第3章 “CRISP-DM”に基づくデータマイニングの進め方:マーケターのためのデータマイニング講座
第1章、第2章においてはCRM実現に際してのデータマイニングの役割、および統計解析とデータマイニングとの相違に関し言及してきました。ビジネス環境が劇的に変化する中でCRMを実践するうえでのデータマイニングの意義についてはご理解いただけたと思います。本章では、マーケティング担当者がデータマイニングを進めていく工程を“CRISP-DM”という手法に沿って、できる限り専門用語を使わずにその概要を述べていきます。
1.CRISP-DMとは?
CRISP-DM(CRoss-Industry Standard Process for Data Mining)は、SPSS、NCR、ダイムラークライスラー、OHRAがメンバーとなっているコンソーシアムにて開発されたデータマイニングのための方法論を規定したものです(CRISP-DMの詳細)(注1)。
これは、データマイニングプロジェクトを具体的にどのような手順で進めていくのか、各工程において実施する作業はどのようなものがあるのかを明確に定義しています。一見すると単純そうですが、実体験に基づいたきめ細かなプロジェクト工程が理解でき、その適用の汎用性および柔軟性から多くのデータマイニングプロジェクトに採用されています。
CRISP-DM──業種を超えたデータマイニングの標準化手法
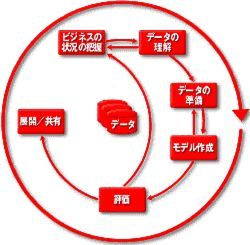
フェーズ1:ビジネスの状況の把握
フェーズ2:データの理解
フェーズ3:データの準備
フェーズ4:モデル作成
フェーズ5:評価
フェーズ6:展開/共有
マーケティング担当者がCRM実現のために行うデータマイニングは、顧客、商品、売り上げ、店舗、Webログなどのデータから顧客ニーズの傾向をつかむことから始まります。そこから顧客と商品に対しての企業戦略を導き出し、売り上げ予測などを行うことも可能となるわけです。システムとしてはデータ・ウェアハウスを構築していなくても、データマイニングは始めることができます。
次項では、データマイニングの実際の作業を6つのフェーズに分け、それぞれのフェーズで行うべき内容と留意点などを簡単にまとめていきます。これは上述のとおり、マーケティング分野のみを対象としたものではありませんが、実務をイメージしながら読み進めてみてください。
おそらくイメージしづらいのは、自社内でどのような「データ」が存在し、それらはどこにどのような形式で格納されているのか、そしてそれらをどうやってマイニングの入力とするのかという極めて基本的なことかもしれません。普段、集計処理などで用いているExcelのデータや情報システム部門で処理しているDBMS(各種データベース)、あるいはアンケートに記述されているいまだ電子化されていないデータなどもあるかもしれません。それらが分析に適したデータか否かはともかく、すべてのデータはマイニング対象として検討してみる価値があります。
2.データマイニング実践手順
ここからの各フェーズにおいては、分析者、PC、何らかのデータの3つの要素が存在することを前提としていますが、データが主役で、ビジネスにたけた担当者や分析者が監督という役割となります。
フェーズ1:ビジネスの状況の把握
まずはプロジェクト目標の設定を行います。企業内の各種課題を明確にしたうえで、データマイニングプロジェクト全体をプランニングしていきます。データマイニングを行うことそのものが目的ではありませんので、ビジネス状況をマーケティング担当者の観点から数値として正確に把握し、テーマを選定していくことが肝要です。
第2章でも触れられていますが、データマイニングプロジェクトを効率的かつ効果的に進めるためにはビジネスセンスに依存する部分が大きく、特にこのフェーズ1においてはビジネスエキスパートとして自身が属する業界や自社の状況をつかみ、課題と目標を定義する必要があります。具体的テーマとして、DMのレスポンス率を向上させたい、スイッチャー(退会者)を減らしたい、優良顧客を特定したいといった項目を設定し、目標数値、分析工程のスケジューリングも具体的に示しておくことも重要です。
フェーズ2:データの理解
データマイニングにおいて、データがあるからすぐに分析しやすいように加工を始めて分析していくと考える方が多いのですが、その前にそれらのデータが本当に利用できるかどうか吟味する必要があります。基本的にはデータ項目、量、品質を調査することになります。多くの場合、外れ値(データ分布上、数値的に懸け離れたデータ)や欠損値(ブランクのデータ)といったものが含まれており、分析に使用できるデータであるか否かを判断しなければなりません。また必要とされるデータ項目が欠落している場合はデータを集め直す必要性が生じるかもしれません。
