Linuxカーネルのスケジューリング機能の最前線を知る(2/2 ページ)
MIRACLE LINUX V3.0のスケジューラ
こうした問題点を解消すべく、MIRACLE LINUX V3.0で採用しているLinuxカーネル、正確にはLinuxカーネル2.6では「O(1)スケジューラ」を採用している(Miracle Linux 3.0のカーネルは2.4系だが、2.6系の機能を一部バックポートしている)。
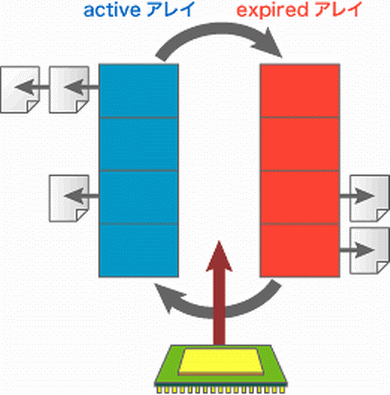
それまで単一の線形リストであったのと異なり、O(1)スケジューラでは、activeキュー、expiredキューと呼ばれる2種類のランキューを持つ。そして、ランキューは実行優先度ごとにスロットを用意している。
 O(1)スケジューラの構造
O(1)スケジューラの構造イメージとしては実行優先度ごとに箱が積み重なっており、その中に同じ実行優先度を持つプロセスが入っていると考えればよいだろう。
これにより、次に実行するプロセスは、activeキューの最も高い実行優先度のスロットから、先頭に登録されているプロセスを選択するだけでよくなる。別のプロセスに切り替えるときは、現在のプロセスをactiveキューからexpiredキューに移し、次のプロセスをactiveキューから選ぶ。すべてのプロセスがexpiredキューに移動し、activeキューが空になった段階でactiveキューとexpiredキューのポインタを切り替えることで、再びactiveキューからプロセスを選択してスケジューリングを行う。
「O(1)スケジューラ」と呼ばれるのは、実行可能なプロセスがいくつ存在していても、検索量は常に一定、つまり、検索指定(オーダー)が1のスケジューラであるためだ。
O(1)スケジューラでは、この2種類のランキューを論理CPUごとに用意することで、CPU間のロック競合をなくしている。また、この構造により、特定のプロセスは、毎回特定のCPU上で実行されることとなり、キャッシュメモリやTLBの有効利用を可能にしている。
ただし、この方法だと、ランキュー次第ではCPUごとに負荷が異なる状態が発生する可能性がある。そのため、ランキュー間で負荷に偏りが出たときは、load_balance関数を使用することで、ランキュー間で実行待ちプロセスの遷移を行いバランスを取る仕組みとなっている。
Hyper-Threading Technologyへの対応
前述のようにランキューを論理CPUごとに用意したスケジューリングだと、実行ユニットとキャッシュを共有しているHyper-Threading Technologyのような構成では最適なパフォーマンスが得られないため、この場合は物理CPUごとのランキューとしている。そしてsiblingsも考慮したロードバランスを行うためのactive_load_balance()関数を用意し、Hyper-Threading Technologyへの対応を図っている。
ちなみに、SUSEではsiblingsも考慮したロードバランスにarch_load_balance()と呼ばれる関数を用意して対応するなど、このあたり、ディストリビューションごとに実装方法が異なる。
このほかのアプローチとしては、Con Kolivas氏が提供しているカーネル2.6スケジューラ用のniceパッチも存在している。こちらは、優先度の異なる2つのタスクが1つのハイパースレッディングCPU上で走る際に、nice値に応じた実行時間にならない問題について、実行時間を補正して対応するもの。しかし、HTのように特定のアーキテクチャに依存するような問題を修正するこれらのパッチはメインストリームに取り込まれる見込みは少ない。
まとめると、Miracle Linux V3.0では、SMPとHyper-Threading Technologyへの対応が図られているということが言えるだろう。
スケジューリング・ドメインとは?
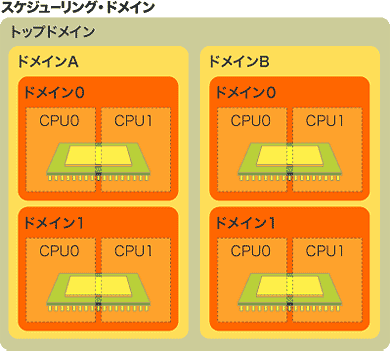
「O(1)スケジューラ」の次に位置するスケジューラの実装も登場しつつある。それが、Linuxカーネル2.6.7で採用された「スケジューリング・ドメイン」だ。これはSMTやSMP、そしてNUMAのようなハードウェアの階層構造に対応するためにスケジューラも階層化したもの。スケジューリング方針、ロードバランス方針などを共有する集合体である「ドメイン」(sched_domain構造体)と、ドメインに属するCPUである「グループ」(sched_group構造体)から成っており、よりきめの細かいスケジューリングが可能になると見られている。
 スケジューリング・ドメインの概念図
スケジューリング・ドメインの概念図ドメインの範囲とグループの構成単位は次のようになっており、このことからも複数のCPUを想定した実装であることが分かる。
| ドメインの範囲 | グループの構成単位 |
|---|---|
| 物理CPU1個 | 論理CPU(sibling)1個 |
| SMP構成1セット | 物理CPU1個 |
| NUMAシステム全体 | NUMA1ノード内のCPU |
Linuxカーネルのスケジューリング機能に関しては、関連記事に挙げたものが詳しい。一読することをお勧めする。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- サイバー攻撃17%増 生成AIプロンプト「26件に1件」が高リスク
- Microsoft、7月の月例更新で約570件を修正 悪用済みゼロデイ2件にまず対応を
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。