ERP、SCM、CRMの次に打つべき“一手”−データ活用がビジネスを変える−:情報マネジメント 提言
ERPやSCM、CRMなどのビジネスアプリケーション導入は一巡した。ただし、これらのアプリケーションを導入しただけでは経営は変わらない。次の一手として来るビジネスITは何か? 情報マネージャに次の道しるべを示す。
ERP、SCMやCRMなどのビジネスプロセスを施行するためのシステムは、企業が業務を遂行する上で当然必要となるインフラである。あって当たり前である。ところが、これらのシステムから発生するデータの活用について考える企業は意外に少ない。
「ITを経営に生かす」ということは、単にビジネスプロセスをシステムによって自動化するだけではない。そこからいかに経営に必要な“知恵”を獲得するかということだ。経営に必要な“知恵”、すなわちインテリジェンスを獲得するためのヒントがここにある。
基幹系システムの再構築によるプロセス変革
多くの大手企業では、基幹系システムの再構築プロジェクトを通じて、ビジネスプロセスの変革を推進している。この潮流は今や中堅企業にも及んできている。
そして、この基幹系システム再構築プロジェクトが採用しているシステム構築方法の多くは、オープン系のアプリケーション・パッケージの採用である。国内におけるERP(Enterprise Resource Planning)パッケージの導入は、1990年代前半のメインフレームからオープンシステム化への流れ、1990年代後半のY2K問題対策の追い風に乗って急速に普及した。
片やSCM(Supply Chain Management)パッケージは、資材の所要量を計画するMRP(Material Requirement Planning)に代わるスケジューリングによって工場内物流をシステム化することからスタートした。そしてインバウンドの資材調達から、アウトバウンドの製品物流における輸・配送を最適化するスケジューリング、さらには需要予測(SCP:Supply Chain Planning)までをカバーしている。また、一企業内のサプライチェーンの最適化のみならず、バリューチェーンを構成する企業間のサプライチェーンの最適化までを視野に入れている。
そして、顧客との直接の接点を持つフロントオフィスアプリケーションであるCRM(Customer Relationship Management)パッケージが、営業支援システムであるSFA(Sales Force Automation)から顧客サポートのためのコールセンター、フィールドサービスまでをシステム化し、さらにはセグメンテーションやパーソナライゼーションによるOne to Oneマーケティングを実現するに至っている。
このERP、SCM、CRMの各パッケージを組み合わせて、計画→調達→生産→販売→物流→アフターフォローといった企業のすべての業務プロセスをカバーできるようになった(図1参照)。
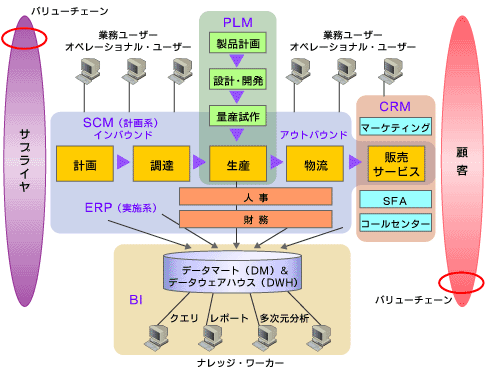 図1 業務プロセスの自動化とデータの活用
図1 業務プロセスの自動化とデータの活用何がERPで何がSCMか?
