「NoOps」を実現できる時が来た! NoOpsとは運用の“うれしくない”ことをなくすこと:NoOps Meetup Tokyo #1(2/4 ページ)
NoOpsのカギは高い「復元力」
10年前あるいは20年前は、システムの「堅牢性」がすなわち信頼性でした。MTBF(=Mean Time Between Failure:平均故障間隔)至上主義で、多重化や高度なエラー検知と訂正機能などを持つサーバが作られ、その高価な機器を10年保守や20年保守で大切に使っていました。
その価値観がこの10年で大転換しました。十分な性能や帯域を持つシステムが安価に手に入るようになって、これらを入れ替えながら、信頼性はソフトウェアで構成しましょうという世界になりました。
技術の変化と共に設計思想も変化していきます。堅牢性を設計する「Design for Robustness」から、障害を前提とする設計の「Design for Failure」になったわけです。そして今、ここからさらに進化して「Design for Resiliency」、回復性設計の時代に来ています。これは障害から回復して、動作を続行する能力を持つシステムを設計するものです。
 技術と共にシステムの設計思想も変わっていきます
技術と共にシステムの設計思想も変わっていきますNoOpsの鍵は「高い復元力」です。取り回しの軽さと言ってもいいかもしれません。例えば、ChefでWordPress環境を構築する時間が240秒、これがコンテナであれば14秒で済みます。
アプリケーションのタイムアウトは大体30秒くらいですから、アプリケーションが壊れても30秒以内に検知し、再構築してReadyになるのならば、ユーザーから見れば壊れていない、つまり「サービスが続いている」という状態を実現できます。
コンテナやOSをできるだけ小さくしようというのは、こういう状態を目指しているのです。「壊れない」システムから、「いつでも回復できる」システムへの価値観の転換です。
今まで、復元力は低いけれど高い可用性が欲しい場合、冗長構成が必要でした。しかしいまは高い復元力も簡単に手に入る。つまり一人でも「高い可用性」が手に入るようになったのです。しかもそれだけではなく、障害発生時の自己回復やオンザフライでのインスタンス変更、秒単位のスケールアウトやスケールインなどができるわけです。
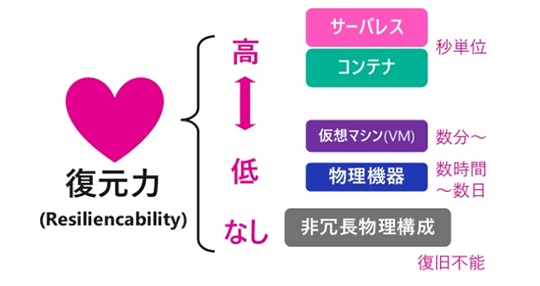 今はサーバレスやコンテナなど、高い復元力を持つシステムが簡単に手に入るようになっています
今はサーバレスやコンテナなど、高い復元力を持つシステムが簡単に手に入るようになっています 高い復元力(回復性)を持つことで、オンザフライでのインスタンス変更など、さまざまな可能性が広がります
高い復元力(回復性)を持つことで、オンザフライでのインスタンス変更など、さまざまな可能性が広がりますCopyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。