Google、拡散型テキスト生成モデル「DiffusionGemma」公開 ローカルGPUで毎秒1000トークン超
米Googleは6月10日(現地時間)、テキスト生成を最大4倍高速化するオープンな実験的AIモデル「DiffusionGemma」を発表した。Apache 2.0ライセンスの下、Hugging Faceで重みを公開しており、誰でもダウンロードして試すことができる。

DiffusionGemmaは、画像生成で広く使われている「diffusion」(拡散)の手法をテキスト生成に応用したモデル。Googleは昨年の「Google I/O」で拡散ベースの言語モデル「Gemini Diffusion」を発表していたが、その後具体的な展開は発表されていなかった。
DiffusionGemmaは、このGemini Diffusionの研究成果をオープンモデルの「Gemma 4」ファミリーに統合したもので、約1年越しに拡散型テキスト生成技術が開発者の手に届く形となった。
現在主流のLLMは、トークンを1つずつ左から右へ順番に生成する「自己回帰型」と呼ばれる仕組みを採用している。DiffusionGemmaはこれとは異なり、ランダムなプレースホルダーから出発して256トークンのブロックを一括で並列生成し、複数回の反復でテキストを洗練していく。双方向のアテンション機構を備えており、生成中にブロック全体を評価して誤りを自己修正できるため、インライン編集やコード補完、マークダウンの整形などの非線形のテキスト生成タスクに強みがあるとGoogleは説明している。この並列処理により、デコードのボトルネックがメモリ帯域幅から演算能力へとシフトし、GPU本来の計算性能を引き出せるようになるという。
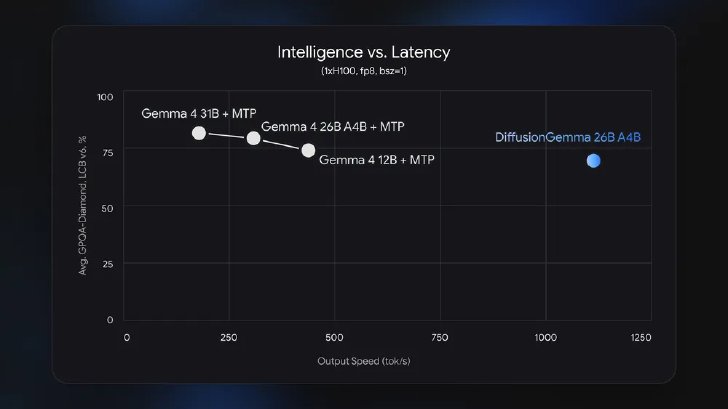
 DiffusionGemmaの知能と遅延の関係を示すグラフ(画像:Google)
DiffusionGemmaの知能と遅延の関係を示すグラフ(画像:Google)
モデルの構造は260億パラメータのMixture of Experts(MoE)で、推論時に実際に活性化するのは38億パラメータのみ。量子化すれば18GBのVRAMに収まるため、ハイエンドのコンシューマー向けGPUでも動作する。ただしGoogleは、DiffusionGemmaの出力品質は標準的なGemma 4よりも低いとしており、最高品質を求める用途には引き続きGemma 4の使用を推奨している。速度優先のモデルであり、ローカルかつ少数ユーザーでの推論でこそ真価を発揮する一方、クラウド上で大量のリクエストをバッチ処理するような高トラフィック環境では自己回帰型モデルの方が効率的な場合があるという。
 DiffusionGemmaと標準Gemma 4のベンチマーク比較(画像:Google)
DiffusionGemmaと標準Gemma 4のベンチマーク比較(画像:Google)
性能面では、米NVIDIAの「H100」単体で毎秒1000トークン以上、コンシューマー向けの「GeForce RTX 5090」で毎秒700トークン以上の生成速度を示している。
NVIDIAも同日、DiffusionGemmaへの初日対応を発表した。NVIDIAはDGX Spark上で毎秒150トークン、DGX Stationではさらに高速な推論が可能だとしており、クラウドに依存せずローカルで高速なAI推論を実現する方向性を強調している。
DiffusionGemmaのモデル重みはHugging Faceからダウンロードでき、vLLM、Hugging Face Transformers、MLX、Unsloth、NVIDIA NeMoなど主要な開発ツールで利用可能だ。Google Cloud Model GardenやNVIDIA NIMを通じたクラウド上での実行にも対応する。Googleは同モデルを「実験的」と位置付けており、対話型のローカルAIシステムにおいて速度を重視する開発者や研究者を主なターゲットとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
2
MicrosoftやNVIDIAなど、AIのオープンウェイト規制に反対する書簡を公開――Anthropicは署名せず
-
3
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
-
4
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
5
スーパーに並んだ「ごちゃごちゃ生成AIポップ」が物議 “看板王”こと、きぬた歯科院長「これはアリ」
-
6
「KPIは睡眠時間」──オードリー・タンに聞く、日本企業の生産性が上がらない根本原因
-
7
「生成AIで仕事が楽に」のはずが……IT現場を蝕む“AI疲れ・AIうつ”の正体
-
8
NEC森田社長が語る「脱・人月商売」の行方 組織の壁を破るAI人材育成法
-
9
Sakana AI、新AIモデル「Namazu」発表 AIチャット「Sakana Chat」も公開
-
10
海外の「Claude」や「GPT」ではダメなのか 日本企業向けai&、そのメリットは?
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR