あるあるネタで学ぶ、障害対応“7つの鉄則”:システム管理入門(7)(3/3 ページ)
部品も記録も「備えあれば憂いなし」
◎(5)修理、または交換する
この時間を短くするには、普段の心掛けが肝心です。具体的には、修理する人の技術的なスキルを磨く、交換用の部品をいつもストックしておく、修理しやすい製品を採用する、修理する人が外部にいる場合はその人への連絡先を分かりやすい形で周知しておく、といったことです。まさに「備えあれば憂いなし」ということですね。
◎(6)故障が直ったことを確認する
これは意外と忘れがちな作業です。部品を交換して故障が直ったかのように見えて、実はまだ直っていない、という場合があります。筆者の経験では、ホットプラグ(電源を投入したままの部品交換)に対応していない SCSIディスクコントローラが故障した、という事例があります。
しかしこの SCSIディスクコントローラ、一度電源を切って冷ましてから電源を投入すると、しばらくは元気に動いているのです。筆者は「ハードディスクが壊れたのかもしれない」と思い、予備のハードディスクと交換してみました。ホットプラグに対応していなかったので、ハードディスクを取り外すには本体の電源を切らなければなりません。ハードディスクを交換するのにも数分の時間がかかります。結局、ハードディスクを付け替えてから電源を入れたら、SCSI コントローラは十分に冷めたのか(?)、元通りにディスクアクセスができるようになったのです。
この時点で、私は「故障の原因はハードディスクにある」と勘違いしてしまったわけです。SCSI コントローラが温まってきたころには、再び故障状態に逆戻りしてしまいました。
故障が直ったかどうか、という点に関しては、「何分以上正常な動作をしたら『直った』とみなす」というような取り決めが必要です。この何分という部分はケースバイケースです。この何分という部分の妥当性を高めるためにも、今までの故障の記録が重要なのです。
◎(7)故障が直ったことをユーザーに通知する
こちらも重要な作業です。システム管理者が「ああ、直った」と感じた時点で故障が直った、わけではありません。その故障していたシステムを利用しているユーザーが「ああ、直った」と感じる必要があるからです。システム管理者レベルで「故障が直った」と感じたら、即座にユーザーに通知しなければなりません。
故障を未然に防止する
◎(1)故障が発生する
さて、最後に「(1)故障が発生する」について考えてみましょう。これはちょっと特殊です。(2)〜(7)に掛かる時間については極力短くすることが大切ですが、ここの「時間」、つまり「前回故障してから今回故障するまでにかかった時間」はできるだけ長くしなければならないからです。すなわち「壊れにくくする」ための作業が必要なのです。
具体的には、先ほど(5)で紹介した「予防保守」も「壊れにくくする」ための大事な措置です。また、上等な部品や製品(世間一般に定評があるもの)を使う、電源のふらつきや温度の上昇といった「故障の原因となるもの」を取り除く、といったことで「壊れにくい」環境を整えます。
なお、これも筆者の経験上の知見ですが、「初期ロットのものは避ける」ということが言えると思います。まったく新しい新製品の初期ロットには、何らかの「故障しやすい原因」が潜んだままになっているかもしれません。新製品が出たからといってすぐに飛びつくのは避けましょう。それよりも、定評のある旧製品を採用するほうが、結局コストパフォーマンスを高める結果になるかもしれません。
大切なのは、お金と効果のバランスを見極めること
最後に、あと一つだけ付け加えておきましょう。それは(2)〜(7)の全ての項目をやみくもに高速化しようとするとお金が掛かるということです。従って、一番大切なのは「どこに最も時間がかかっているか」を見極めることなのです。
ITILでは、「拡張インシデント・ライフサイクル」という概念を導入しています。インシデントには発生から解決までのライフサイクルがあります。「拡張インシデント・ライフサイクル」とは、このインシデントの“ライフサイクル”という概念をさらに拡張して、「インシデントの解決時間をより短縮するために、必要な改善事項を識別するために用いられる概念」を指しています。
例えば、「インシデントの解決に時間がかかっている」現状を把握するために、「どこに最も時間がかかっているか」をライフサイクル単位で検証するのです。以下の図の例では、インシデントの発生から検出までに最も多くの時間がかかっているということが分かります。
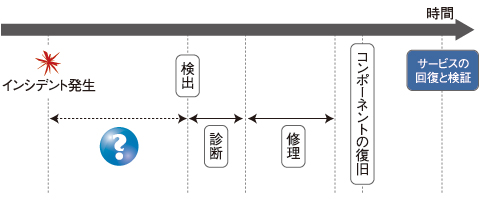 図 「インシデントの解決に時間がかかっている」現状を把握するために、「どこに最も時間がかかっているか」をライフサイクル単位で検証する。こうした現状認識を基に「どこにお金を掛けるのか」を考える
図 「インシデントの解決に時間がかかっている」現状を把握するために、「どこに最も時間がかかっているか」をライフサイクル単位で検証する。こうした現状認識を基に「どこにお金を掛けるのか」を考えるこれはインシデントの例ですが、今回解説した「故障」についても同じことが言えます。「(1)はどれだけ時間がかかっていないか/(2)〜(7)は「何に最も時間がかかっているか」を客観的に把握し、(1)なら「異常なほど時間がかかっていない」場合に注目して対処を検討し、(2)〜(7)では時間がかかっているもの」に注目して時間短縮について考えるのです。
次回は、「原因の究明と再発防止」について考えてみます。お楽しみに。
著者紹介
▼著者名 谷 誠之(たに ともゆき)
テクノファイブ株式会社 阪神支社 ラーニング・コンシュエルジュ。IT技術教育(運用系/開発系)、情報処理試験対策(セキュリティ、サービスマネージャ、ネットワークなど)、対人能力育成教育(コミュニケーション、プレゼンテーション、チームワーク、ロジカルシンキングなど)を専門に約20年にわたり、活動中。「講習会はエンターテイメントだ」を合言葉に、すぐ役に立つ、満足度の高い、そして講義中寝ていられない(?)講習会を提供するために日夜奮闘している。
ディジタルイクイップメント株式会社(現:日本HP)、グローバルナレッジネットワーク、ウチダスペクトラム、デフォッグなどを経由して現職。
テクニカルエンジニア(システム管理)、MCSE、ITIL Manager、COBIT Foundation、話しことば協会認定講師、交流分析士1級などの資格や認定を持つ。近著に『高度専門 ITサービスマネジメント』(アイテック、2009年6月)
がある。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 開発者が突然「2026年はあの定番データベースをやめろ」と言い出した理由とは? 愛された技術の裏事情
- スマホはもはや「実印」? パスワード870件分の警告をAIはどう救うのか
- 住信SBIネット銀行、勘定系をクラウドに全面移行 コスト30%削減の鍵を握る「次世代基盤」とは
- FDEとリコーの新コンサルサービス、どこが違う? AXのパートナー選びを考察
- KDDIの最大1422万件の情報漏えい事件 その裏には陸自USB問題と同様に中国の影?
- 世界のランサムウェア攻撃、4217件に データ流出規模の上位5件を占めた国は?
- アクセンチュア、重要インフラのセキュリティ事業強化へ またもや3社買収の狙いは?
- 「AIの暴走を止められない」 CISO座談会で見えたAIセキュリティの限界
- AIはITエンジニアを淘汰しない Microsoft調査が示す、AI委任とキャリアの好機
- たった1件の不備でマイナス1万点 AIの物量攻撃に耐える“基礎の強度”
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。