保存版 性能品質の作り方:攻めの性能マネジメント
性能マネージメントの幾つかのアイデアを紹介してきた本連載も、今回が最終回となりました。連載の最後に、性能マネージメントのプロセスを整理し、開発から運用における性能品質確保のベストプラクティスをご紹介したいと思います。
通常の業務アプリケーションと同様、性能品質の作り込みに特効薬はなく、当たり前の作業を当たり前にこなせているかどうかが最も重要です。しかし多くの制約条件により、作業プロセスを教科書通りに実施できることも多くはありません。作業プロセスを効果的に省略しつつ適切なリスク管理ができるかどうか、そこが性能品質に大きく影響を及ぼします。また、要件定義や設計といった上流工程が重要なことも、業務アプリケーションの開発と同様です(第1回「出そうで出ないシステム性能」)。
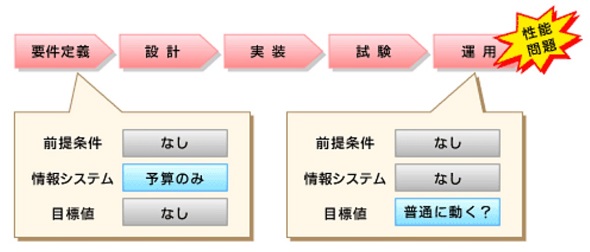 図1 動けばいいのか?
図1 動けばいいのか?性能品質の作り込み
性能品質とは
性能品質のよしあしは、要件定義で抽出された性能要件を満たしているかどうかで判断します。開発フェイズでは、設計、実装、試験を通して性能品質を作り込むプロセスを実施します。確保した品質を前提に、管理とメンテナンスを行うことで、運用フェイズでのSLA(サービス・レベル・アグリーメント) が実現できるのです。
では具体的に何をすればよいのか、前回までの連載の内容を踏まえて整理します。
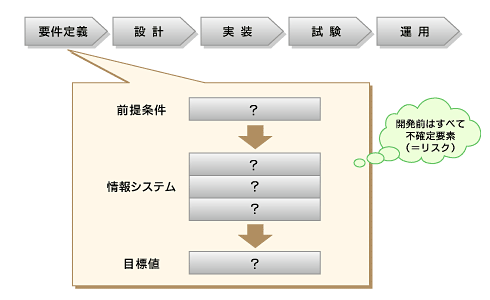 図2 どんな要件があるか
図2 どんな要件があるか要件定義
性能要件とは、システムの目的を達成するために必要な条件であり、前提条件と目標値として整理します。前提条件とは、処理対象となるデータ量や取引数、ユーザー数などがこれに当たります。目標値とは、レスポンスタイム、同時接続ユーザー数、単位時間当たりの取引件数などです。どちらの数値もモニタリング可能な項目(モニタリング可能とは、ログに出力されているか、ツール/コマンドで参照できることです)を選ぶのが性能マネージメントの大前提ですが、大量データの手動解析は運用コスト増に直結するので、できれば市販ツールや自作のスクリプトで、モニタリングと解析の仕組みも用意してください。モニタリングがシステム要件に含まれない場合、残念ながら性能マネージメントが不可能なシステムができあがります。
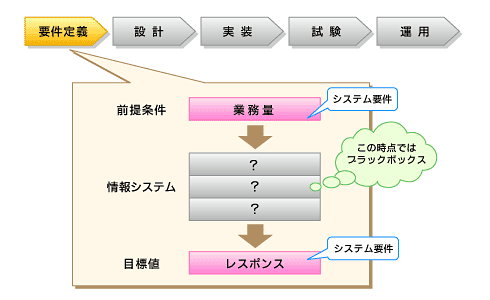 図3 要件を固めていく
図3 要件を固めていく前提条件の整理では、3カ月後まで出ていればいい性能なのか、5年後も維持したい性能なのか、対象とする時期を決めます。すると処理対象データ量もおのずと決まります。スモールスタートだとしても、最大で毎秒5件を処理するのと5万件を処理するのでは、アーキテクチャレベルで異なるシステム構成が必要になるので、運用の途中で簡単に変更できるものではありません。
性能目標の設定は、システムの特性や利用シーンに応じた数値を設定することが大切です。また、性能はコストに応じて向上させることができますが、システムの高速化がビジネスを拡大させるとは限らないので、性能のレベルは投資対効果を考慮してください。
以下に、画面レスポンスの例を挙げます。
・BtoCサイト
サイトの目的である「売り上げ」を確保するためには、適度な速さの画面レスポンスが必要です。レスポンスやアクセス数を管理しておけば、サイトの人気をアピールするために、通常時とイベント開催時の違いを公表するという広告手段も可能となります。
・社内ナレッジ検索システム
社員に余計なストレスをかけない程度ならばOKです。Yahoo! やGoogle、百度に対抗する必要はありません。
・株売買システム
刻々と変わる株価を扱うために、ミリ秒単位のレスポンスが求められます。
設計
