PDFファイルを分析する
悪意あるPDFファイルコーディングに段階的変化が見られる。getPageNthWordやgetPageNumWordsのような、Adobeに特有なJavaScriptオブジェクトを使用して分析するのは有効かもしれない。
悪意あるPDFファイルコーディングに段階的変化が見られる(マルウェアオーサーは自分たちのテクニックを適応させることができるし、実際適応させてきたことを考えれば当然のことだ)。
長いことわれわれは、シェルコード、ダウンロード/実行、ドロップ、ロードなどなど、悪質なコードの目的を容易に判別できるような、シンプルな悪意あるPDFファイルを見てきた。
現在は、ますます複雑な難読化が使用されており、PDFファイルを分析することが必要だ。特にこの難読化により、自動化された分析ツールやAV検出ツールさえ回避される可能性があるため、このことは、アナリストの日常生活をより惨めに、あるいは興味深いものにし得る。
ここ数カ月、わたしが遭遇した1つのテクニックは、getPageNthWordやgetPageNumWordsのような、Adobeに特有なJavaScriptオブジェクトを使用するものだ。以下はある例のスクリーンショットだ。
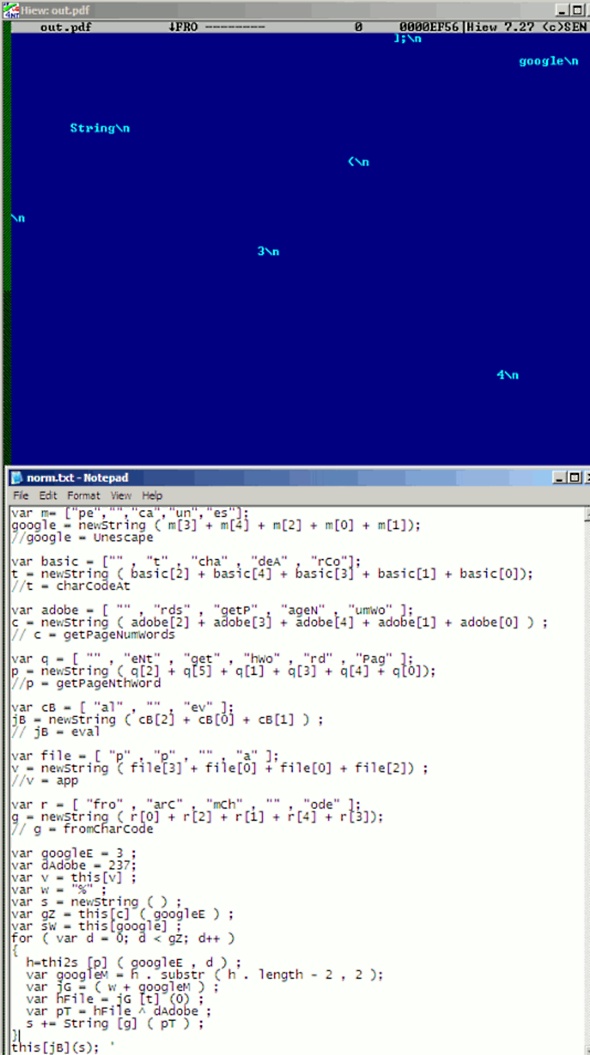
保守的なスタイルのスペーシングが使用されていることに注意してほ欲しい。ノートパッドのコメントは、より簡単に読めるように加えられたものだ。
いずれにせよ、いったんこれが標準化されれば、読んだり分析するのが、ずっと容易なものになるだろう。
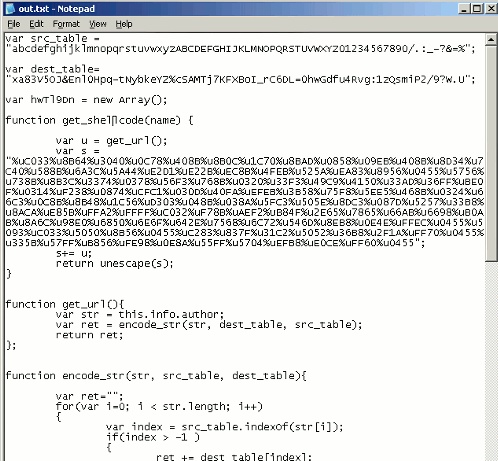
PDF難読化に関する興味深い分析は、SANSにも掲載されている。
投稿はZimryによる。
関連記事
 未修正の脆弱性を狙うPDFファイルに注意、SANSが再度警告
未修正の脆弱性を狙うPDFファイルに注意、SANSが再度警告
Adobe ReaderやAcrobatの未修正の脆弱性を悪用する不審なPDFファイルによる攻撃が増加しているとして、SANSが改めて注意を呼び掛けた。 Adobe ReaderとAcrobatの脆弱性、修正パッチは1月12日にリリース
Adobe ReaderとAcrobatの脆弱性、修正パッチは1月12日にリリース
ゼロデイ攻撃も発生しているReaderとAcrobatの脆弱性が解決されるのは1月12日になる。 Adobe ReaderとAcrobatを悪用する攻撃発生、未修正の新たな脆弱性が見つかる
Adobe ReaderとAcrobatを悪用する攻撃発生、未修正の新たな脆弱性が見つかる
脆弱性を突いた悪質なPDFが電子メールの添付ファイルとして出回っているという。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 開発者が突然「2026年はあの定番データベースをやめろ」と言い出した理由とは? 愛された技術の裏事情
- KDDIの最大1422万件の情報漏えい事件 その裏には陸自USB問題と同様に中国の影?
- 機械より人をだます方が早い 巧妙化する「二段階フィッシング」にご注意
- 「ランサムウェア」侵入手順を徹底解説 もう知ったかぶりからは卒業しよう
- Mythos Previewに近い性能を3分の1のトークンで実現 OpenAIが新モデル「GPT-5.6」公開
- 「Claude Mythos」が突きつける、IT業界の転換点 われわれが置かれている状況を「姉歯事件」から読み解く
- メインフレーム離脱プロジェクトの7割超が失敗、理由は「生成AIの過大評価」
- 日立、ミッションクリティカル領域におけるAI活用を支援 「Hitachi iQ Studio」の3つの特徴
- 企業データの35%超が「AI生成物」 調査が警告する、データ品質低下と統制不足のリスク
- ガリガリ君の赤城乳業が実現した「クリーンコア」 需要激変に即応する現場オペレーションをどう構築した?
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。