業務を邪魔する“諸悪の根源”は、こうして突き止める:プロが教える業務改善のツボ(2)(1/2 ページ)
業務改善を“決められた期間内で、システマティックに”行うためには、それなりのポイントがある。その柱となるのが「なぜ?」を繰り返して縦方向に原因を追求するアプローチだが、そうした作業の確実性、効率性を向上させるのが今回紹介する「横」方向の原因追究だ。
業務改善において、原因分析・原因究明は重要なステップです。そこで前回は「なぜ」を繰り返すことで、表層的ではない、深いレベルの原因(真因)を突き止め、それを除去することによって、問題の発生、再発を根本から防止できると解説しました。
その際、論理構造を可視化する手法としてロジックツリーを紹介しました。
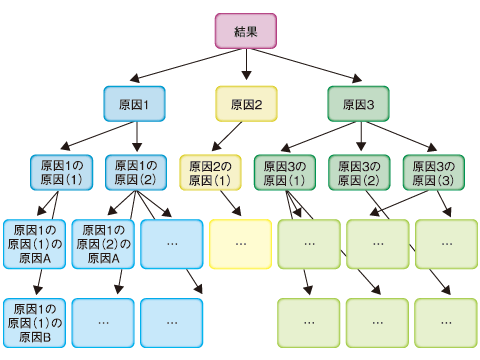 図1 原因分析のロジックツリー。下層になるほど細かな原因が増え、自ずと末広がりの形になる
図1 原因分析のロジックツリー。下層になるほど細かな原因が増え、自ずと末広がりの形になるツリーは1本線で下へとつながっていくのではなく、図1のように、横方向にも広がっていきます。つまり原因の掘り下げ方には「縦(深さ)」と「横(広がり)」という2つのベクトルがあるのです。今回はこのうち横方向の原因追究について解説します。
まずは「原因の所在」を明確化する
では、さっそく本論に入りましょう。「横方向の原因追究」のポイントは全部で3つあります。その1つ目が“原因の所在”を考えることです。縦の原因追究が「なぜ」を考えるのに対して、「横方向の原因追究」の1つ目のポイントはその問題が「どこ」で発生しているのかを考えます。例えば「残業が多い」という問題なら、以下のように考えます。
残業が多いのは、
- 「職階」では部長/課長/主任/一般社員クラスのうち、どの層か?
- 「部門」では製造/管理/営業のうち、どの部門か?
- 「年齢」では若手/中堅/ベテランのうち、どの層か?
問題が起きている対象(この場合は会社組織)を、「職階」「部門」「年齢」といったさまざまな“視点”で区切ったうえで、問題が発生しているのは「どこ」なのか??所在を絞り込むのです。
というのも、所在を絞り込まなければ、「なぜ」だけで原因を掘り下げようとしても、一般論に陥ってしまう可能性があるからです。例えば、ただ漠然と「残業が多い」というだけでは、「なぜ」と考えても「仕事量が多いから」程度のことしか想起できないかもしれません。しかし、「“営業部門の主任の”残業時間が多い」といったように、問題の所在を「部門」と「職階」という“視点”によって、具体的に限定すれば、「担当する顧客数が多いから」といったように、より具体的に問題原因を発見しやすくなるのです。
では、問題の所在を絞り込むための「視点」――先ほどの例で言えば「職階」「部門」「年齢」あるいは「それらの掛け合わせ」など――は、どのように設定すればよいのでしょうか? 無数に考えられる視点の中から、「問題の所在を絞り込むために役立つ視点」をどのように探すのでしょう?
