性能問題の失敗事例集:攻めの性能マネジメント
性能設計とは、目標性能と、その目標を実現するための設計です。業務量に応じたサーバサイジング、プロセス構成、業務処理の対象データ件数や処理の多重度などと多岐にわたり、性能マネジメントの中で最も重要な要素の1つといえます。(本文より)
失敗は成功の母といわれるように、失敗からはたくさんの教訓を得ることができる。連載第2回は、性能マネジメントで押さえるべきポイントを、失敗事例から学んでみたいと思う。
思い出すと心拍数が上がる性能問題の数々
さて今回は、私の身近で発生した性能問題の事例を振り返り、「攻めの性能マネジメント」として、性能問題予防のために実施すべき具体的な作業と考え方を整理したいと思います。
事例1:カットオーバーに間に合わない!
ある通信系システムでは、アプリケーションの品質が安定しなかったこともあり、開発工程の最後に性能評価を実施したところ、性能問題だけでなく、機能試験では抽出できないバグまでも発覚しました。しかし、サービス開始当初の業務量は少ないことがほぼ確実だったため、そのままカットオーバーし、運用しながらそれぞれの問題を解決していました。
これは第1回「出そうで出ないシステム性能」で紹介した、「最後に出たとこ勝負」に出たのに、うまくいかなかったパターンといえます。
このシステムの性能要件は「200端末同時接続」というものでしたが、同時多重接続をしたところ、負荷をかける前にエラーが発生しました。これはUNIXファイルディスクリプタの問題であることがわかったので、すぐに対策を行い、エラー原因を取り除きました。
そこで改めて200端末から負荷をかけたところ、次はCPU使用率が100%に張り付いてしまい、非常に遅いレスポンスしか得られませんでした。解析の結果、想定以上に重い処理が動くようなリクエストを送信していることが判明したので、負荷条件を修正しました。
気を取り直し、再度200端末から負荷をかけたところ(ここでようやくスタートラインに立ったとも言えます)、今度はレスポンスも速いうえにCPU使用率も十分低く、全く問題なさそうです。これで性能目標クリアかと安心したのもつかの間、再度エラーが発生するようになりました。原因は、一部のリクエストだけが異常にレスポンスが遅く、処理タイムアウトが発生したためでした。解析の結果、異常に遅かったのはログ出力であることが判明し、再度ログ量を削減するプログラム修正を実施して、なんとか性能目標を達成することができました。
最近、Javaソリューションフォーラムでも紹介されていましたが、ログ出力を侮ってはいけません。
この事例で発生した問題点を整理したものが以下の表です。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | 性能が悪いままカットオーバー | 問題多発でタイムアップ | できてない |
| 問題2 | 多重処理が動かない | ファイルディスクリプタ | OS設定変更 |
| 問題3 | レスポンス遅い | 負荷シナリオが不適切 | 負荷条件の適正化 |
| 問題4 | タイムアウト | ログが多過ぎた | プログラム修正 |
「よくある話なのでしょうがないよ」とあきらめるのは簡単ですが、皆さんならどうしますか?
事例2:6時間オーバーで朝までに終わらない
ある基幹系Webシステムで性能評価を実施したところ、夜間バッチ処理の一部が目標を6時間もオーバーするという問題が発覚しました。しかしDBサーバ上で完結するシンプルな処理だったことも幸いし、DBテーブルにインデックスを追加するだけで処理時間が短縮し、性能目標を達成することができました。
インデックスチューニングは、処理時間を100倍程度改善することも多く、一般的にはチューニングの代表的な例と考えられていますが、基本的にインデックスは「設計」するものなので、インデックスチューニングというのは、バグ修正といってもよい作業です。また、インデックスの追加や変更は、ほかの処理に大きな悪影響(=遅くなる)を与える危険性を秘めており、効果が高いからと安易に実施すると、痛い目に遭うことがあります。インデックスの追加や変更を行った場合は、悪影響の有無を確認しなければならず、これが意外と手間が掛かります。
では、この事例で発生した問題点もまとめておきましょう。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | バッチ処理が遅い | インデックスが足りない | インデックス追加+影響確認 |
事例3 : CPUは余裕なのにレスポンスが遅い
ある通信系システムでは、性能評価の結果、CPU等のハードウェアリソースに余裕があってもオンライン性能があるレベルから上がらないという問題が発覚しました。開発中にかなり時間をかけて解析したものの原因は特定できず、当初の業務量はなんとか処理できることは確認できていたため、そのままカットオーバーしました。
この状況は、業務量が増えた際にCPUを追加やサーバアップグレードでハードウェア性能を向上させても、システムの処理能力は向上しない、つまり、将来のトラフィック増に対応できないことを示しています。その後の調査でネットワークに原因があることが分かり、設定変更により問題が解決しましたが、そこに至るまでの調査と、問題を抱えたままカットオーバーすることへのリスク対応策の準備で、サーバが買えるほどのコストが掛かっています。
