多角的に情報を“追跡”、企業における情報活用の質を高めよ:情報の流れを可視化
全社の情報を統合管理するためには、各部門で異なる意味で使われている用語の再定義やシステムの現状把握、次世代の情報基盤の設計、データのマッピングなど、さまざまな作業が不可欠である。しかし、これらの作業が統合されていないと、データ品質が低い「使えないDWH」ができてしまう。これらの作業を統合することにより高いデータ品質を保てる情報連携基盤として、日本IBMが提供しているのが「IBM InfoSphere Information Server」である。
次世代の統合管理基盤に求められる“要件”
市場が成熟して他社との差別化がますます難しくなりつつある中で、情報活用を通じた新たな活路の開拓が多くの企業に強く求められている。そのことは、CIO(最高情報責任者)の8割以上が企業の競争力向上策に「BI(ビジネスインテリジェンス)と分析」を挙げていることからも明らかだ(「IBM Global CIO Study 2009」の調査結果より)。
そのために不可欠なのが、社内のさまざまなシステムで分散管理されている情報を統合するための基盤の整備だ。その実現を通じて、多様な分析作業に迅速に乗り出すとともに、変化をいち早くとらえて他社との差別化を講じることが可能になる。では、そのためにはどのような点に配慮すべきなのだろうか。
 日本IBM ソフトウェア事業インフォメーション・マネジメント 第二クライアント・テクニカルプロフェッショナルズ IT Specialistの河田 大氏
日本IBM ソフトウェア事業インフォメーション・マネジメント 第二クライアント・テクニカルプロフェッショナルズ IT Specialistの河田 大氏これまで多くの企業で情報活用のためのデータウェアハウス(DWH)が構築されてきた。しかし、DWHに取り込まれる情報の信頼性が低ければ、情報活用が奏功する可能性もそれだけ低下せざるを得ない。こうした事態を回避するためには、信頼できる情報をDWHに提供する仕組みをつくることが重要である。
また、分析精度の向上やコンプライアンスの強化を図るためには、情報をよりきめ細かく管理する必要があり、大量の情報を扱うための高い処理能力も不可欠だ。日本IBM ソフトウェア事業 インフォメーション・マネジメント 第二クライアント・テクニカルプロフェッショナルズ IT Specialistの河田 大氏は、「リスク計算やトランザクション分析などは高い精度が求められるのが当たり前になっており、細かい粒度の大量データの分析が求められるのが、昨今の情報系システムの要件です。大量の情報を短期間に収集し処理できるシステムが、企業の事業継続には不可欠になってきています」と強調する。さらに、企業のコスト意識が高まる中で、データ統合作業の効率化につながる何らかの方策も求められる。
これらの「情報の信頼性」、「大量データ処理」、「作業効率化」の要求を満たした情報基盤の整備を支援すべく、日本IBMが提供しているのが、情報の「収集」、「理解」、「クレンジング」、「収集と配布」といった情報統合の各プロセスに不可欠な機能を備えた情報統合基盤製品群「IBM InfoSphere Information Server」である。
多様なコンポーネントでプロジェクトを支援
情報統合の実現に向けたプロジェクトは全社を横断する一大プロジェクトに位置付けられる。プロジェクトの過程では、部署ごとに異なる認識で使われている用語の再定義やシステムの現状把握、次世代の情報基盤の設計、データのマッピングなど膨大な作業が発生する。
情報統合の必要性は、かねてから多くの企業で認識されてきた。だが、こうしたプロジェクトの困難さが、情報統合の成功を阻んできたのが現状だ。人海戦術でプロジェクトに着手した企業もあったものの、データの品質維持の負担の大きさに耐えかね、結局DWHはつくったものの、データの信頼性が低く使いにくいため活用はできていないというケースも少なくない。
InfoSphere Information Serverの特徴は、情報統合におけるこれらの課題解決を支援するために、情報統合の各プロセスに対応した多様なコンポーネントが、プロセスの効率化に直結する機能を提供する点にある。ひいては、工数を大幅に低減し、プロジェクトに必要とされるコストも抑えられるわけだ。