性能設計には、大きく分けて以下4つのプロセスが存在しますが、すべての工程で性能を考慮する必要があります。
- 性能要件のブレークダウン
- アーキテクチャ設計
- サーバサイジング
- 業務処理設計
本連載では設計についてはほとんど触れなかったため、ここで詳しく説明します。
* 性能要件のブレークダウン
性能要件のブレークダウンとは、人間用の定義からシステム用の項目と数値に変換する作業です。性能目標として試験時に利用します。繰り返しになりますが、ここで選定する項目はモニタリング可能なものを選んでください。試験は、単機能試験と負荷試験を実施するといいでしょう。単機能試験用には、1つの画面レスポンス、1つのバッチジョブごとに処理時間を決めます。負荷試験用にはレスポンスだけでなく、同時接続端末数やスループット、サーバリソース使用率上限等を決めます。
* インフラアーキテクチャ設計
サーバ/ネットワーク構成、ミドルウェア構成等を、性能特性を考慮して決定する工程であり、ITアーキテクトの腕の見せどころともいえます。設計内容や検討項目は非常に多いのですが、例えば、Webサーバ負荷分散のためにロードバランサを導入する、バッチ処理の負荷がオンライン性能に影響を与えないようにバッチサーバを独立させる、大量同報通信のために通信プロトコルにマルチキャストを利用するなどがあります。ミドルウェア構成は、オンメモリDBの利用やキャッシュサーバの導入などが考えられます。
なお、アーキテクチャ設計は、拡張性や信頼性、コストなどのバランスが重要です。要件定義でも触れましたが、レスポンスの上限や拡張性の上限など、インフラアーキテクチャを選定した時点で基本的な性能特性が決まってしまうので、性能品質確保の非常に重要なプロセスといえます。
* サーバサイジング
詳細は連載第3回「ハード性能以上の性能は出ないんです」をご覧ください。ここでは要点を再掲します。
- 業務要件から性能要件を定義
- 最大負荷条件の抽出
- 想定外への備え
- 複数の情報を組み合わせる
- 幅を持たせて評価する
- 不確定要素の見える化と消し込み
* 業務設計
各業務機能に求められる性能目標を達成できるように、処理設計を行います。ここでは、1つの業務処理内で発行するSQL数、ループ数、処理対象レコード数、など、数を考慮します。数を考慮することで、使用メモリサイズもある程度は見積もりが可能になります。また、手動でもシミュレータでも構いませんので、設計内容は机上見積もりで検証するのが理想です。インデックス設計もお忘れなく。
インフラアーキテクチャ設計と同じく、オンラインかバッチか、非同期処理、ファイル転送など、業務処理のアーキテクチャも性能に大きく影響します。
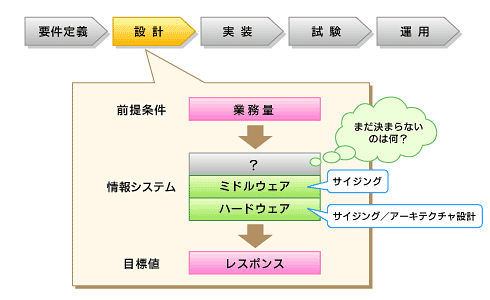 図4 要件を満たす設計書を書く
図4 要件を満たす設計書を書く実装上の注意
実装についてはWeb上に多くの情報があるので、説明は割愛します。JavaでもCでもSQLでも、性能上のアンチパターンにはまらないコーディング規約を作り、それを守ることが重要です。サーバが最新CPUを搭載していようとも、不適切なコーディングでCPUは簡単に食いつぶされるのでご注意ください。また、サーバやミドルウェアの各種パラメータもこの工程で設計します。パラメータは性能評価時にチューニングして決めることもありますが、設計工程で対処しておくと後で楽ができます。
しかし、規約や設計だけでは性能は確保しきれません。設計時の考慮漏れやミドルウェアのバグなど、動かしてみないと性能問題は表面化しないことがあるからです。それを試験で抽出します。
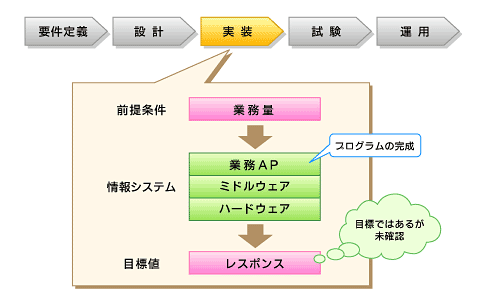 図5 設計書を元に実装作業を行う
図5 設計書を元に実装作業を行う試験