ここでフェーズ1に立ち返る必要があります。このフェーズでの調査結果を踏まえてデータがビジネス目標を達成するのに必要十分な内容であるかという検討です。使用可能なデータでなければ、目標に見合った分析ができないという判断をしなければならないこともあります。ここでの判断がプロジェクトの行方を大きく左右することになります。
またシステムインフラの課題として、データ処理をするうえでマシンスペックがデータ量に適合したものであるかどうかも検討しなければなりません。数千万件のデータを低スペックなPCでデータ処理させるのはパフォーマンス上無理があり、データマイニングを円滑に進められません。
フェーズ3:データの準備
マイニングの前処理として、使用可能なデータを分析に適したデータに整形していきます。いわゆるデータクレンジング(洗浄)作業です。
データの良い悪いによってマイニング結果が大きく左右されますので、結果的にフェーズ2とこのフェーズのデータ準備にデータマイニング全工程時間の多くを費やすことになります。
すでに意思決定支援を目的とするデータ・ウェアハウスを構築している場合でも、データマイニングにとって最良のデータとは限りません。ここでの作業は地味でコツコツと進めていく工程となります。このフェーズでの処理概要は以下のように大別されます。
- 欠損値処理
マイニング対象のデータに欠損値が含まれている場合、データ演算の正確な処理ができなくなります。欠損値がブランクとして意味を持つ場合以外は、それらを意味のある定数で埋めるか、または削除しなければなりません。
- データ型の整備および正規化
マイニング手法により量的データ(数値)を必要とする場合と、質的データ(記号)を必要とする場合があり、これらを混在させることは許されません。ここではデータ項目のデータ型を後続処理に適した形に変換処理します。誕生日データから年齢データへの変換や、商品データと顧客データの結合などを含みます。またデータの冗長性を排除するために正規化を行います。これにより繰り返しのある項目の独立化や他項目からの間接演算で得られる同一内容を除去し、信頼性が高く無駄のないデータを作り出すことができます。
- サンプリング
大規模なデータを処理する場合、状況によりサンプリングによってデータ件数を絞り込みます。このサンプルデータを用いて全体の概観をつかもうというものです。ただし、サンプリングを適用すべきでない場合もあります、例えば購買トランザクションデータから個々人の売上総計を集計して後続処理するような場合や、データの異常値検出処理のような場合は、全件処理が前提となります。
最近注目されているテキストマイニングの場合は、アンケートや掲示板などの自由記述文、あるいは雑誌、新聞の記事などを分析対象データとすることが多いのですが、それらテキストデータを形態素解析(単語の分かち書き)したうえで、データ準備を行う必要があります。また、Webマイニング(ホームページのアクセスをベースとした分析など)の場合は、Webログの形式によってその準備方法が異なりますので注意が必要です。
データの準備に際しては、各種データマイニングツールの機能としても提供されており容易にデータ加工できますが、プログラミングにたけた方であれば簡単な入出力プログラムの作成により高速な処理ができるかもしれません。
フェーズ4:モデル作成
さて、ここまで準備して初めてモデルの作成となります。モデルとは、適した手法を用いて作成され、学術的な裏付けに立脚したデータ処理をするための機能と考えてください。
モデル作成のための手法は数多くありますが、代表的なものとしては、相関分析、回帰分析、マーケットバスケット分析、クラスター分析、遺伝アルゴリズム(GA)、決定木、ニューラルネットワークなどがあります。手法詳細の解説は別の機会としますが、一般的にCRM実現に際しては、顧客、商品、市場などを有機的に組み合わせて分類や予測モデルを行います。最近では、ニューラルネットワークを適用する例が増えてきています。ニューラルネットワークはニューロン(人の脳内神経線維)の働きをモデル化した仕組みがベースとなっています。いずれにせよ各手法ともに長所もあれば短所もあるため、ある程度それらを理解したうえで最適な状況で使い分けていくことが大切です。
逆にいえば、万能なマイニング手法は存在しないということです。それぞれのマーケティング担当者の方々が持つテーマごとに手法を選択する必要がありますが、現実的には複数手法での分析を行い、ビジネス感覚上最も当てはまっているなと感じるモデルを選択する場合が多いことも事実です。モデル作成には高度な技術と深い知識を必要とするような印象を受けがちですが、要件に見合ったデータマイニングツールを使用すれば試行錯誤しながらでも効率的に実践していくことができるものです。
