”(2015,森)を参考にしています。用いたパラメータは以下の通りです。
「ノード特徴量」:次数、近接性、媒介性、クラスタリング係数、隣接ノードの平均次数、固有値、Pagerank、トライアド数、離心性
「クラスタ特徴量」:モジュラリティ、hitsスコア(authority, hub)
分類にはSVMを用いました。ハイパーパラメータは8−交差検定におけるグリッドサーチの結果、gamma=0.01584893 ; cost=12.58925で正解率100%を得ました。
「ノード特徴量」:次数、近接性、媒介性、クラスタリング係数、隣接ノードの平均次数、固有値、Pagerank、トライアド数、離心性
「クラスタ特徴量」:モジュラリティ、hitsスコア(authority, hub)
分類にはSVMを用いました。ハイパーパラメータは8−交差検定におけるグリッドサーチの結果、gamma=0.01584893 ; cost=12.58925で正解率100%を得ました。
つまり、ネットワークの構造的に中心にあることを示す指標が上位5%の論文執筆者を“影響力の強い著者”、下位5%を“影響力の弱い著者”として正解例を作成し、それを用いて分類することで「今はまだ影響力は強くないが、今後強くなる可能性が高い著者」を探し出せないかと考えたのです。
コンピュータに学習させるパラメータは、各点がネットワークの構造的にどんな特徴を持っているかを示す指標を用いました。
次の図はどの点を正解例に使ったかを示しています。赤色の点は使わず、水色の点を正解例にしました。

この正解例を用いて教師あり学習を行い、分類させたのが次の図です。

黒い点は無視できる点を示しています。緑色の点は影響力が強い正解例として用いた点であり、少ないですが水色の点が今回注目すべき「今後影響力が強くなる可能性が高い」点です。
関連記事
 ディープラーニングとは何なのか? そのイメージをつかんでみる
ディープラーニングとは何なのか? そのイメージをつかんでみる
今や毎日のように人工知能に関するニュースが飛び込んできますが、その中でも特に注目を集めているのが“ディープラーニング”。そのディープラーニングとは一体何なのでしょうか。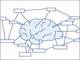 クリエイティブなコンピュータは出現するか?
クリエイティブなコンピュータは出現するか?
気付きや仮説を設定するという“クリエイティブ”な行為は、人間の大きな能力です。人工知能に膨大なデータを蓄積させることによって、いつの日か、人間のように「気付く」ようになるのでしょうか? 10年後になくなる可能性が高い職業とは(前編)
10年後になくなる可能性が高い職業とは(前編)
今回は、オックスフォード大学発表の論文に用いられている機械学習手法をもとに、日本で「なくなる可能性が高い職業」を具体的に考えてみます。 ソフトバンクの人型ロボット「Pepper」――今、人工知能で人の感情はどこまで分かるのか?
ソフトバンクの人型ロボット「Pepper」――今、人工知能で人の感情はどこまで分かるのか?
ソフトバンクがパーソナルロボット「Pepper」を発表した。感情認識機能が目玉のようだが、実際にロボットは人間の感情を認識できるのだろうか。 ロボット化が進めば、中間層はどうなるのか
ロボット化が進めば、中間層はどうなるのか
「人間がロボットに支配される」――。こんな話を本で読んだり、映画で見たことがある人も多いだろう。ロボットの性能が向上しているが、このまま進化していけば人間はどうなってしまうのだろうか。
関連リンク
Copyright © Credo All rights reserved.
Special
PR


注目記事ランキング
FeedBack



![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。