CEDEC2025
「Confluenceの検索、精度が悪くてRAGに活用しにくい」にどう挑む? Cygamesの試行錯誤
企業が持つ固有のデータを大規模言語モデル(LLM)に参照させることで、ハルシネーションを抑える手法「RAG」(Retrieval-Augmented Generation、検索拡張生成)。さまざまな企業が、自社に蓄積するナレッジを横断して検索できる社内チャットなどで利用したり、それを模索したりしているLLMの活用手法だ。一方、狙い通りハルシネーションを抑えられない、情報の検索がうまくいかないといった悩みも少なからず聞かれる。
「ウマ娘 プリティーダービー」などを手掛けるCygamesもその1社だ。同社は2023年、LLMを活用した社内AIチャット「Taurus」を展開。コラボレーションツール「Confluence」などをデータソースとしたRAG機能も有し、知りたいことがあったときにすぐ検索できるツールとして活用している。
しかし、ConfluenceのAPIで知りたい情報を検索する際には、検索キーワードと文書内の文言が完全一致しないと目的のページへ到達できず、RAGに使ってもユーザーが望む情報に到達しにくい問題があったという。果たして同社はこの問題にどう取り組んだのか──ゲーム開発者向けカンファレンス「CEDEC 2025」の講演で(7月22~24日、パシフィコ横浜)で、同社の笠原達也さん(AIテクノロジー エンジニア)が語った。
どうする? RAGの回答精度向上
Taurusは「GPT-4o」「o4-mini」「o3」「Claude Sonnet 4」などを利用した社内AIチャットで、社内報や社員情報、ソフトウェアの利用可否情報などをConfluenceや社外サイトをデータソースとしてRAGによって検索できる。会話履歴の保存機能やチャットの口調を同社が手掛けるゲームキャラクターのものに変更する機能も搭載。基盤はAWSで、各LLMの呼び出しやその管理には各AIベンダーのAPIや「Amazon Bedrock」「Azure OpenAI Service」といったプラットフォームを活用している。
 システム構成
システム構成
ただ、Confluenceをソースとする際の検索機能には課題があった。Taurusでは、LLMがConfluenceのAPIを呼び出してデータを検索。結果を受け取ったLLMが回答を生成し、ユーザーに提示させる仕組みを採用している。
しかしConfluenceのAPIによる検索は、検索ワードと文書内の文言が完全一致しないと目的のページへ到達できず、適切な回答ができないケースがあった。
例えばユーザーが夏季休暇の時期を知るために「夏休みっていつから?」と質問したとする。それを受けたLLMは「夏休み」を検索ワードとしてConfluenceを検索するが、Confluence内では「夏季休暇」と記載されているため、LLMが情報が存在しないと判断してしまうため、正しく回答できない──といった問題があったという。

試した2つのアプローチ 適していたのは……
そこでCygamesは、まずLLMに複数のワードで検索させることで、正答率の向上を狙うアプローチを試した。例えば夏休みについて検索する際「夏休み」「夏季休暇」「サマー休暇」といったワードを並行して検索させ、それぞれの回答を統合してユーザーに提示するイメージだ。
しかしこのアプローチでは、問題をある程度改善できたものの、根本的な解決には至らなかった。LLMによる検索ワードの生成が安定せず、関係のない情報の回答につながってしまうケースがあったという。
次に同社が試したのは、テキストや画像などのデータを数値ベクトルとして表現し、その類似度を計算することで、関連する情報を見つけ出す「ベクトル検索」という手法だ。Azureのストレージ「Blob Storage」にファイルを格納し、それぞれに数値ベクトルを含めた索引情報を付与。同じくAzureのAI検索サービス「Azure AI Search」による検索を可能にした。
ただ、この方法にも問題があった。このアプローチではConfluenceのページをファイルとして出力し、ストレージに格納の上検索する。Azure AI Searchでは、特定の社員やチームにのみ限定公開されたConfluenceページに対し、認証をパスしての検索ができなかった。
そこで同社は、当初のキーワード検索とベクトル検索を組み合わせることに。全社に公開されているページについてはベクトル検索で、限定公開のページについてはConfluenceのAPIによる検索で対応する形にした。

結果、当初の形式のみの場合と比べ検索精度が改善。社内のユーザーにも試してもらい、アンケートを取ったところ、回答者の半分以上が「検索精度が非常に改善された」「改善された」と答えたという。
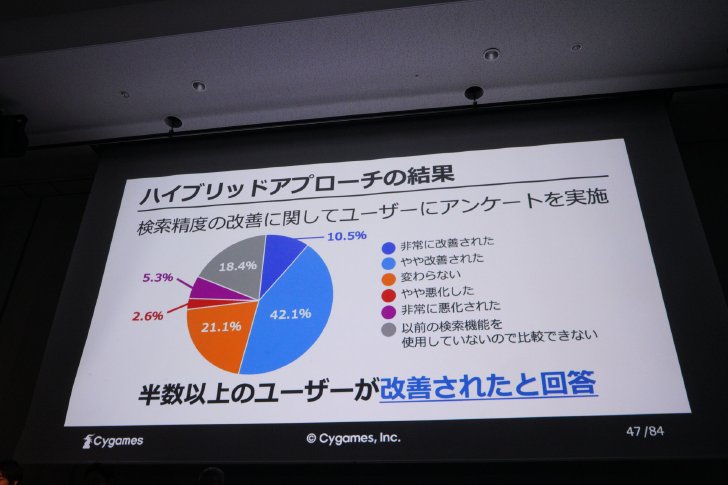
ただ、昨今はLLM自体の検索能力も向上しており、ベクトル検索なしでもRAGの検索精度が良くなっていると笠原さん。とはいえ、検索時間の増大防止やトークン数(おおむね単語数の意。LLMの利用コストにも関係する)の削減、選択できるLLMの多様性を維持する観点から、今後もベクトル検索の併用は必須と考えているという。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
3
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
4
3万円で「Yahoo!ニュース」にPR掲載 プレスリリースをAIで「ニュース風記事」に
-
5
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
6
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
7
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
8
え、21日で37テラも? 高性能SSDを食いつぶす「あのAIツール」にご用心:886th Lap
-
9
日本の「完璧主義」から脱却し中国ヒューマノイドにどう立ち向かうか
-
10
AWSの「静かな」戦略シフト OpenAIとAnthropic“1日違い登壇”の意味を読み解く
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR