「load average」によるCPU負荷の確認:UNIX処方箋
「事件は枯れたシステムが稼働する現場で起こってるんだ」と現場ですぐに役立つ知識を欲するあなたに贈る珠玉のTips集。今回は、uptimeコマンドで出力される「load average」の意味について解説する。

Solaris 8でメールサーバを構築しています。以前、サーバの応答が遅くなった際、CPU負荷を確認しようと思いましたが、Solaris 8にはtopコマンド*がありませんでした。そこで、uptimeコマンドを使用したのですが、出力の「load average」の単位が分かりません。非常に応答が悪い状態でも、「1」や「2」という値なので、CPU使用率ではないようです。この単位を教えてください。
uptimeはシステムの起動時間を表示するコマンドですが、同時に、システムの負荷の目安となる「load average」を表示できます。
# uptime
2:14pm up 34 day(s), 19:42, 4 users, load average: 0.11, 0.05, 0.03
run queueとwait queue
「load average」は、run queueに入っているジョブ*の数を表しています。run queueとはCPUに割り当てられたジョブが入れられる待ち行列のことで、CPU数が1つのときに「2」と表示された場合、CPUは2つのジョブを実行しています。この平均値が「load average」であり、左から1分、5分、15分間のrun queueにあるジョブ数となります。
例えば、「load average」が「1.0」ならば、直近の1分間で常時1個のジョブがCPUに割り当てられていることを意味します。
また、CPUリソースの割り当てを待っている状態のジョブは、run queueの前段階であるwait queueに入ります。これらのqueueの値が大きい状態であればサーバの負荷は高く、間断なく大量のジョブが発生している、あるいは1つのジョブの実行に時間やCPUリソースが大量に消費されていると考えられます。
vmstatコマンド
run queueとwait queueの値は、vmstatコマンドによって同時に確認可能です(実行例1)。実行結果の「r」の項目がrun queueで、「b」の項目がwait queueの値を表しています。
# vmstat
procs memory page disk faults cpu
r b w swap free re mf pi po fr de sr dd dd f0 s3 in sy cs us sy id
0 0 0 292344 52152 0 2 1 0 0 0 0 1 0 0 0 303 373 139 0 1 99
例えば、ジョブの実行/待機状態の流れは図1のようになります。この場合、run queue内のジョブは、
(1+1+2+2)/4=1.5
なので、load averageは1.5となります。
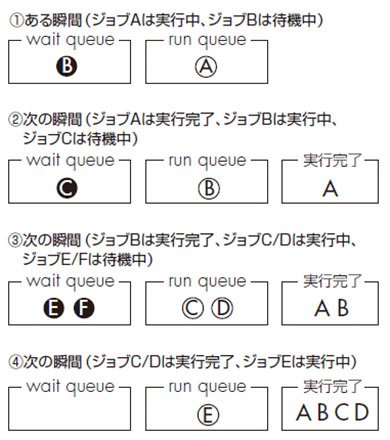 図1 ジョブの実行と待機状態
図1 ジョブの実行と待機状態prstatコマンド
CPUの負荷率を測る場合は、Solaris 8からprstatというコマンドが使用できます。これはtopコマンドの代わりとして使用できるもので、プロセスごとにCPU使用率、プロセスサイズ、ステータス、uptimeが表示可能です。Solaris 8においてtopコマンドと同等の実行結果を出力したいときは、prstatコマンドの使用をお勧めします(実行例2)。
# prstat
PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP
11258 root 6808K 6368K sleep 58 0 0:00.00 0.1% nscd/7
18022 root 1536K 1344K cpu0 58 0 0:00.00 0.1% prstat/1
393 root 2616K 2096K sleep 58 0 0:00.00 0.0% mibiisa/12
:
:
131 root 2424K 1560K sleep 58 0 0:00.05 0.0% rpcbind/1
231 root 1016K 704K sleep 58 0 0:00.00 0.0% utmpd/1
Total: 90 processes, 217 lwps, load averages: 0.03, 0.03, 0.03
なお、prstatコマンドの出力にも「load averages:」という項目がありますが、この値はuptimeコマンドの「load average:」と同じ値を表示します。
このページで出てきた専門用語
topコマンド
プロセスの稼働状況(CPU使用率やメモリ使用率など)をリアルタイムに表示するコマンド。
ジョブ
各プログラムで実行される作業や仕事、処理など。
関連記事
- FTP利用でのファイル/ディレクトリの属性変更
- UFS loggingによるエラーと復旧方法
- ALOMにおけるSC用ユーザーの確認とパスワード変更
- PostgreSQLのテーブルデータをファイルへコピーする方法
- sotrussやapptraceによる実行コマンドのトレース
- TCP遅延肯定応答タイマーのタイムアウト値の変更
- 複数のマシンで効率的にシャットダウンする方法
- WWW::MechanizeモジュールによるWebアクセスの自動化
- IPv6アドレスの自動生成による不具合解消法
- キャッシュファイルを利用したNFSマウント
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 一気読み推奨 セキュリティの専門家が推す信頼の公開資料2選
- Fortinet、管理サーバ製品の重大欠陥を公表 直ちにアップデートを
- 500万件のWebサーバでGit情報が露出 25万件超で認証情報も漏えい
- 米2強が狙う“AI社員”の普及 Anthropicは「業務代行」、OpenAIは「運用プラットフォーム」
- LINE誘導型「CEO詐欺」が国内で急増中 6000組織以上に攻撃
- 「SaaSの死」騒動の裏側 早めに知るべき“AIに淘汰されないSaaS”の見極め方
- 住信SBIネット銀行、勘定系システムのクラウド移行にDatadogを採用
- NTTグループは「AIがSI事業にもたらす影響」をどう見ている? 決算会見から探る
- 2025年、話題となったセキュリティ事故12社の事例に見る「致命的なミス」とは?
- なぜ、投資対効果が不透明でもAIに投資し続けるのか? 調査が明かす「皮肉な現実」
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。