この事例で発生した問題と対策は以下のとおりです。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | 負荷試験でレスポンス悪化 | ネットワークのネゴシエーションエラー | 設定変更 |
事例4 : メモリは大切に
あるWebシステムでの性能評価でのこと、負荷生成ツールから多重でリクエストを送信すると、JavaのGC(ガベージコレクション)が多発して目標の性能が出ないことが判明しました。Javaのプロファイラを利用して原因を特定し、プログラム修正で問題を解決することができました。
原因は、検索処理の検索条件が甘く、想定以上のデータがDBの検索でヒットしてしまい、それをすべてアプリケーションのメモリに保持していた点にありました。ResultSetから作った大量のVOをHttpSessionに積みっ放しにしたともいえます。
検索処理を設計する際は、ヒットするレコード数の見積もりをどこかで行うとよいのですが、このシステムでは実施していなかったようです。そして素晴らしいことに、試験工程の早いうちから画面単体レスポンスを測定するという、理想的なプロセスを実践していたようなのですが、残念ながら利用したデータ量が少な過ぎて問題が検出できませんでした。
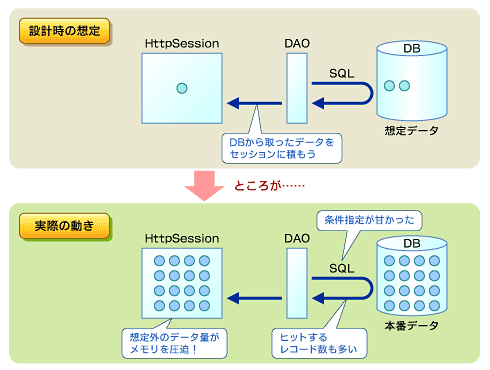
この事例で発生した問題と対策は以下のとおりです。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | オンライン性能が出ない | メモリの無駄遣い | プログラム修正 |
| 問題2 | 検索で大量レコードがヒット | 検索結果レコード数を見積もっていない | 設計で見積もりましょう |
| 問題3 | メモリの無駄遣いが検出できなかった | DBデータが少な過ぎた | 試験条件の適正化 |
事例5 : もうやるんですか?
これは私がSEになって初めてのシステムだったので、よく覚えています。このシステムでは性能リスクを考慮して、すべての機能が出来上がる前の、やや早い段階で性能評価を実施したところ、見事にオンライン性能が悪いという問題が発覚しました。CPUはほとんど使われておらず、DBサーバのディスク使用率が高いことから、ディスクI/Oに問題があることが疑われたため、データ配置の変更によるI/O分散と、プログラム修正によるI/O削減により、性能目標をクリアすることができ、無事にカットオーバーを迎えることができました。すみません。書いていて気付きましたが、これは成功事例ですね。
しかしギリギリの成功でした。I/O分散はディスクの本数が多い方が有利ですが、このシステムは物理的な事情で少ない本数のディスクしか搭載できませんでした(ミラーリング必須でした)。つまり、もう少しI/Oが多かったら、性能目標を達成するためには大幅なプログラム改造か上位機種のストレージ(かなり高い)に買い替えるしかなかったのです。
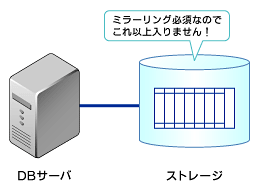
しつこいようですが、この事例で発生した問題と対策をまとめます。これで最後です。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | オンライン性能が悪い | DBサーバのI/Oネック | Oracleデータファイル配置変更によるI/O分散と、プログラム修正 |
| 問題2 | ディスクが追加できない | どうしようもない | リスクとして管理する |
以上、長くなりましたが4つの事例を挙げてみました。皆さんにも、「見ない」ことのリスクの大きさを感じていただけたら何よりです。
過去の教訓から性能マネジメントのポイントが見えてくる
今回ご紹介した事例の問題点から、教訓として得られるものがあります。
| 事例番号 | 教訓 | マネジメントのポイント |
|---|---|---|
| 事例1 | 評価するのが遅いと手遅れになる | 単体試験からの性能評価 |
| 事例1 | 評価条件が不適切だと結果が狂う | 評価条件をよく考えよう |
| 事例1 | ログサイズは早めに確認しておく | 単体試験からの性能評価 |
| 事例2 | インデックス設計は確実に | 性能設計をしよう |
| 事例3 | インフラの問題でアプリケーションは台無し | インフラ性能評価をやろう |
| 事例4 | データが少ないと問題が出ない | 評価条件をよく考えよう |
| 事例5 | ハード拡張の可否は事前に確認する | 性能設計をしよう |
この教訓と第1回で挙げた「見える化」のポイントを合わせ、開発工程の中で積極的に見える化ための方法を考える事で、性能問題の予防のために何をすべきかを整理したいと思います。
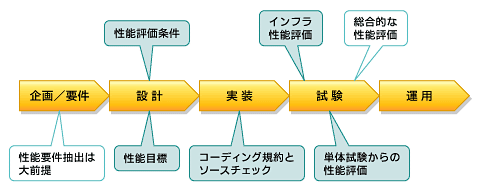
【ポイント1】 単体試験からの性能評価
対象:SW性能の見える化