ERPはバックオフィスの業務を守備範囲とし、CRMはフロントオフィス業務をカバーしていることから、ERPとCRMの違いは分かりやすい。
ところが、ERPとSCMの違いとなると、何がどう違うのか混乱している人も多い。どちらも、生産・販売・物流といったバックオフィス系アプリケーションを守備範囲としているからである。その違いを一言でいうと、SCMが「計画系」でERPが「実施系」といえる。
計画系と実施系という性格の違いから、本社サイドではSCMプロジェクトを推進し、事業部サイド(工場サイド)ではERPプロジェクトの推進を担当するケースが多い。そして各プロジェクトは、その業務範囲の広さやパッケージソフトの膨大さから、2?3年間にわたり数百人がかかわる大プロジェクトになり、IT予算の大半が費やされているといっても過言ではない。
これらのプロジェクトが始まったきっかけは、各社まちまちであろう。しかしその共通の目的はビジネスプロセスの見直しと業務の再構築である。在庫を減らし、サイクルタイムを短縮し、顧客に価値を提供するためには、プロセスを簡素化し、自動化し、供給パイプラインを短くしなければならない。
プロセス変革の次に来るものはBIの活用
ERPやSCMのパッケージは、ビジネスプロセスの自動化や最適化には向いている。しかし各プロセスで発生するデータを、情報やナレッジとして活用することは守備範囲外だ。またERPやSCMのプロジェクトにかかわる人々は、長期にわたる導入作業に疲弊し、もはやデータを情報として活用することを考える余裕すらない。データ活用のためのシステム化に新たな人材や予算が付かないケースも多い。だが、情報化時代のエクセレント・カンパニーとして勝ち組になるためには、プロセスの自動化や最適化だけでは不十分だ。各ビジネスプロセスで発生し、蓄積されたデータを情報やインテリジェンスとして活用することが大変重要なキーとなる。
過去の労働集約的な企業の経営管理では、従業員を「労働力」としてマネジメントしてきた。今日の企業の経営管理では「知力」としてマネジメントしなければならない。
「労働力」のマネジメントを重要な経営課題として論じたテーラーの「科学的管理法」が発表されたのは100年も前のことである。いまや従業員の頭数で企業力を測ることはできない(表1参照)。
| 工業化社会 | 情報化社会 | |
|---|---|---|
| マーケット | ベンダ主導 | カスタマーエコノミー |
| 経営管理項目 | 労働力 | 知力 |
| システム化対象 | 業務プロセス自動化 | データ活用 |
| システム | OLTP | BI |
| 表1 IT活用領域の変化 | ||
ものを作ったり、売ったり、運んだりはどこの会社でもやっている。休眠会社でない限り、作ったり、売ったり、運んだりする企業活動を通じて付加価値を付け、利益を上げている。問題は「どうしたらもっと良いものを安く作れるか」「どうしたらもっとたくさん売れるか」「どうしたらもっと早く運べるか」「どうしたらもっと顧客満足を得られるか」??この「どうしたら」を考えることが「知力」であり、競争優位のポイントでもある。
ビジネスプロセス再構築とナレッジプロセスの構築
「どうしたら」は知ることから始まる。
- 提供する製品やサービスの評価を知る
- 自社の顧客を知る
- 再構築した内部プロセスのパフォーマンスと改善点を知る
- 業務プロセス遂行の結果としての財務的業績を知る
「知ること」はデータから始まる。データは企業内のどこかにたくさんある。データは活用しなければ、ただのデータのままだ。データは活用されて初めて企業活動全体を可視化する「情報」となり、情報は分析されて「ナレッジ」になり、ナレッジは「どうしたら」を教えてくれる。
このデータの蓄積からナレッジ獲得までのプロセスを「ナレッジプロセス」と呼ぶことにする。一般的にはナレッジ・マネジメント(KM:Knowledge Management)という概念があるが、KMでは経験とか知識の共有が中心のテーマとなる。ここでは、この知識を獲得するプロセスを問題にしたい。
