AIが長時間タスクをこなす性能、想定を超えるスピードで成長 MythosとGPT-5.5がブレークスルーか
AIエージェントが自律的にタスクを処理できる時間が、研究機関の予想を上回る速さで伸びている。複数の第三者機関による最新の評価では、米Anthropicの「Claude Mythos Preview」(以下、Mythos)や米OpenAIの「GPT-5.5」といった最新モデルが既存モデルの性能を大きく上回り、既存の評価環境が測定限界に達しつつあることが明らかになった。
米国の非営利研究機関METRは5月8日(現地時間、以下同)、Mythosの評価結果を公開し、同モデルが50%の確率で完遂できるソフトウェアエンジニアリング、機械学習、サイバーセキュリティに関するタスクの長さ(50%タイムホライズン)を「16時間以上」と算出した。METRは現行の測定に使用しているタスク群では、16時間を超える測定が信頼性に欠けると指摘し、同モデルの能力の上限を正確に評価できていないとした。
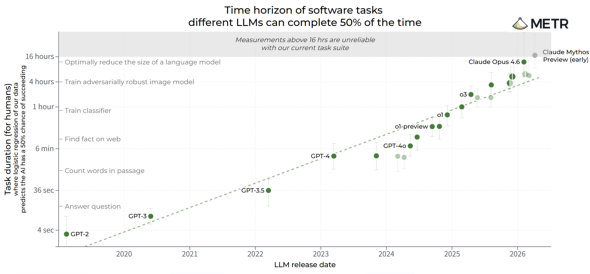 METRによる、ソフトウェア関連タスクの50%タイムホライズン測定結果。Mythosの測定結果(グラフ右上)はグラフの上限値となっている(出典:公式ブログ)
METRによる、ソフトウェア関連タスクの50%タイムホライズン測定結果。Mythosの測定結果(グラフ右上)はグラフの上限値となっている(出典:公式ブログ)
英国の政府機関AI Security Institute(AISI)は2月、AIモデルが80%の確率で完遂できるサイバーセキュリティ関連タスクの長さ(80%タイムホライズン)が2024年後半以降「4.7カ月ごとに倍増」していると推定。これは25年11月時点の試算「8カ月ごと」から大幅に加速している。
しかし、その後公開されたMythosとGPT-5.5はこの推定値をさらに上回った。AISIはこの成長スピードが新たなトレンドになるのか、これらのモデルが特殊なのかは不明だとしている。
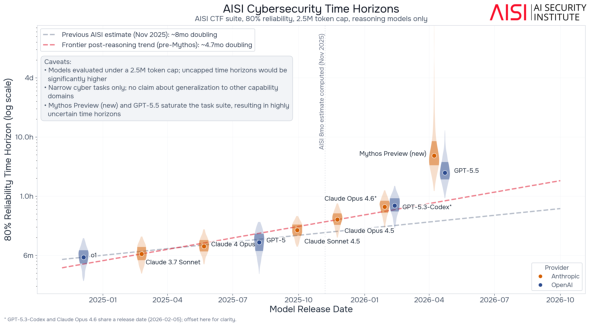 AISIによる、各モデルの80%タイムホライズン測定結果。MythosとGPT-5.5の測定結果(グラフ右上)が既存モデルの性能を大きく上回っている(出典:公式ブログ)
AISIによる、各モデルの80%タイムホライズン測定結果。MythosとGPT-5.5の測定結果(グラフ右上)が既存モデルの性能を大きく上回っている(出典:公式ブログ)
METRとAISIは、AIの性能が想定を上回る速さで向上している状況を受けて、より高性能なモデルを評価できる手法を開発中だとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
2
MicrosoftやNVIDIAなど、AIのオープンウェイト規制に反対する書簡を公開――Anthropicは署名せず
-
3
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
-
4
Anthropic、「Claude Opus 5」公開 Fable 5に迫る性能を半額で――サイバー安全策は緩和、拒否時は自動フォールバックも
-
5
スーパーに並んだ「ごちゃごちゃ生成AIポップ」が物議 “看板王”こと、きぬた歯科院長「これはアリ」
-
6
「KPIは睡眠時間」──オードリー・タンに聞く、日本企業の生産性が上がらない根本原因
-
7
「生成AIで仕事が楽に」のはずが……IT現場を蝕む“AI疲れ・AIうつ”の正体
-
8
NEC森田社長が語る「脱・人月商売」の行方 組織の壁を破るAI人材育成法
-
9
海外の「Claude」や「GPT」ではダメなのか 日本企業向けai&、そのメリットは?
-
10
NVIDIAフアンCEOが語る“日本復活”のシナリオ 10年続く半導体バブルと「原発活用」の勝算
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR