第3回:ハードウェアかOSか、それが問題だ――障害の原因を求めて:障害発生時の金科玉条(3/3 ページ)
リモート管理ソフトウェアによるハードウェアエラーの監視
それでは、リモート管理ソフトウェアによってハードウェアエラーを監視する例をIBM eServer xSeriesとIBM Directorを使って見てみよう。
IBM eServer xSeriesにはBMCが搭載されており、無償で同梱されているIBM Directorという管理ソフトによってリモート監視が行える。また、専用のシステム管理アダプタであるRSA II*を搭載している場合はBMCとRSA II間で通信が行われ、BMCで感知されたエラーはIBM DirectorにRSA IIの管理ポート経由でイベントログとして通知される。RSA IIを搭載していない場合はBMCの管理ポートを利用することで同様にエラーをIBM Directorに通知できる。もちろんこれらの構成では、OSの稼働状況に依存せずにハードウェア監視を行える。さらに、OS上で動作するエージェントと呼ばれるソフトウェアを通じてCPUやメモリ、ディスク使用率などの情報取得やプロセス管理などを行うこともできる。この場合、エージェントとBMC間はインバウンドで通信を行う。
このように、IBM DirectorではBMCからIPMIによって通知されるメッセージを直接もしくはエージェント経由で受け取り、リモートからハードウェアを一元管理できる。PDにおけるハードウェア側からのアプローチでは、このような仕組みも利用することになる。
さて、IBM Directorの機能全般やその詳細な話は今回のテーマとは離れるため割愛するが、IPMIによってどのようなハードウェアエラーを検知できるのか、どうPDに利用できるのか、といったことを幾つか解説していこう。
ファン障害
図4はファン障害に関するエラー通知の例である。画像では確認しづらいかもしれないが、このイベントログでは、以下のような時系列でファンに関するエラーを確認できる。
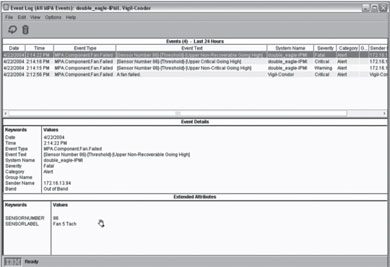 図4 ファン障害の発生例
図4 ファン障害の発生例PM2:12:56 ファンに関する問題があるというアラート通知が入る
PM2:14:15 ファンのセンサー値が「致命的ではないが、注意が必要なレベル」を超える
PM2:14:18 ファンのセンサー値が「致命的なレベル」を超える
PM2:14:22 ファンのセンサー値が「復旧不可能なレベル」を超える
ここで、ファンのセンサー値はCPUファンの回転数を示しており、最終的にファン停止状態となっている。この場合、放置すればCPUが温度上昇によって熱暴走してしまうため、通常は温度センサーが温度の上昇を感知し、システムが自身を停止する動作を行う。この際、LinuxカーネルはNMIハンドラ*によってカーネルパニックを発生させるが、Linuxのログにはファン障害や温度異常を確認できるメッセージなどは記録されない。つまり、Linuxのログだけを頼りにしていたのでは何が問題となったのか解明できないのである。
電圧障害
図5は電圧障害に関するエラー通知である。なお、若干画面の表示形式が変わっているが、表示設定を変更しているだけでインタフェースとしては同じである。
この例では、14:54:30から14:54:52にかけて電圧に関するエラーが発生していることが確認できる。図5では14:54:38に発生した電圧エラーについてその詳細を表示させている。それによると、「SENSORLABEL」が「CPU1 VCore」であることから、CPU1の電源電圧に致命的な問題が発生していることが分かる。

電圧に関する問題としては、システム中の電源モジュール異常がまず思い浮かぶが、まれに電源供給元環境の問題が原因で発生する場合もある。例えば、配電盤からの電圧不足やタコ足配線による電圧の減衰などもその要因となる。
このとき、「電圧不足によってシステムが起動しない」というのであれば現象は明確で分かりやすいが、「電圧不足のためCPUがスペックどおりの周波数で動作しない」といった現象も起こり得る。この場合、発現する現象としては「想定されているパフォーマンスが出ない」といったものになる。このような場合も、Linuxは電圧異常に関するメッセージをログに残さないため原因を解明しづらい。
これらはハードウェアエラー検知に関する例の一部ではあるが「OSだけでは問題の原因が判断できない場合、ハードウェア側からもアプローチを行うことでPDが容易になる」ということを理解していただけると思う。
OS上でのログの記録/確認
IBM Directorでは監視対象システムにIBM Directorエージェントを導入することで、OS上でハードウェアログを記録するSystem Healthという機能が利用できる。これは特定の機種でのみサポートされる機能だが、SNMPトラップ*をログに記録したり、/var/log/messagesにハードウェアエラーイベントを記録できる。これによってOS上からもハードウェアエラーログを確認することが可能となる。また、BMCやIPMIでハンドリングしたエラーをログに記録することもできる。リスト1、2、3はSystem Healthによって記録された電源障害、RAID障害、ファン障害といったログの一例である。
Jul 22 12:52:05 x345-linux Director Agent: PowerSupply device identified as
PowerSupply 1 reports critical state with possible loss of redundancy.
