究極の選択――落ちないシステムとすぐ直るシステム:ITIL Managerの視点から(2/3 ページ)
» 2008年06月04日 08時00分 公開
[谷誠之,ITmedia]
MTBF(Mean Time Between Failure)
MTBF(Mean Time Between Failure)の直訳は平均故障時間だが、平均故障間隔、と訳されることが多い。障害が復旧してから次の障害が発生するまでの平均時間のことである。
こちらも単純に言えば、「どれだけ壊れにくいか」ということである。言うまでもなく、可用性を考える上での「システムが壊れにくいこと」に直結している。こちらも現実的ではないが、MTBFのことだけを考えれば、システムが長期間壊れずに稼働し続けるのであれば、まったく修復できない機器だってかまわないわけである。
可用性を高めるためには、MTBFを増やす努力が必要である。MTBFを増やすための方法には、次のようなものが考えられるだろう。
- 障害が発生する前兆となるような現象を監視するツールを導入する
- 過去の障害の傾向(トレンド)を分析し、障害が起こりそうな原因を究明してそれを取り除いてしまう
- 障害が発生しそうな機器を、障害が発生する前に取り替えてしまう
- 信頼性の高い(壊れにくい)機器に買い換える
- 機器を多重化し、複数の機器が同時に壊れない限り全体としてのサービスが止まらないような対策を施しておく
さらにこのMTBFは、システムの「信頼性」という言葉に関係する。信頼性とは単純に壊れにくさのことだと考えていただければよい。壊れないシステムは、信頼性が高いのである。逆に、どれだけメンテナンスが容易で、一瞬で修復できる機器であっても、しょっちゅう壊れているのであれば信頼性は低いわけである。
ここまで説明してきた2つの考え方を図にしたものが図1である。
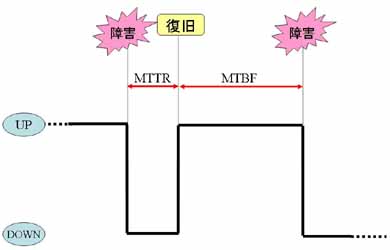 図1:MTTRとMTBF
図1:MTTRとMTBF可用性対策といっても、MTTRとMTBF、どちらの観点に立つかによって、対策が変わってくる。例えば電源装置の可用性を考えてみよう。MTTRを減らすことを主軸においた場合は、「電源装置が壊れたら、即座にバックアップ電源に切り替わる」というような対策になるだろう。また、MTBFを増やすことを主軸においた場合は、「常に電源を二重化しておく」というような対策が考えられる。
Copyright © ITmedia, Inc. All Rights Reserved.
SpecialPR
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 開発者が突然「2026年はあの定番データベースをやめろ」と言い出した理由とは? 愛された技術の裏事情
- KDDIの最大1422万件の情報漏えい事件 その裏には陸自USB問題と同様に中国の影?
- 機械より人をだます方が早い 巧妙化する「二段階フィッシング」にご注意
- 「ランサムウェア」侵入手順を徹底解説 もう知ったかぶりからは卒業しよう
- Mythos Previewに近い性能を3分の1のトークンで実現 OpenAIが新モデル「GPT-5.6」公開
- 「Claude Mythos」が突きつける、IT業界の転換点 われわれが置かれている状況を「姉歯事件」から読み解く
- 日立、ミッションクリティカル領域におけるAI活用を支援 「Hitachi iQ Studio」の3つの特徴
- メインフレーム離脱プロジェクトの7割超が失敗、理由は「生成AIの過大評価」
- 企業データの35%超が「AI生成物」 調査が警告する、データ品質低下と統制不足のリスク
- ガリガリ君の赤城乳業が実現した「クリーンコア」 需要激変に即応する現場オペレーションをどう構築した?
あなたにおすすめの記事PR
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。