「Transformerの最大475倍」 富士通、GPUを効率的に使うLLMアーキテクチャ「PHOTON」開発
富士通は6月24日、大規模言語モデル(LLM)を少ないGPUで動かせる新アーキテクチャ「PHOTON」(フォトン)を開発したと発表した。GPU当たりの処理性能(スループット)が、現在のLLMで主流のアーキテクチャ「Transformer」の最大475倍に達するという。LLMの運用に必要なGPUを抑え、大幅なコスト削減につなげられるとしている。
 GPU当たりの処理性能がTransformerに比べ最大475倍という、富士通のLLMアーキテクチャ「PHOTON」
GPU当たりの処理性能がTransformerに比べ最大475倍という、富士通のLLMアーキテクチャ「PHOTON」
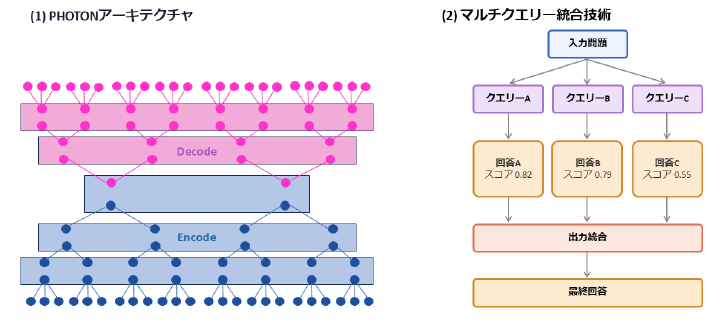
「PHOTON」は「Parallel Hierarchical Operation for TOp-down Networks」(トップダウンネットワークのための並列階層オペレーション)の略。複数の入出力をやりとりするマルチエージェントのような処理を、低コストで効率よくこなせるのが特徴という。
近年のLLMは、推論時に長く・多く“考えさせる”ほど性能が上がることが分かってきており、長文を扱う場面や、多数のユーザーが同時に利用する場面が増えている。一方で、こうした処理は過去のやりとりを保持するためのメモリアクセスが増え、処理速度が落ちやすい。
PHOTONはこの課題を2つの仕組みで解決するとしている。
一つは、文章を“意味のまとまり”単位で階層的に処理する点だ。Transformerは文章を「トークン」(数文字程度の単位。概ね単語)に分解し、トークン同士の関係をすべて計算する。PHOTONは、文章を意味のかたまりとして捉えて階層的に処理することで計算量を抑える。複数の文章をまとめて扱うことで、GPU当たり最大475倍の計算効率を発揮するという。
もう一つが「マルチクエリー統合技術」だ。同じ問題に対し、少しずつ異なる複数の問いや回答候補を作り、多数決や最良の候補を選ぶ形で結果を束ねる。これにより、1回の推論でより安定した高い性能を得られるとしている。
実験では、6億・9億・12億パラメータの3種類のモデルで、Transformerよりメモリ使用量を抑えつつ高いスループットを達成。特に12億パラメータのモデルでは、わずかな性能低下と引き換えに、Transformerの約475倍のマルチクエリー処理能力を実現したという。1回の生成に使うKVキャッシュが小さく、同じGPUメモリでも複数の生成を並列に走らせられる点も利点で、検証では9つのクエリーを束ねるだけで従来のTransformerと同水準の性能に届いたとしている。
富士通はこの成果を、7月2日から米サンディエゴで開かれる自然言語処理分野のトップ会議「ACL 2026」のオーラルセッションで発表する予定。
Copyright © ITmedia, Inc. All Rights Reserved.
本記事は制作段階でChatGPT等の生成系AIサービスを利用していますが、文責は編集部に帰属します。
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
2
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
3
国産AI「Sakana Fugu」なぜドル建て? 円建てニーズ「受け止める」とSakana AI
-
4
AmazonはNVIDIAに挑戦状を突きつけるのか
-
5
「夏場は50度以上のコンテナで作業」に対処 サンワサプライが西日本で荷降ろしロボット活用
-
6
Anthropic、Slackで「@Claude」を呼べる「Claude Tag」提供──チームの一員として非同期でタスク遂行
-
7
ループエンジニアリングとは? チャットとAIコーディングの往復から卒業する新しい開発スタイル
-
8
「最初は壊れ過ぎてビビった」──1220億円投じたソフトバンク「AIスパコン」、それでもNVIDIAのGPUを選ぶワケ
-
9
ダイハツがAI品質検査システムを共同開発、アルミ加工穴内部の目視検査を自動化
-
10
AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR