2017年の問題に? 匿名化した個人情報が特定されるリスクを自動評価する技術
改正個人情報保護法で匿名化した個人情報の活用が可能になるが、対応によっては個人特定されるリスクを伴う。このリスクを評価する技術を富士通研究所が開発した。
富士通研究所は7月19日、パーソナルデータに関するプライバシーリスクの自動評価技術を開発したと発表した。2017年中に施行予定の改正個人情報保護法では本人の同意がなくとも匿名加工によってパーソナルデータの第三者提供が可能になり、新技術で情報活用を支援するのが狙い。
匿名化したパーソナルデータは、医療分野などを中心に新しいサービス・製品の品質向上につながると期待される。改正法に基づくガイドラインが策定されれば、医療機関で保有する健診データなどを匿名にするなど加工して、研究機関や製薬会社などで活用することなどが想定されている。
ただし、匿名加工されたデータを提供するには、提供元が事前にガイドラインとの適合や個人特定リスク評価を行う必要があり、専門家による審査に多くの日数を要するなどの課題があった。海外では、医療機関のデータを匿名化して医療研究に利用するために、半年以上掛かったという例もあるという。
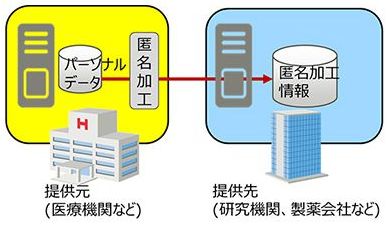 改正個人情報保護法での匿名加工情報の第三者による利活用イメージ(出典:富士通研究所)
改正個人情報保護法での匿名加工情報の第三者による利活用イメージ(出典:富士通研究所)富士通研究所が今回開発した技術は、データの分布に基づいて、最も個人を特定しやすい属性の組み合わせとその特定のしやすさを、現実的な時間内で自動的に探索するもの。
匿名加工データから個人が特定されるリスクの評価と対策をスピーディーに実行するためには、個人を最も特定しやすい属性を探索し、その上で適切な匿名化手法を適用することが重要になる。しかし、性別、電話番号、住所など最も特定しやすい属性の組み合わせの計算量は膨大で、現実的な時間での探索が困難だった。

新技術では、14の属性と1万人のデータに対しても3分以内で自動的にリスクを評価する。データ分布に基づいたリスク評価を行うため、属性値の価値の重さを定義した辞書などは不要だという。
同技術の根幹となるのは、「個人特定可能な属性の組み合わせを効率的に探索する技術」と「個人データの特定しやすさを定量化する技術」の2つ。個人特定可能な属性の組み合わせを効率的に探索する技術では、特定しやすい属性の組み合わせを探索する際の無駄な探索を省略する。例えば、年齢と職業だけで特定できるレコードは、年齢と職業と本籍でも特定できることから、本籍についての探索は省く。
また、個人データの特定のしやすさを定量化する技術では、データの中で最も個人を特定しやすい属性の組み合わせを分析し、その容易度を定量化する。定量化には、日本ネットワークセキュリティ協会の情報価値算定モデルに基づいて算定。これにより、優先的に匿名化すべき属性がすぐに分かり、加工も迅速化するという。

富士通研究所では、今回開発技術以外にデータが漏えいした際の想定損害賠償額の算出や、各種匿名化ガイドラインへの適合性を判定する技術も開発している。今後は実環境での効果を検証し、2017年度をめどに実用化していく予定だ。
今回開発された技術が実用化されれば、これまでプライバシーの問題から、複数機関で自由に共有できなかった膨大なビッグデータを分析し、新薬開発や予防医療などにさらに生かせる可能性が広がる。また、今後他の分野での活用も期待される。
関連記事
 健康・医療分野におけるビッグデータイノベーションの動向
健康・医療分野におけるビッグデータイノベーションの動向
健康医療はビッグデータ利活用への期待が高い反面、厳格な法規制の下で情報セキュリティのリスクも高い。日本では医療介護データの有効活用によって医療費削減を図る方針が打ち出されたばかりだが、先行する米国はどのような形で取り組んでいるのだろうか。- パーソナルデータのプライバシーを高速に保護する新技術、NECが開発
NECは、医療情報や健康情報、生活情報や位置情報など様々なパーソナルデータをより高度に匿名化する技術を開発した。  「パーソナルデータ」の利活用に何が必要か?
「パーソナルデータ」の利活用に何が必要か?
2015年に予定される個人情報保護法改正に関連して、政府では「パーソナルデータ」の利活用に向けた制度の整備が検討されている。6月に示された大綱での課題などについて、「パーソナルデータに関する検討会技術検討WG」メンバーでパブリックコメントを提出した日本HPに話を聞いた。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 「英数・記号の混在」はもう古い NISTが禁じたパスワード慣行と組織のリアル
- メルカリ「CTOがCHROを兼務」が示すもの AI時代の組織設計と“形だけの模倣”に潜むリスク
- NEC社長が説く“SIerの勝者の条件” 2026年度の国内IT需要の行方
- 「会話がスマホに盗聴されている」の真相 スマホセキュリティで守るべきルールとは?
- SCS評価制度が描くサプライチェーンセキュリティの全体像:4つのメッセージが示す企業単体を超えたリスク管理の基軸
- フィッシングメールの“最先端”はAI偽装 攻撃者が愛用する「おとり」に異変
- AIで思考力が奪われる? 世界の研究が警告するAIバカの壁【動画あり】
- Anthropic、Mythos級モデルにおいて30日間のデータ保持方針を導入 安全対策用途に限定し学習には不使用
- 「AI単独の導入は“失敗のレシピ”だ」 ServiceNowの製品トップが語る、企業AIの盲点
- 「DX銘柄2026」事例レポート公開 51社のAI活用事例を掲載
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。