工程:試験
単体試験と同様の粒度で性能が確認できると理想的ですが、ビジネスロジック単位や画面遷移単位での確認でもある程度の効果は期待できます。
事例からも分かるとおり、開発の最後に性能評価を実施して問題が発覚した場合、リリースに間に合わない可能性がとても大きいです。また、プログラム修正は最もチューニング効果があるのですが、機能品質確保のために、リリース直前には可能な限りプログラム修正を避けるのがシステム開発の定石です。つまりリリース直前に性能評価を実施するということは、問題の対応策としてハードウェア増設以外の有効な選択肢がそもそも少ないといえます。そのためにも、早め早めの性能評価にはとても効果があります。その前に、コーディング規約を守り、おかしな実装をしない事はさらに重要です。
【ポイント2】 評価条件をよく考えよう
対象:評価条件の見える化
工程:設計
性能評価を行う際は、その評価条件で本当に性能要件を確認できるのか、よく検討してください。要件定義工程で性能要件が整理されている事は大前提です。
主な評価条件は、データとシナリオです。データとは、DBに入れておくデータ件数や、入力ファイル/パラメータのことで、シナリオとは、負荷を掛ける場合の業務の混合率や同時アクセス数、バッチ処理との競合の有無などを指します。事例でも挙げましたが、データはできるだけ本番に近いものを利用してください。100万件のデータを扱う処理を10件のデータで性能評価をした場合、問題が検出できないことも多いです。
「それは大変だ」と思いませんか? そのとおりです。しかし、大量試験データはいずれ作らねばならないものですし、一度作ってしまえば、何度も使い回せるのでその後の性能評価が簡単になり、実施のハードルが下がり、性能品質が向上するというオマケも付いてきます。
【ポイント3】 インフラ性能評価をやろう
対象:HW、SW(ミドルウェアまで)性能の見える化
工程:試験
インフラ構築が完了した時点で、ネットワークやOSなど、業務アプリケーションの下にあるインフラ部分の性能を確認するといいです。こうすることで、システム全体の性能評価で問題が発覚した場合に問題切り分け作業が簡単になり、解析に無駄な時間がかかることを防止できます。インフラ構築時に業務アプリケーションが出来上がっていることは稀なので、簡単なサンプルプログラムを用いるだけでも、十分な効果が期待できます。また、この作業により、各種設定ミスの検出とミドルウェアパラメータ設計の妥当性も確認できます。
【ポイント4】 性能設計をしよう
対象:すべて(見える化したものの妥当性を判断するために使う)
工程:設計
いくら見える化を行っても、見たものが良いかどうか判断できなくては意味がありません。性能設計の一環で、そのための基準を作ります。基準とは、性能要件をブレークダウンした性能目標の事です。例えば5秒のレスポンスが必要な処理で100回のSQLが発行されているなら、1SQLの性能目標は50ミリ秒以下にすれば良いです。ポイント(1)〜(3)は、性能設計で決めた目標を、見える化して結果判定をする作業と言えます。
性能設計とは、目標性能と、その目標を実現するための設計です。業務量に応じたサーバサイジング、プロセス構成、業務処理の対象データ件数や処理の多重度などと多岐にわたり、性能マネジメントの中で最も重要な要素の1つといえます。
性能問題防止のポイントは、性能設計をしっかりやって、その内容を早め早めに評価するということといえそうです。
今回は事例を基に、主に開発工程で実施する「見える化」について整理しました。次回は、性能設計の花形であり、かつ、システムの初期投資額に直結する、サーバサイジングの勘所についてご紹介する予定です。
筆者プロフィール

岡安 一将
NTTデータ 基盤システム事業本部所属。Webシステムのインフラ開発に関する技術支援業務を経て、現在は社内外への性能コンサルティングと、性能問題予防のためのサービス展開を担当している。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 初期侵入口は“またVPN” 日本医大武蔵小杉病院にランサムウェア攻撃
- 「2027年1月12日」は運命の日? サポート切れOSを使い続ける会社の末路
- 富士通、ソブリンAIサーバを国内製造開始 自社開発プロセッサー搭載版も
- ホワイトハッカーが明かす「ランサムウェア対策が破られる理由」と本当に効く防御
- Googleが「AI Threat Tracker」レポートを公開 Geminiを標的にした攻撃を確認
- シャドーAIエージェントを検出 Oktaが新機能「Agent Discovery」を発表
- SOMPOグループCEOをAIで再現 本人とのガチンコ対談で見えた「人間の役割」
- 「AI前提」の国家戦略と「思考停止」の現場 大半の企業で“何も起きない”未来を予見
- AIエージェント普及はリスクの転換点 OpenClawを例に防御ポイントを解説
- 生成AIの記憶機能を悪用して特定企業を優遇 50件超の事例を確認
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。