ここも連載第2回「性能問題の失敗事例集」で事例としてご紹介したので、要点だけ再掲します。繰り返しになりますが、データが少ないと表面化しない問題は多いため、データ量は想定量で試験をしてください。また、負荷試験時の負荷生成を人手で行うのは、可能な限り避けるのが無難です。実施調整だけでも大変ですし、何より実施するたびに相当のコストが掛かるため、再試験のハードルが高くなり、機能追加やバグ修正時の性能評価が行われなくなります。
性能が重要なシステムでは、試験の条件もよく考える必要があります。通常の競合パターンだけでなく、どこまでレアケースを想定するか、異常系を考慮するかどうかで、試験に掛かる期間やコストが変わります。
- インフラ性能評価をやろう
- データだけは準備すべし
- 単機能試験から性能を評価すべし
- 負荷シナリオや業務競合パターンなどの評価条件を考慮すべし
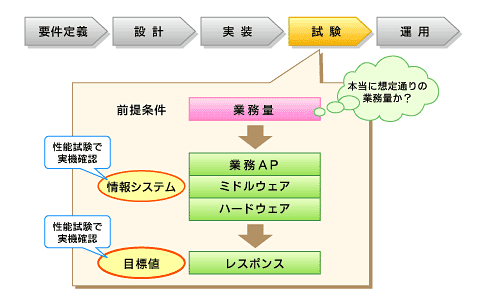 図6 そしてテスト
図6 そしてテスト運用
運用に関しては連載第4回「失敗事例に学ぶ運用性能品質向上策」で紹介したので、要点だけを再掲します。開発したシステムに稼いでもらうためには、運用中の性能問題は避けたいところです。システムは人間や自動車と同じで、使いっぱなしでは壊れて事故を起こします。定期的な診断と予防保守、それを可能にする分析ツールを導入して、安全に使いたいものです。問題が発生しなければ、第5回「システムは変化し続ける??キャパシティプランニング」でご紹介したキャパシティプランニングが運用時のメイン作業となります。
- リスク管理(リスク識別、分析、対応計画)
- 性能監視と診断
- 分析の仕組み
ITILでも提唱されているサービスレベル監視を実現するにも、大前提となるのがモニタリングです。安定運用を実現するために、モニタリング項目と閾(しきい)値は適切に設定することが大切です。
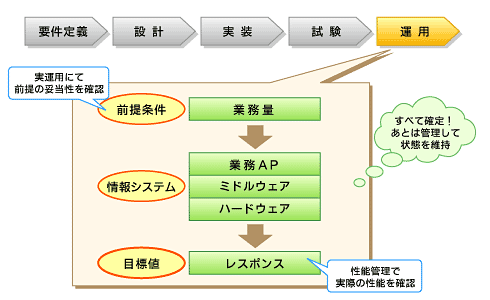 図7 運用しながら性能を確認
図7 運用しながら性能を確認現場での考え方
要件定義から運用工程まで、性能品質確保のベストプラクティスをご紹介しましたが、これはあくまで1つの例にすぎません。では、実際の開発現場では、どのような考え方で性能を扱えばよいでしょう? 私は、次の3つのキーワードを考慮すればそこそこの品質が確保できると考えています。
- 負荷特性の把握
- 処理量の把握
- モニタリング
この3つを整理することでリスク(=不確定要素)が見えてくるので、システムの現状をある程度は見える化することができるでしょう。皆さんの現場でも、まずはできるところから性能マネージメントに着手してはいかがでしょうか。
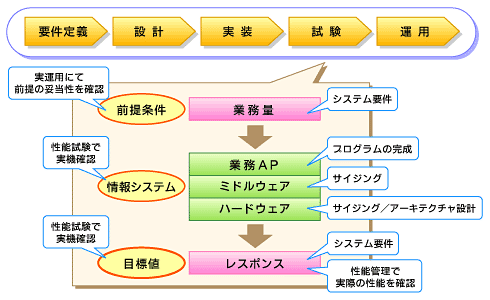 図8 性能マネージメント全体の俯瞰(ふかん)図
図8 性能マネージメント全体の俯瞰(ふかん)図これからの性能
連載初回に「性能は管理されていないことが問題ではないか?」という1つの問題提起をしましたが、読者の皆さんの中でその回答は見つかったでしょうか? 私はこの連載中にも何件かの性能問題に遭遇しましたが、性能マネージメントを実施しているシステムは皆無でした。0%という数字はやはり無視できないと、あらためて感じました。
ハードウェアは速くなりましたが扱うデータも大きくなっているので、安心はできません。そしてSaaSや2.0系技術によりシステム構成はさらに複雑さを増し、性能問題の原因切り分けはますます困難になっています。しかし、管理下においてシステムを制御可能にしておけば、問題対応はもちろん、問題になる前に対処することも可能です。攻めの性能マネージメントで、情報システムの付加価値向上と、現場の皆さんへの安心した睡眠が約束されることを願っています。
筆者プロフィール
岡安 一将
NTTデータ
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。