フェーズ5:評価
モデル作成のフェーズでは複数の手法を反復的に行うのが通常ですが、CRISP-DMの各フェーズを通してプロセスを繰り返し行う必要があります。データの中に潜む関連性や特徴はその時々で変化することがあります。このためタイムリーで精度の高いモデルを作り続けていないと、意思決定に必要なナレッジは陳腐化してしまいます。
このフェーズでは、フェーズ1で明確に定義したビジネス目標を達成するに十分なモデルであるかをビジネスの観点から評価していきます。この評価に際し、具体的な数値を得るための実験(制約を設けたうえで、データマイニング結果をビジネス展開)を行うこともあります。
このフェーズでも、ビジネスエキスパートが重要な役割を担うことになります。ここまでのモデル作成の結果をビジネスへの展開につなげていくことが現実的に有効であるのかといった判断をしなければならないからです。
フェーズ6:展開/共有
いよいよデータマイニングした結果をビジネスに適用するための具体的なプランニングを行っていきます。データマイニングの結果として、特定の分類に属する人を対象にDMを送付したり、商品の陳列を変えたり、という単純なものも含めて、利益率の向上や業務効率化を目的としてフェーズ1で設定した目標を達成するための具体的アクションを起こしていきます。
このようにデータマイニングを実践することは、CRMを効率的に進め効果を最大限に引き出すうえにおいて有効なことは事実ですが、すべてのケースにおいて万能ではありません。何らかのデータが存在して、それをデータマイニングツールで分析したとしても、必ず有益な分析結果を導き出してくれるとは限らないのです。データマイニングはデータ分析技術ではありますが、その過程においてどのようにデータを最適加工するのか、数多くの分析アルゴリズムの中でどの手法を用いるのかなどにより、結果の現実的な有用性には大きな差異が生じてきます。また分析結果をどう解釈するかにより、結果を踏まえたビジネスアクションが異なってくることがあります。
今回はデータマイニングの進め方ということで、各工程で実施しなければならない事柄を述べてきました。次回はこれら一連のデータマイニングを行った事例の考察です。
(注1)(CRISP-DMの詳細)
Profile

田畑 殖之(たばた しげゆき)
SPSS ビジネスインテリジェンス事業部プロフェッショナルサービスグループ
大学卒業後、システム・インテグレータ企業にて、システム・プログラマとして、主に金融系企業でのシステム構築に携わる。その後、外資系IT企業にてシステム・パフォーマンス・アナリストを10年以上経験。IT関連プロジェクトの立ち上げやマネージメントを数多く手掛ける。2001年4月より現職。
エス・ピー・エス・エス株式会社
米国SPSS Inc.の日本法人として1988年に設立。設立以来、統計解析ツールSPSSを中心とした製品群と、関連サービスを提供。CRMなどの分野を中心にデータマイニングが注目される中、1999年5月、データマイニングツールClementineを発売。国内データマイニング分野では、最大級のユーザー数を誇る。2001年からは、データマイニングプロジェクトの標準であるCRISP-DMに沿ったコンサルティングサービスの提供など、顧客のビジネスを成功に導くソリューションを提供している。
代表取締役:イアン・スタンレイ・デュエル
東京都渋谷区広尾1-1-39
ホームページ:http://www.spss.co.jp/
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- 大手コンサル15社も「対応できない」 なぜ、ある大企業はシステム刷新を断られたのか?
- Windows 11、Dell製PCの不具合を修正する緊急パッチを配信 自動配信の条件と手動の導入手順は?
- なぜ「おじさん人材」が選ばれる? 新卒採用が鈍化するIT部門の実像
- 「AI使うなら値引きできる?」の“暴論”に、日立はどう立ち向かう? レガシー刷新でのAI活用の現在地
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- AIエージェント時代に直面する「新たなセキュリティと内部統制」 日立ら大手はどう考えるのか
- 予定表招待「はい」で情報流出 Geminiを狙う攻撃の手口
- AIエージェント時代、なぜデータ基盤の進化が求められるのか? 次世代アーキテクチャの基本を解説
- AI作成メールのクリック率は人間と同等に 年1回のセキュリティ教育では防御困難か
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。