これには以下の4つのステップがあります。
- 考えられる「視点」の候補を挙げ、サンプルデータを見ながら、有効な「視点」の目星を付ける
- 目星を付けた「視点」の中身をMECEに――つまり、漏れやダブりなく展開し、大量データを実際に分析する
- 分析結果を見て、「視点」が合っていたかを検証
- 正しければ、その「視点」を「原因の所在」と考え、ロジックツリーを1段掘り下げる
順に解説しましょう。まずは考えられる「視点」をいくつか挙げてみます。そのうえで、「問題」に関するサンプルデータをそれぞれの視点で分析してみて、データに「偏り」が出るものを探します。例えば、「職階」という視点で切り分けたときに、残業時間がある特定の階層だけに集中している(=偏っている)のであれば、その視点が「探している視点の候補」になります。
「候補」というのは、その視点が本当に「問題の所在を示す視点」かどうかは、サンプルデータではなく、詳細・大量データを実際に当てはめてみて「本当に偏りが出るか」、確かめる必要があるからです。しかし、考えられる視点のすべてについて詳しく調査をしていたら非効率的です。
そこで、まずはサンプルとなるいくらかのデータを眺めて、大まかに偏りが出そうな視点の目星を付ける――すなわち「仮説」を立てるのです。例えば、表1のサンプルデータを見たとき、どんな視点だと偏りが出ると思いますか? 性別や入社年数だと思う人はおそらく少ないはずです。部門別か、職階別だと分かるのではないでしょうか。
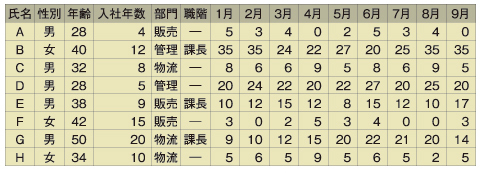 表1 残業時間に関するサンプルデータの一例。こうしたデータを眺めれば、「偏り」が認められそうな「視点」すなわち「原因追究の範囲」の目星を付けることができる
表1 残業時間に関するサンプルデータの一例。こうしたデータを眺めれば、「偏り」が認められそうな「視点」すなわち「原因追究の範囲」の目星を付けることができるこのように、まずはサンプルデータで視点の候補を絞り込んでから、詳細・大量データをその「視点」で分析し、実際に偏りがあるか否かを“検証”します。すなわち「仮説+検証」のスタイルです。
なお、詳細・大量データを分析する際に注意しなければならないのは、各視点において、その中身の要素をMECEに展開する必要がある点です。例えば、「部門」という視点なら「すべての部門」、「職階」なら「すべての職階」に漏れなく、ダブりなく分解してデータを分析します。しかし、例えば「部門別」の視点において、企業によっては「経理部と人事部は管理部門に含まれる」というケースもあります。
この場合、経理部、人事部、管理部門と分けると、データとしてはダブりが発生し、不適切となるので注意が必要です。
こうして「視点」を設定することで、「なぜか?」の前に「どこか?」で原因を掘り下げることができるようになります。そのため、ロジックツリー上では、場合によっては1本線ではなく、複数に枝が分かれていくことになるのです。「残業時間が多い」という例であれば、「部門」という視点ができるため、「管理部の残業時間が多い」「販売部の残業時間が多い」といったように、2つの枝が広がっていくわけです。
手掛かりとなるデータがない場合も多いが、どうすれば?
ただ、実際には、問題が発生した場合、「原因の所在」について仮説を立てるためのサンプルデータがもともと用意されているケースは多くありません。そのような場合に、実際の現場においてどのようにデータを集め、問題の所在を明らかにしていくのか、その要点も挙げておきましょう。
例えば、「納品遅れが続いている」という問題が発生した場合、実際には、複数の納品遅れの事例について、ヒアリングなどにより調査をします。「遅れているのはどの工場からの出荷分か」「どの製品か」「時期はいつか」「どこのお客さま向けなのか」など、考えられるさまざまな点から調査し、集めたデータを表1のようにまとめて、仮説を立てることからスタートします。
ここで偏りが出る視点があれば、さらに事例を増やして詳細に“検証”しますが、いずれの視点でも偏りが出ない場合があります。このときは、最初に調査した視点以外、例えば「遅れているのは何色の製品か」「何曜日か」「どんな天気のときか」など、新たに視点の候補を立てて、再度調査します。
このように、1度の調査ですべての項目を網羅できなかった場合、二度手間、三度手間となることについて「効率が悪い」と感じるかもしれませんが、1度にすべての項目を調査しようとしてヒアリング項目数を多くすると、逆に1つ1つのヒアリング時間が増え、無駄が多くなってしまうので注意が必要です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- NEC社長が説く AI時代と新たな安全保障環境の到来で「ITサービスはこう変わる」
- Googleが警告する「BlackFile」によるMFA突破と組織的恐荒 従業員を「偽サイト」へ誘導する音声詐欺の全貌
- まずは「重要資産の棚卸し」を NISTが示す「個人事業主」レベルの防衛ライン
- Anthropic、中小企業用AI業務支援「Claude for Small Business」発表 15種のAIエージェントが作業を肩代わり
- SAPが「自律型エンタープライズ戦略」を始動 AIエージェントが業務を自動実行する時代へ
- 中小企業の約65%が「情シス不在」 デジタル化でも残る課題との関連は?
- Microsoft、Exchange Serverの重要脆弱性を公表 CISAが悪用を確認
- アクセンチュアがAnthropicとの協業を国内本格化 Claudeを活用した4つの支援領域とは
- AIエージェントなどを活用している企業の8割が「人減らし」 費用対効果に明暗の理由は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。