では、各コンポーネントの役割と機能について、プロジェクトの流れにのっとりそれぞれ概観していこう。
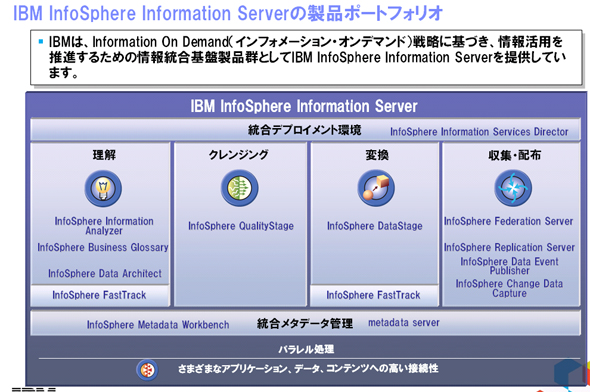 「IBM InfoSphere Information Server」の製品ポートフォリオ
「IBM InfoSphere Information Server」の製品ポートフォリオプロジェクトでまず実施すべきは、各部署で異なる意味で使われている用語の共通化である。社内での用語認識のズレが情報の品質を低下させるので、用語の再定義は不可欠である。そのために用意されているのが、企業内の用語を登録、管理、共有するための辞書ツール「IBM InfoSphere Business Glossary」である。用語の名称やカテゴリなどを子細に登録することで認識を社内で共有するほか、関連するIT資産なども登録することで、用語に関連するサブシステムを容易に特定することが可能となる。
次に実施されるのが、各データベースに格納されたデータの解析作業だ。一般にデータは、システムごとに統一されたコード体系とルールにのっとって管理されるが、運用の過程ではイレギュラーなデータが発生することも少なくない。万一、そのことを放置してプロジェクトを進めた場合には、統合後の情報の信頼性が低く、活用できないものになる。
しかし、分析ツール「IBM InfoSphere Information Analyzer」を利用すれば、リレーショナル・データベースやフラット・ファイルの解析を通じ、さまざまなシステムのデータ構造やデータの分布状況、コード運用の順守度を、人手をかけることなく迅速に調査できるほか、問題の早期発見も可能になる。
「業務上、例外的な入力が行われていることは珍しいことではありません。InfoSphere Information Analyzerによりデータの列分析を行えば、それらのイレギュラーなデータを容易にあぶりだすことが可能になります。標準形式を定義して違反している行と値のレポートも行えるため、運用開始後のルール徹底にも用いることができます」(河田氏)
現状の環境を把握した上で、新たな情報基盤の設計段階で活用を見込めるのが「IBM InfoSphere Data Architect」である。同コンポーネントはリレーショナル・データベースのデータモデル設計支援ツールに位置付けられ、これによりDWHのモデリングが容易に行えるようになる。また、データに関連するドキュメントが存在するものの、その信頼性が低い場合には、リバースエンジニアリングにより既存システムの定義をモデルとして取り込むこともできる。
既存のデータの特性が分かり、新規のデータモデルが決まれば、それをマッピングしていくのが次の工程になる。前工程で定義したビジネス用語や分析したデータ分布を確認しながら、このマッピングを行うツールとして「IBM InfoSphere FastTrack」がある。
パラレル処理により高速かつ大量なデータ処理を実現
以上の工程を経て、データ統合の“肝”とも呼ぶべき大量のデータを処理/変換するために用いるのが、ETLツールの「IBM InfoSphere DataStage」だ。その特徴としてまず挙げられるのは、多種多様なデータの収集から統合までの一連の変換処理内容をGUIで容易に定義できる点である。専門的な知識が乏しくても高品質かつ効率的な変換処理の開発が行える。頻繁に実施する加工処理はあらかじめ部品で用意しているため大変効率が高い。
さらに、同時並行でいくつもの処理を行うパラレル処理によって、高速かつ大量のデータ処理を実現する。一般的なETLツールで同様の処理を行うためには、ユーザー自らが各種の設定を個別に行う必要があり、それは決して簡単なことではなかった。だが、「InfoSphere DataStageであれば、パラメータの設定によりパラレル処理数を容易に指定できます。加えて、ハードウェアの追加によっても処理能力をリニアに高められるスケーラビリティがあり、データの増大やリアルタイム性に対する要求にも柔軟に応えられことが大きな特徴の一つです」と河田氏は話す。
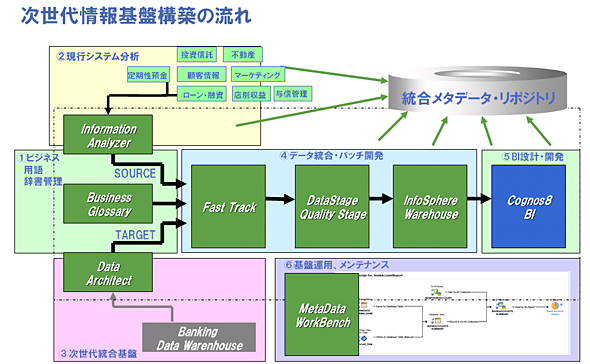 次世代情報基盤構築の流れ
次世代情報基盤構築の流れシステムからレポートまでの情報の遷移をメタデータで把握
さらに、InfoSphere Information Serverで特筆されるのが、単に情報を統合するだけでなく、各プロセスで定義されたビジネス用語、データの分析結果、データモデル、マッピング情報といった“データについてのデータ”をメタデータとして横断検索できる「IBM InfoSphere Metadata Workbench」によって、情報が格納されているシステムからDWH、レポートまでのデータの流れを可視化した点にある。つまり、下流から上流へ、逆に上流から下流へと情報の流れを容易に追跡できるわけだ。
その結果、例えばレポートからDWH、さらに基幹システムへと情報を遡って調査することで、分析方法やデータの加工方法、データソースを検証でき、レポートの信ぴょう性を確認することが可能になる。その作業を通じて情報の信頼性が担保されていれば、外部からの急な監査要求などにも迅速に対応できる。
また、基幹システムのデータベースからレポートへとデータの流れを追うことで、システムの仕様変更に伴う影響範囲を特定でき、変更方法の検討にも役立てられる。
「下流から上流へ情報の流れをたどれば、データソースが正確かどうかなどの検証作業も容易になります。Metadata Workbenchがあれば、あらゆる段階にあるデータの品質を検証できる仕組みを実現することができます」(河田氏)
InfoSphere Information Serverで提供されるコンポーネントは、これら以外にもクレンジングを行う「IBM InfoSphere QualityStage」や変更データの収集を行う「IBM InfoSphere Change Data Capture」などさまざまだ。このことからも、情報統合に必要とされるあらゆる機能が一気通貫で提供されることが理解できよう。
「コンポーネント群を利用しつつ情報基盤を整備することで、ユーザーに正確な情報を提供できるとともに、メタデータによって絶えず情報を見直し、情報の品質を高く維持することも可能となります。メタデータからシステム全体の情報の流れを把握して開発にあたることで、高い生産性や総コストの圧縮も見込むことができます」(河田氏)
DWHをより短期間に構築するため、設計に用いるデータモデルを提供するなど、日本IBMは企業の情報統合に向けた支援にも余念がない。InfoSphere Information Serverは、企業の長年の課題であった情報統合に取り組む企業にとって、待望の“解”であることに間違いないだろう。
この記事に興味のある方におすすめのホワイトペーパー
IBM InfoSphere Information Server は、データのプロファイリング、クレンジング、変換、提供など、統合処理に関わるさまざまな機能を1つに集約させた情報統合基盤である。異種混在のIT環境においても、複雑なデータ統合処理を円滑かつ低コストで実現し、企業内の情報資産をビジネスの現場で最大限活用できるようにする。
| ホワイトペーパーのダウンロードページへ (TechTargetジャパン) |
IBM InfoSphere DataStageは、ソース、ターゲット、時間などの制約に関係なくあらゆるタイプのエンタープライズ・データを緊密に統合する。データウェアハウス(DWH)を実現するETLソリューションをご紹介したい。
| ホワイトペーパーのダウンロードページへ (TechTargetジャパン) |
Copyright © ITmedia, Inc. All Rights Reserved.
提供:日本アイ・ビー・エム株式会社
アイティメディア営業企画/制作:ITmedia エンタープライズ編集部/掲載内容有効期限:2011年9月30日
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- AIは本当に「考えている」のか Apple論文が問いかけた推論モデルの限界とその行方
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。