基幹系業務プロセスのシステム化の次に必要なものは、情報系のナレッジプロセスのシステム化だ。この重要なナレッジプロセスのシステム化のためには、ビジネス・インテリジェンス(BI:Business Intelligence)ツールが必要となる。BIツールにはETL(Extract Transformation&Load)、データマート(DM:Data Mart)、データウェアハウス(DWH:Data WareHouse)、クエリ/レポーティング/多次元分析ツールなどが含まれる(図2参照)。
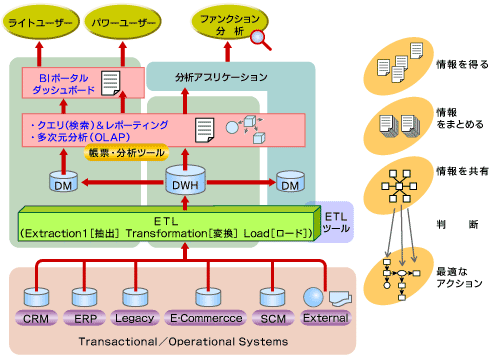 図2 BIの構成要素
図2 BIの構成要素だが、「無料だから」「OSを買ったら箱に入っていたから」という理由で、基幹系パッケージやOSのユーザライセンスに含まれるBIツールを採用している企業が多いのには驚かされる。もっともこのような企業では、これらのツールがナレッジプロセスとしてではなく、単なる定型のレポーティング・ツールとしてしか生かされていないのも事実だ。
情報系システム導入検討チームの挫折
いま、ナレッジプロセスを構築するためにBIツールの役割や機能を調査・検討すると、代表的適用例や機能としてまず浮かび上がるのが、「意思決定支援システム」(DSS:Decision Support System)と「データマイニング」だ。
ところが、こうした理想的かつ高度なナレッジ活用方法から情報系システムの導入を検討していくと、必ずぶつかる壁がある。「果たして、当社の経営者はデータを活用した意思決定を行うのであろうか?」という疑問や、「社内にはデータマイニングできるような高度な数学モデルを理解できる人間はいない」といった壁だ。この壁を突破しない限り、BIツール導入の予算化もあり得ないことに思い当たる。
既存の基幹系システムでも、そこそこの問い合わせはできるし、ほとんどの場合は基幹系システムから定期的に出力されるレポート類で事足りる。共有すべき情報があれば、新たにレポートの作成を基幹系システムに要求すれば済む。大抵のビジネス上の疑問に対する答えは基幹系システムから得られそうだし、BIツールを駆使してしか答えが得られないようなビジネス・クエッションはなかなか思い付かない。
ましてや基幹系とは異なり、在庫の削減やリードタイムの短縮といった定量的効果を表現しにくい情報系への新たな投資は上申し難いのが通例である。そして情報系システムの必要性を漠然とは感じながらも、論理的に説明できない担当チームは、導入に挫折してしまう。チームが挫折するのは勝手だが、大変な迷惑を被るのは企業そのものであり、その責任は重いことを自覚すべきである。
基幹系システムと情報系システムの役割分担
システムは、高度な使い方から理解しようとするよりも、シンプルに考える方が分かりやすい。そこで、基幹系システムから情報系システムが分離独立していった歴史を考えてみよう。
●役割分担その(1)−クエリ−
基幹系システムでトランザクションを処理していくと、データが記録として残される。このデータを集計したレポート類がバッチ処理で出力される。さらに、「ある製品の在庫残高は?」「ある顧客からの受注は出荷されたのか?」「今月の売り上げ実績は?」といったリアルタイムな単純クエリが基幹系システムによって効率よく処理される。
次に、この基幹系システムのユーザーが要求するものは、「ある製品の1週間後の在庫残高は?」「出荷プライオリティーが1番高い受注残は?」「過去5年分の全支店の製品別売り上げ実績は?」といった高度で複雑な問い合わせである。これらの質問に答えるには、予測や全件検索や複数システムにまたがる履歴データの検索が必要となる。
基幹系システムにとっては高度で複雑な問い合わせでも、これらは何も特別に特殊なビジネス・クエッションではない。DSSやデータマイニングほどでなくても、このくらいの問い合わせは日常業務の中でよく発生する。
また企業の中には、レベルの異なる2種類の意思決定がある。1つは経営陣が下す戦略的で重大な判断。もう1つは、通常の従業員が日常業務の中で行う無数の判断である。後者は戦略的判断というよりも「戦術的判断」であるが、これらの細かな戦術的判断の積み重ねが企業の業績を大きく左右する。
●役割分担その(2)−生データの履歴での保管−
こうしたユーザーの要求に応えるために、基幹系システムに5年分の履歴データを残したり、すべてのテーブルに検索を掛けたり、多くのテーブルをジョインしたりする、高度で複雑なクエリを許すべきだろうか?
