「NoOps」を実現できる時が来た! NoOpsとは運用の“うれしくない”ことをなくすこと:NoOps Meetup Tokyo #1(3/4 ページ)
NoOpsの作り方
NoOpsの実現には「復元力(Resiliencability)」だけではなく、障害が起きたときにそれをいかに早く検知する観察力「Observability」も必要です。ログを見て検知するのでは遅い。そして、障害を検知したら、システムを再構成する能力「Cofigurability」も必要です。
仮に、クラウドのあるリージョンが死んだとしましょう。それを検知してオンタイムで別のリージョンで同じシステムを構成して復元する――ということも現在では可能です。データさえ同期させておけば、検知して、構成して、復元できるのです。
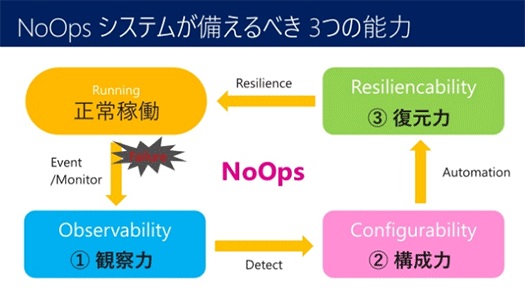 NoOpsシステムが備えるべき3つの能力
NoOpsシステムが備えるべき3つの能力こうしたシステムを実現する上で一番大事なのは、仕様には書かれていない観察力、構成力、復元力を兼ね備えたシステムやサービスを採用すること。これには目利きが必要です。
ミドルウェアやインフラが回復力を持っていても、例えばバッチ処理を回しているときに落ちました、というときにはインフラだけ復元させてもダメで、バッチ処理のどこで落ちたか、どこから再実行するかといった人力の作業が処理の回復に必要です。だからこそ、アプリケーション側にも回復力を持たせる必要があります。
 アプリケーションにも回復力を持たせる必要がある
アプリケーションにも回復力を持たせる必要があるそのための原則として、粒度はできるだけ小さくします。1時間もかかる処理は復元が難しくなるでしょう。処理はステートレスで。ステートを持たせても消えてしまいます。そして非同期処理。同期処理だと全てのプロセスが連鎖していくので、途中で落ちたら最初からやり直しです。
最後に一番大事なのが処理の冪等(べきとう)性を担保すること。どのサーバで何回リトライしても、正常終了したら、結果は同じ場所に同じ値が書き込まれる。この冪等性を全ての処理で担保する。さらに追跡可能性という意味で、処理結果を記録します。
これらの要件の目指すところは、シンプルなリトライです。落ちました、それならリトライする。それでダメなら別サーバでリトライする、それでもダメなら別リージョンでリトライする……それで大丈夫な設計にしていきたいということです。
 回復性を持たせるためのアプリケーション設計原則
回復性を持たせるためのアプリケーション設計原則Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。