オルタナブログでまとめサイト:まとめサイト2.0(3/3 ページ)
<item rdf:about="http://blogs.itmedia.co.jp/knowledge/2007/12/post_57d6.html?ref=rssall">
<title>[定点観測]実名ブログ界の動向 2007年11月版〜年間通じてアクセスを集める凄いオルタナ・ブロガー</title>
<link>http://blogs.itmedia.co.jp/knowledge/2007/12/post_57d6.html?ref=rssall</link>
<description> このところ忙しくてデータ分析が遅れてしまったが、11月分の実名ブログの動向レポ...</description>
…略…
</item>
上記リスト内のように、「titleに記事のタイトル」「linkに記事のURL」が含まれている。よって、次のようにループ処理すれば、すべての記事タイトルと記事のURLが取得できる。
foreach my $item (@{$rss->{'items'}})
{
print $item->{'title'} . '\n';
print $item->{'link'} . '\n';
}
正規表現でスクレイピングする
このように、XML::RSSモジュールを使うことで、RSSに含まれる、すべての記事のタイトルやリンクを取得できる。
リンクが分かったところで、実際に投稿をたどり、その記事に含まれている「コメント数を抜き出す」という一種のスクレイピング処理をしてみよう。
HTMLの特徴を見極める
今回、例としてとりあげているのは、オルタナティブ・ブログのRSSだ。このコンテンツの特徴を見てみよう。
オルタナティブブログのそれぞれの記事には、図1へ示すように、「コメント数(n)」という項目があることが分かる(nは半角整数)。そこで今回は、この「n」の部分を抜き出し、コメント数としてカウントした。
コンテンツのHTMLソースを見ると、該当個所は、次のように構成されていることが分かる。
<a class="comment" href="http://blogs.itmedia.co.jp/knowledge/2007/11/post_0c91.html#comments">コメント (6)</a>
hrefの部分はコンテンツごとに異なるが、どのコンテンツも、「<a class="comment">コメント (n)</a>」という書式だ。そこで、この「括弧内の数(上記の例では6)」は、次の正規表現で取得できる。
/<a class="comment"[^>]+>\s*コメント\s*\((\d+)\)\s*<\/a>/
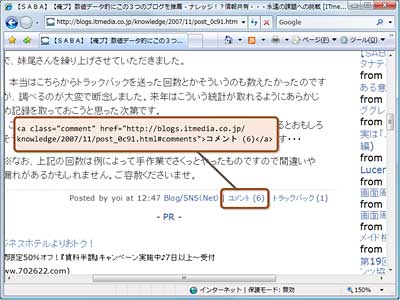 図1■ITmediaオルタナティブブログの「コメント数」の部分
図1■ITmediaオルタナティブブログの「コメント数」の部分コメント数ごとに並び替えて出力する
実際に、RSSに含まれている記事をたどり、上記の正規表現を使ってコメントを取得、そしてコメントが多い順に並べて出力するというスクリプトは、リスト1のようになる。
リスト1■コメント数の多い順に並べる
my @commentlist = ();
foreach my $item (@{$rss->{'items'}})
{
my %data;
$data{'title'} = $item->{'title'};
$data{'link'} = $item->{'link'};
# リンク先のデータを取得
# (前回のgetWebContent関数を利用)
my ($hrefcontent, $lastupdate) =
getWebContent($data{'link'}, undef);
#コメントの数を取得
if ($hrefcontent)
{
if ($hrefcontent =~
m/<a class="comment"[^>]+>\s*コメント\s*\((\d+)\)\s*<\/a>/)
{
$data{'count'} = int($1);
}
else
{
print "コメント数が見つかりません\n";
}
}
push @commentlist, \%data;
}
# 並べ替え
@commentlist =
sort {$b->{'count'} <=> $a->{'count'} }
@commentlist;
# HTMLとして出力
print "<ul>";
foreach my $comment (@commentlist)
{
printf "<li>コメント数 %d : <a href='%s'>%s</a></li>",
$comment->{'count'}, $comment->{'link'},
$comment->{'title'};
}
print "</ul>";
リスト1の出力結果は、例えば次のようになる。
<ul>
<li>コメント数 1 : <a href='http://blogs.itmedia.co.jp/kyoko/2007/12/post_6171.html?ref=rssall'>大成功のマーケティング?</a></li>
<li>コメント数 0 : <a href='http://blogs.itmedia.co.jp/serial/2007/12/95_cd38.html?ref=rssall'>中央官庁の9時5時には年収で報いるべき</a></li>
…略…
</ul>
ここでは単純に、<ul><li>を使ってリスト表示にしているだけだが、表形式にするとか、もう少し見やすい形式に加工するのは、読者にお任せしたい。
今回は、正規表現を用いてスクレイピングしてみたのだが、いかがだっただろうか。前述のリストに示したように、「特定の文字列の並びから、特定の文字だけを抜き取る」という処理ならば、正規表現を使って容易にスクレイピングできる。しかし、もしこれが、「コメント数 (n)」という表記がなく、実際に「コメントとして付け加えられた数を把握する」場合は、どうだろうか?
ソースを見ると分かるが、オルタナティブ・ブログの場合、実際のコメント部では次のようなHTMLになっている。
<ul class="individual_box_list">
<a id="c2541041"></a>
<li><a rel="nofollow" target="_blank" title="http://blogs.itmedia.co.jp/torapapa" href="http://app.blogs.itmedia.co.jp/t/comments?__mode=red&user_id=77444&id=2541041">トラパパ</a> <span style="font-size:x-small;">at 2007/11/30 15:39</span><br>
<p>そーなんですか、3位タイとは惜しかったデス・・・</p>
</ul>
<ul class="individual_box_list">
<a id="c2541213"></a>
<li><a rel="nofollow" target="_blank" title="http://blogs.itmedia.co.jp/tooki/" href="http://app.blogs.itmedia.co.jp/t/comments?__mode=red&user_id=77444&id=2541213">ooki</a> <span style="font-size:x-small;">at 2007/11/30 16:48</span><br>
<p>コメントでランキング、というのは面白いですね。<br />
まぁ、しっかし色々と中途半端ですね、我ながら。。。。(汗<br />
</p>
</ul>
〜以下、略〜
この「<ul class="individual_box_list">の数を数え上げる」とか、「<ul class="individual_box_list">の中身を抜き出す」といった話になると、正規表現を考えるのが、とたんに難しくなる。
そのような複雑なスクレイピングでは、やはりスクレイピング用のライブラリを使うのが得策だ。次回は、ライブラリを使ったスクレイピングを説明する予定だ。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 日本通運×アクセンチュアの124億円訴訟に学ぶ、なぜ大規模開発は“燃える”のか
- WordPressの脆弱性「wp2shell」 古いバージョンでも自動更新していても安心できない理由
- Google アカウントに「自撮り」認証が追加 AIによる偽動画に耐えられるか?
- 「SIer丸投げ」からどう脱却する? “非ITエンジニア9割”でシステム刷新に挑んだJFEスチールに学ぶ
- Windows 11、Dell製PCの不具合を修正する緊急パッチを配信 自動配信の条件と手動の導入手順は?
- ChatGPTの会話を盗むGoogle Chromeの拡張機能――90万DLの裏にあった手口
- 「Windows+R」は絶対に押さないで! 2026年Q1「Microsoft」記事トップ10
- IT部門のための「バイブコーディング統制術」 現場の工夫を殺さず組織を守るにはどうすべき?
- 「フロンティアAI」の脅威にどう立ち向かう? Gartnerが次世代セキュリティを提言
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。