企業の全システムの効率を考えた場合、答えは「否」である。
基幹系はトランザクションの高速処理に特化させ、ここで発生したトランザクション・データは別のシステムに移す方が効率的である。データを蓄える専用システムは専用であるから、データは生のまま履歴で保持することが可能になる。生データの履歴にアクセスできる環境が整うと、ドリルダウンができるようになる。また多次元分析やOLAPのような多面的な問い合わせや、複数のテーブルをジョインする複雑クエリも、DSSやデータマイニングも可能になる。
そこで登場するのが情報系のデータウェアハウスだ。複数の基幹系システムで発生したすべてのデータを独立した情報系データベースに定期的に移し、さらに必要な年数分だけの明細データを履歴で保持する。このデータベースに、全件検索や複数テーブルのジョインが発生しても基幹系のトランザクション処理のレスポンスに影響を与えることはまったくない。基幹系システムと情報系システムの役割分担である。
とはいえ、すべてのクエリ業務が情報系のデータウェアハウスに移管されるわけではない。「現在の売り上げは?」「残高は?」といったリアルタイムなクエリは、基幹系システムの役割である。
●役割分担その(3)−レポート−
ではレポート類はどうか? もともとレポートはバッチで処理される。従って、そのデータもバッチで集計されていれば十分である。
レポート出力はシステム資源をそこそこ消費するので、システム全体のパフォーマンスを低下させる。とすれば、定期レポートであれ非定期レポートであれ、すべてのレポート出力業務は基幹系システムから外して、情報系のデータウェアハウスに移す方が得策である。ただし、定型レポート作成自体がデータウェアハウスを導入する目的であると誤解すべきではない(図3参照)。
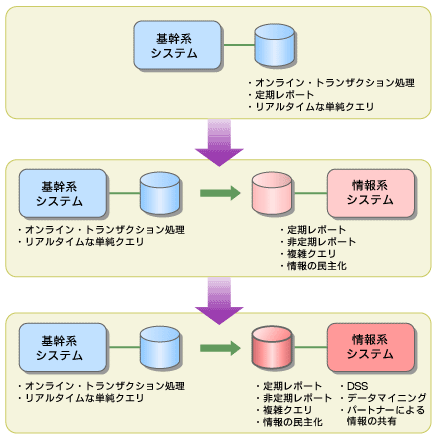 図3 基幹系システムと情報系システムの役割分担
図3 基幹系システムと情報系システムの役割分担社内情報の民主化とインテリジェント化
さらに、データは会社のどこかに存在しているものの、それが数多くの異なるシステムにまたがって分散しているため、結局必要としている人の手に入らないのが通常である。
この場合の言い訳として登場するのは、「全情報に全社員がアクセスしてよいのか」「財務的データは一部の人だけに開放されるべき」といったような議論である。このような機密保持を理由に、社員がデータに自由にアクセスできない、あるいは欲しいデータがどこにあるのか分からない状態が放置されることがよくある。
会社の財務状況を社員に見られてしまうといった問題はセキュリティで解決すべき問題であって、こんな目先のデメリットを考えるよりは、すべてのデータを開放し、ここをアクセスすれば必要なデータは必ず見つかるといった環境を用意し、誰にでも使いやすいクエリ/レポーティング/多次元分析ツールを整備し、全従業員の「知力」を向上させる情報の民主化を考えるべきである。(了)
著者紹介
▼著者名 泉谷 章(いずみたに あきら)
日本ビジネスオブジェクツ株式会社 第二営業本部 本部長
1970年早稲田大学政治経済学部卒。日本ユニシスでMRP/CIM/ERPの商品企画、開発、マーケッティング、コンサルティングを長年経験し、三井物産にてERPパッケージ「SYMIX」(現MAPIX)や、CRMパッケージ「Vantive」(現PeoplSoft CRM)などのソリューションプロダクトの発掘と国内ビジネス立ち上げに従事。その後、アナリティカルCRMやデータウェアハウスのTeradataのビジネスに従事し、現在に至る。
著書に「One to One CRM戦略」(日刊工業新聞社)(共著)等がある。またBIに関して@ITで連載した記事には「統合CRMを支える情報基盤」がある。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- マクロを使わずにExcelを自動化 ゼロから分かる「パワーピボット」超入門
- シャドーAIに「ログイン情報」を渡している割合は? Oktaの実態調査で判明
- ServiceNowとAccenture、エージェント型AIを全社展開する「FDE」を開始
- 企業の77%がエージェントAIを本番環境に投入、「導入の可否」から「どう選ぶか」の時代へ
- 中小企業の7割がセキュリティに「自信」も、浮き彫りになる“基本対策”の盲点
- Microsoft 365 Copilotが新デザインを発表 ExcelでCopilot利用率が33%増加
- MicrosoftとNVIDIAが次世代PCを発表 1ペタフロップス級の「Windows PC」ができること
- インフラ運用は「人とAIエージェントの共同」へ Ciscoが次世代の統合基盤「Cisco Cloud Control」を公開
- AIで高度化するサイバー攻撃にどう立ち向かう? 各種レポートに見る脅威の現在地とセキュリティの基本
- OpenAI、Anthropicが新会社設立 国内SIerは「黒船襲来」に対抗できるか?
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。