話題のSOAについて考える : その1 SOAって、ナンだろう?:エヴァンジェリスト・コラム(2/2 ページ)
代理コードとは何か
さて、次に代理コードについて説明しましょう。先ほどの<プログラムコード1>を、<ソースコード2>のように書き換えてみます。

重要なことは、先ほどと違い、左側のプログラムは中央のコードを経由して右側のコードを呼び出している、ということです。この中央のコードが、代理コード(プロキシ)です。
代理コードを仲介させる目的は、結合方法(バインド方法=バインディング)を変更しやすくするということです。
先ほどのadd2zipはデータベースを使う関数ですから、中央に「郵便番号データベース」が存在し、集中管理したほうがよいというアイデアが浮かんだとします。この時、関数を「中央のコンピュータで稼働させておく」場合、どのようにすべきでしょう
今日では、ネットワークの先にあるプログラムコードを結合(バインド)する方法はたくさんあります。シリアル・パラレル・インターフェイス、ネットワークパイプ、IPソケットなどのレガシーな方法、EDI技術、EAI技術、ファイル転送などの汎用的な方法、DCERPC、CORBA、Java-RMI、EJB、COM/DCOMなどの分散オブジェクト、Web サービスなどです。
これらの技術を使うためのミドルウェアやライブラリも複数ありますが、それぞれコーディング方法が違います。しかも多くの技術は、ネットワークに流すデータを自分のプログラムコードで組み立てる(マーシャリングする)必要があります。
<ソースコード1>のようなコードだと、分散した時に使ったコードをアプリケーション中に書き込む必要があります。しかし、一度書き込んでしまうとその技術や分散した相手側のシステムの技術に依存したソフトウェアコードなってしまいます。
どんな技術を使って呼び出すとしても、ある特定のインターフェイス(add2zipなど)にアクセスするなら、呼び出し側(コンシューマ)は同じプログラミングで済ませられるようにするため、プロキシが存在します。
技術に依存したプログラムコードはプロキシに書き込みます。そうすることでアプリケーションコードはそのときの結合技術(多くの場合ネットワークプロトコル)に依存しないプログラムになるのです。
インターフェイス情報と記述言語
さて、ネットワークプロトコルに依存するコードをプロキシに書くことで、アプリケーションコード(コンシューマ)がネットワークプロトコルに依存しないことが分かりました。ですが、これではコード量が増えるだけで、あまり効率的な作業はできません。
しかし、ここで重要なのは「プロキシ(スタブ)コードは自動生成できる」という点です。
先ほど列挙したレガシーな分散技術のいくつかは、プロキシ(スタブ)を利用します。これらの言語は「インターフェイス定義言語(IDL)」という技術を使ってプロキシ(スタブ)を自動生成します。そのため、ネットワークにアクセスして関数名、引数、戻り値などをやりとりするためのプログラムコードをコーディングする必要はありません(図2)。
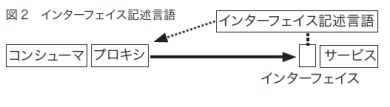
SOAを採用する上で重要な点は、記述言語で表現可能なインターフェイスを持ち、無理なくインターフェイスを定義言語で定義するということです。バイナリフォーマットのEDI、EAI、ファイル転送などの多くに、今日の定義言語は対応できていません。
さて、今回の解説をまとめると、以下のようになります。
SOAは、「呼び出し可能」な、そして「記述可能」な「インターフェイス」を持った「関数」を「稼働させて」おき、外部のプログラム(コンシューマ)から「プロキシ」を経由して「呼び出す」ソフトウェア構造です。プロキシは「記述言語」を利用して自動生成できます。
今回はソフトウェアの作り方がSOAであるということがどういうことか、とても細かい部分でお話をしてみました。「そういう構造のことを指しているということは分かった。でもどうしてこんなに騒がれているの?」と疑問に思われたことでしょう。次回は、SOAを実現するために今日使われるようになったいくつかの技術、そしてそれらを使うことによって得られる効果について解説します。
Copyright© 2010 ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。