Jul 22 13:50:10 x345-linux Director Agent: ServeRAID: Logical drive is critical:
controller 1, logical drive 1
Jul 22 13:50:15 x345-linux Director Agent: ServeRAID: Defunct drive - I/O
subsystem error: controller 1, channel 1, SCSI ID 0 (FRU Part # 06P5778)
Jul 22 13:59:41 x345-linux Director Agent: Fan Sensor 8 fell below threshold of
664 RPM. The current value is 0 RPM
リスト1の電源障害に関するメッセージでは、パワーサプライ(電源装置)1に障害が発生し、電源の冗長性が失われた状態になっている*ことが分かる。 リスト2のRAID障害に関するメッセージでは、RAID中の論理ドライブ1*にエラーが発生し、コントローラー1、チャネル1、SCSI ID 0*、パーツナンバー06P5778のデバイスで障害が発生したことが分かる。
リスト3のファン障害に関するメッセージでは、ファン回転数がしきい値664RPMを下回る0RPM、つまりファン停止状態となったためメッセージが通知されたことが分かる。
次回は
次回は、今回の内容の延長として、ハードウェアRAIDの監視について触れる。ここでもPDに役立つハードウェア機能を紹介する予定だ。
このページで出てきた専門用語
RSA II
IBM eServer xSeries向けのシステム管理アダプタ。これを追加することでBMCによる監視対象に加えてリモートから電源オン/オフやSNMP対応、Webベースの管理コンソールなど、管理できる項目をステム監視だけでなく運用まで拡張できる。この場合、RSA IIとBMCは補助IPMBと呼ばれる専用バスを通して連携されるため、管理コンソール統一して監視/管理が行える。
NMIハンドラ
NMIを処理する関数Linuxダンプ機能の回で詳細に説明する予定。
SNMPトラップ
ネットワーク上で発生した障害などのイベントを通知するメッセージ。
パワーサプイ(電源装置)1に障害が発生し、電源の冗長性が失われた状態なっている
サーバ製品では電源害に備えるため、複数電源を搭載しているものがある。この例では、2基備えていた電源のうちの1つが故障したという意味。
RAID中の論理ドイブ
RAIDによって仮想的に作られたドライブの1つ目。
コントローラ1、チャネル1、SCSI ID 0
それぞれSCSI接続された機器に付加される識別子。
本記事は、オープンソースマガジン2006年1月号「Linux PD−問題判別脳力養成道場」を再構成したものです。
関連記事
 連載第1回:PD思考法の基礎と情報収集(その1)
連載第1回:PD思考法の基礎と情報収集(その1)
Linux環境で問題が発生した場合、管理者がするべきことは「その原因がどこにあるか」の正確な把握である。今回は、発生した問題に対し原因がどこにあるかを判別するための基本的な考え方と、問題判別に必要な情報収集の基礎について解説しよう。 連載第2回:PD思考法の基礎と情報収集(その2)
連載第2回:PD思考法の基礎と情報収集(その2)
Linux環境で問題が発生した場合、管理者がするべきことは「その原因がどこにあるか」の正確な把握である。今回は、発生した問題に対し原因がどこにあるかを判別するための基本的な考え方と、問題判別に必要な情報収集の基礎について解説しよう。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 管理職なら年収2000万円超え サイバーセキュリティという困難だが“もうかる仕事”
- “生成AI依存”が問題になり始めている 活用できないどころか顧客離れになるかも?
- Microsoft DefenderとKaspersky EDRに“完全解決困難”な脆弱性 マルウェア検出機能を悪用
- 生成AIは2025年には“オワコン”か? 投資の先細りを後押しする「ある問題」
- 投資家たちがセキュリティ人材を“喉から手が出るほどほしい”ワケ
- Javaは他のプログラミング言語と比較してどのくらい危険なのか? Datadog調査
- 江崎グリコ、基幹システムの切り替え失敗によって出荷や業務が一時停止
- 「アダルトビデオが無料です」――IE標的のトロイの木馬に要注意
- ドローンいらず? 飛行動画作成できる「Google Earth Studio」登場
- Microsoft、脆弱性の開示に向けて業界標準の体系を採用 大改革がもたらすメリット
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。