日本語スパムへ一石を投じる「日本SpamAssassinユーザ会」設立:スパム対策最前線
ベイズ理論に基づいた処理でスパム排除を行うオープンソースソフトウェアのSpamAssassin。米国発のOSSで2バイトコードのスパムへ効果的に対処すべく、日本でもユーザー会が発足された。ユーザー会代表で久保氏によるコラムをお送りする。
スパムを取り巻く状況は変化しつつある
スパム(Spam)とは、「受取人の同意なく一方的に送り付けられる商業宣伝メール」などと定義されており、日本では「迷惑メール」と表記されることも多い。しかし、単に不愉快、かつ迷惑というひと言では片付けられず、次のような問題点からも、有害だと考えられる。
- スパムと正規のメール選別に時間がかかる。
- 大切なメールまで間違えて排除する可能性があり、信用にかかわるトラブルを引き起こす場合がある。
- スパイウェアなどの有害なプログラムを受け取ってしまう可能性がある。
- フィッシング詐欺、架空請求の被害に巻き込まれることがある。
- 多数のスパムを一度に送りつけられた場合、ネットワークやメールシステムのパフォーマンスが低下する。
このような背景から、スパムを日本語で言い表すならば、「迷惑メール」ではなく「有害メール」とでも呼ぶべきだろう。
そのスパム、特にスパムメールについては、従来まで英語、中国語、韓国語のものがほとんどだった。普段は日本語メールしかやり取りしない人にとっては、比較的選別が簡単であり、それほど大きな問題ではなかったかもしれない。また、スパムが送りつけられる人も比較的少数だったため、筆者の場合、スパム対策の必要性を強調しても「スパムなんてほとんど届いていないから」と言われることが多かった。
しかし一昨年頃からは、飛躍的に日本語のスパムが増え始めたと感じている。メールの件名だけでは判断できないようなスパムも多い。さらに最近では、従来までスパムを受け取っていなかった人にもスパムが届き始めた。例えば、名前と社員番号を組み合わせたようなメールアドレスにもスパムが届いている被害も聞く。スパマー(スパムを送信する業者など)のメールアドレス収集方法も「進化」しており、ボットやスパイウェアが仕込まれたPCのアドレス帳が収集されているのかもしれない。
このように、われわれを取り巻くスパムの状況が変わりつつあり、特に日本語スパムへの対策を強化する必要が高まっているのだ。
SpamAssassinは日本語スパムに対して不十分だった
SpamAssassin(スパムアサシン)とは、スパムと正規のメールを選別するオープンソースのソフトウェアであり、Apacheライセンスで公開されている。その実力は特に海外で高く評価されており、Datamationの「Product of the Year」(スパム対策ソフト部門)を2年連続で受賞しているほどだ。
また、LinuxやほかのUNIX系OSだけでなくWindows Serverもサポートされており、SendmailやPostfixなどメールサーバとの組み合わせにも柔軟さがある。また、外部スパムデータベースの参照、スパム特有のキーワード、メールの特徴、ベイズフィルタの判定結果などを点数化して総合点判断ができるため、運用者がチューニングしやすいという特徴も挙げられる。
ベイズフィルタ(ベイジアンフィルタ)とは、これまでに受け取ったスパムと正規メールを学習しておき、新着メールがスパムである確率を計算するプログラム(処理実装)である。
処理内容は、まず、メールのヘッダや本文を単語に分割し、個々の単語がスパム、正規メールに出現する頻度をデータベースに登録しておく。チェックしたい新着メールも単語に分割した上でデータベースと比較し、スパムの可能性を計算する。学習度が高まるほど精度も高まるため、最近ではクライアントPCのメールソフトにも「迷惑メールフィルタ」などという名称で搭載されている。
しかし、公式には米国発のSpamAssassinは日本語に対応していなかった。日本語メールは慣習としてJISコードを使うが、最近ではUNICODE系のUTF-8を使ったメールも存在する。また、スパムはかなりの比率でシフトJISコードを使っているという統計もある。日本語メールでスパムかどうかを判断するためには、このような背景から複数の文字コードを統一的に扱える仕組みが必要だ。しかし、現在のSpamAssassinには文字コードを統一する仕組みが備わっていないという課題があった。また、単語に分割する際にも、欧米言語はスペースや記号で区切ればよいが、日本語では「わかち書き」のような特別な前処理が必要なのも複雑にしているものの一つだ。
このため、ベイズフィルタに登録される単語はほとんどが意味のないものになっており、さらにキーワードを登録する際にもJISコード用、シフトJIS用と文字コードごとに記述する必要があった。
日本語を理解するようSpamAssassinを改良する動き
筆者は、日本語スパムへの対応を強化したいと思ってWebなどで状況を調べていたところ、文字コードを統一して扱えるようにするプログラムがSpamAssassin開発グループ内で提案されていたことを知った。しかし、このプログラム内容は、バラバラな文字コードをSpamAssassin内部でUTF-8に統一する、という処理だけであり、わかち書きやその結果に基づく単語分割などの課題は含まれていなかった。このため、課題となっていた足りない部分を加えてSpamAssassinが日本語を正しく判断できるように改良をしてみたのだ。
この改良により、キーワードに関するルールを内部コード(UTF-8)で記述すればよく、日本語の単語がベイズデータベースに正しく登録されるなどの成果が得られた。特に正規メールに対するベイズフィルタの判断結果は劇的に変わった。つまり、従来のロジックでは、正規メールもかなり高いスパム誤判定確率を持っていたのだが、改良後は0から50パーセント程度に収束するようになった(比較試験結果グラフ)。この結果、正規メールがスパムと判断されてしまうという、最も困ってしまう判断ミスが大幅に減少している。
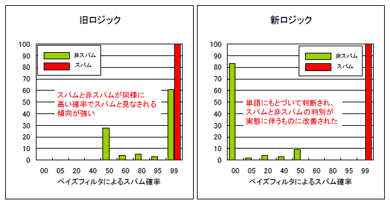 図■スパム判定率の向上度合い
図■スパム判定率の向上度合いしかし、現在のところ従来バージョンとの互換性や、日本語処理を強化したことによって他言語の処理パフォーマンスなどに悪影響が出ないよう配慮をすべき課題も残っている。一方、現在の改良案レベルのものであっても、従来よりもルールを整備しやすくなるメリットも欠かせない。このため、日本語スパムに対して強力な特効薬となり得る拡張だと考えている。そこで、筆者は改良案を公開するとともに「日本SpamAssassinユーザ会」の設立を提案することにした。
「日本SpamAssassinユーザ会」設立へ向けて
従来からあったSpamAssassinのメーリングリスト上で「ユーザー会を作りませんか?」という呼び掛けに対し、何名かの賛同をいただくことができた。なお、ユーザー会の設立については、3月18日にミーティングが行われ、約20名程度の参加を得て正式に発足された。まだサイトも開設されたばかりの状態であるが、既にMLでパッチ改良案も提案されており、少しずつ動き始めたところだ。
このユーザー会の活動を通じて、SpamAssassinに関する情報をWebサイトなどで紹介するだけでなく、日本語スパムに対応するためのプログラム開発やルールセットの整備などを進めていきたいと考えている。
関連記事
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 日本通運×アクセンチュアの124億円訴訟に学ぶ、なぜ大規模開発は“燃える”のか
- Google アカウントに「自撮り」認証が追加 AIによる偽動画に耐えられるか?
- WordPressの脆弱性「wp2shell」 古いバージョンでも自動更新していても安心できない理由
- Windows 11、Dell製PCの不具合を修正する緊急パッチを配信 自動配信の条件と手動の導入手順は?
- 「SIer丸投げ」からどう脱却する? “非ITエンジニア9割”でシステム刷新に挑んだJFEスチールに学ぶ
- 「Windows+R」は絶対に押さないで! 2026年Q1「Microsoft」記事トップ10
- ChatGPTの会話を盗むGoogle Chromeの拡張機能――90万DLの裏にあった手口
- IT部門のための「バイブコーディング統制術」 現場の工夫を殺さず組織を守るにはどうすべき?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- AIエージェントと共に働くリスクとは? PwCが説く「実践的ガバナンス」から考察
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。