Google「Gemini」の画像生成がハイレベルと話題に チャット1つで写真のアングルを違和感なく変更
米Googleの大規模言語モデル「Gemini 2.0 Flash」が、3月12日(現地時間)に画像生成に対応した。テキストに加え画像の入力が可能で、例えば「この画像のアングルを変えて」「この画像に日本語で文字入れして」という指示にも対応する。XなどのSNSでは、出力物の精度の高さに感心する声が相次いでいる。
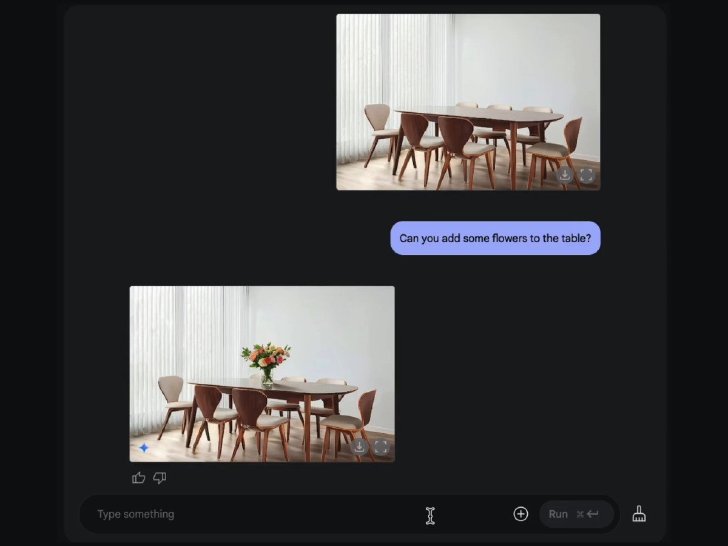 チャットで画像修正(画像はGoogle公式ブログより)
チャットで画像修正(画像はGoogle公式ブログより)
リリース後から、Xではこの画像生成機能を試したユーザーの投稿が続出。画像内の物体の削除/追加やカラーリング、背景の変更などがチャットによる短い指示でできたとの報告が出ている。他にも正面を向いている人物を横から映すといったカメラアングルの移動や、画像内に日本語を正確に入力ができたとする投稿も。その手軽さと性能から「衝撃的」「マンガ制作に使えるのでは」などの意見も見られる。
記者が試したところ、画像内の物体の削除や日本語の追加といった編集が、チャットの指示でできた。カメラアングルの変更も、ゆがみが生じるケースもあったが、大幅な移動に成功。加えて、ラーメンの器を空にした後、器の底に日本語を印刷するといった編集もできた。
 画像内の物体を削除
画像内の物体を削除
 アングルの変更
アングルの変更
 アングル変更の失敗例
アングル変更の失敗例
 日本語の追加
日本語の追加
Gemini 2.0 Flashの画像生成機能は、開発者向けにリリースしたもので、正式版ではない。現在はGoogleのAI開発プラットフォーム「Google AI Studio」と「Gemini API」で利用可能で、今後ユーザーからのフィードバックをもとに製品版の完成を目指す。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」「Mythos 5」全面停止 米政府の指令により Anthropicは早期復旧を宣言
-
2
最新AI「Fable 5」でYouTube動画作ってみた 想像以上の出来に驚愕、ただし大きな弱点も
-
3
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想
-
4
トヨタが抜かれる日――キオクシア首位奪取、2005年「時価総額トップ10」を振り返る
-
5
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
-
6
「もはや宗教」のClaudeに焦るOpenAI 流出メモが暴いた覇権交代のリアル
-
7
「猫も杓子もAI」な現状は今後も続くのか?【後編】AI時代に必要な3つの検討事項
-
8
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
-
9
「日本がいないと成り立たない」世界へ、フィジカルAIが導く独自の交渉力
-
10
JASRAC、「AI作曲・人間作詞」の曲は管理します――「人間の創作的寄与の有無」で線引き
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR