サイロ型のシステム監視が、問題解決を遅らせる:ビジネス視点の運用管理(2)(2/2 ページ)
まず“全体”を見て“部分”に掘り下げる
さて、以上を簡単にまとめると、5つのカテゴリの中で最も重要なのが、エンドユーザー体感を計測、監視するEnd User Experience Monitoringで、これを補強するのがUser Defined Transaction Profilingと、Application Component Deep Dive Monitoringという位置付けになります。
これら3カテゴリは、一つの監視ツールで実現できることもあれば、それぞれを別のツールで実現する場合もあります。ただ、最も大切なのは3つのデータを統合して管理し、それらを関連付けて分析することです。
前回も簡単に紹介しましたが、APMのメリットの一つは、パフォーマンス問題の原因究明時間の劇的な短縮です。 従来、運用現場で用いる原因究明プロセスはサイロ型の情報収集の積み上げでした。つまり、ITシステムを細かく区切って、各構成要素から収集した情報から、どこに問題があるかを判断する方法です。サーバ単位、あるいはネットワーク機器単位の監視がこの典型的な例です。
しかしこの方法は、システムが複雑になればなるほど無駄な情報が多くなり、分析に長時間を要するようになるうえ、ますます問題原因にたどり着きにくくなります。APMはその逆のアプローチであり、まず全体を見てから問題個所を切り分けていくことによって原因を突き止めるものなのです。
APMの3つのカテゴリ、End User Experience Monitoring → User Defined Transaction Profiling → Application Component Deep Dive Monitoringという流れも、まさにそうした「全体から部分へ」というプロセスの流れを表すものです。
具体的には、まずEnd User Experience Monitoringでエンドユーザーの体感を計測します。その結果、レスポンスタイムに問題がある場合は、システムを大まかに切り分けます。例えば、遅延がデータセンター内で発生しているのか、データセンター外で発生しているのかを推測する、といった粒度です。
その上で、データセンター内で遅延が発生している場合には、User Defined Transaction Profilingを行い、そのレスポンスタイムの計測結果を分析して、データセンター内のどこに問題があるのかを突き止めます。その結果、問題原因がアプリケーションサーバにあると判断した場合には、Application Component Deep Dive Monitoringを行い、そのレスポンスタイムの計測結果から、特定のJavaメソッド、特定のSQLリクエストといった原因を究明する、といった具合に、全体から段階的に問題個所を絞り込んでいくのです。
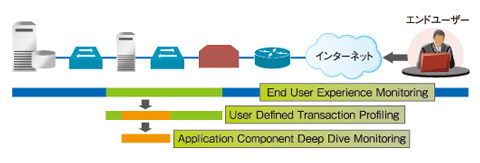 図3 ITシステムのパフォーマンスの問題を、全体から部分へと、段階的に絞り込み、掘り下げていくのがAPMという手法の特徴。非常に多くの構成要素が絡み合った、昨今の複雑なITシステムほど、APMのメリットを享受しやすい
図3 ITシステムのパフォーマンスの問題を、全体から部分へと、段階的に絞り込み、掘り下げていくのがAPMという手法の特徴。非常に多くの構成要素が絡み合った、昨今の複雑なITシステムほど、APMのメリットを享受しやすい
システムの構成管理がAPMのキモ
さて、こうした中、5つのカテゴリのうち、Application Component Discovery and Modelingだけ、少し位置付けが異なっていたことを思い出してください。これはレスポンスタイムを計測するものではなく、「対象のITシステム内にどのようなコンポーネント(ハードウェア、ソフトウェア)があるのかを検知(Discovery)し、コンポーネント間の関係をプロトコルも含めて明示(Modeling)する」という、構成管理に近い取り組みであると紹介しました。
これは「5つのカテゴリの中でも最も重要」と述べたEnd User Experience Monitoringとはまた違った意味で不可欠な取り組みとなります。
というのは、そもそもシステム監視に「エンドユーザー体感」を取り入れる必要が生じたのは、システム構成が複雑になり、サーバやネットワークの監視だけでは「エンドユーザーが快適にシステムを使えているか」という、本来の監視目的を果たしにくくなったためでした。その目的に照らすと、あるサーバがダウンして、サーバ監視ツールが監視コンソールにアラートを上げたとしても、その障害がどのサービスに影響を及ぼすのか、すぐに把握できなければ、あまり意味がありません。
その点、Application Component Discovery and Modelingとは、サーバやネットワーク機器などのシステム構成情報を収集し、そのモデリングを行うものです。具体的には、 「あるアプリケーションサーバとデータベースサーバがSQLの通信で接続されている」など各システム構成要素の論理的関係を明らかにします。
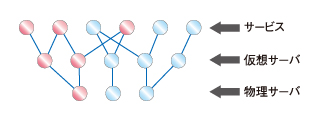 図4 Application Component Discovery and Modelingで各システム構成要素と、構成要素間の関係性を把握しておけば、問題の原因個所やビジネスへの影響範囲を特定しやすくなる
図4 Application Component Discovery and Modelingで各システム構成要素と、構成要素間の関係性を把握しておけば、問題の原因個所やビジネスへの影響範囲を特定しやすくなるつまり、この関係図とエンドユーザー体感監視で得た情報を組み合わせることにより、パフォーマンス問題が発生した際には、右の図4のようなイメージで、そのサービスを支えているサーバ、ネットワーク機器を特定したり、逆にサーバやネットワーク機器に障害が発生した場合に、影響が及ぶ可能性のあるサービスを即座に特定したりすることが可能になるのです。
ツール選びの前に、APMの目的設定を
さて、今回はAPMの5つのカテゴリを2つのグループに分けて、その効果を説明してきました。まとめると以下のようになります。
「End User Experience Monitoring」「User Defined Transaction Profiling」「Application Component Deep Dive Monitoring」の3つを併用して、パフォーマンス問題の原因を“全体から部分へ”段階的に切り分け、問題解決までに要する時間を短縮する
「End User Experience Monitoring」と「Application Component Discovery and Modeling」を併用して、各システム構成要素とサービスの関係を明らかにし、システム面の問題がビジネスに与える影響を可視化する
以上2点が、APMという概念の骨格となります。
ではAPMを実践する上で、今回述べた5つのカテゴリは、どの順番で導入すれば良いのでしょうか。一般的には、次の順が効果的でしょう。
- End User Experience Monitoring
- User Defined Transaction Profiling
- Application Component Deep Dive Monitoring
- Application Component Discovery and Modelingと、Application Performance Management Database
つまり、エンドユーザーが体感するレスポンスタイムと、 問題原因を切り分けていくためのレスポンスタイムを測る機能を、まず最初に確保し、その上で構成管理と連動して「ビジネスへの影響」を可視化できる環境を整えます。
複数のベンダが提供しているツールの中には、5つのカテゴリ全てに対応する機能を備えているものもあれば、1つのカテゴリに特化して、より細かな機能を提供しているものもあります。ただ、APMを行っていなくても、Application Component Deep Dive Monitoringと、Application Component Discovery and Modelingを実現するツールについては、データベース監視ツールや構成管理ツールなどの形で、すでに所有している場合もあるのではないでしょうか。
ただ、前回も述べましたが、ツール選びで最も重要なのは、APM(エンドユーザー体感監視)によって、自社が得たい効果を明確化しておくことです。機能のみに目を奪われることなく、「どの機能が必要なのか」を割り出して、適切なツールを選択することが大切です。
著者紹介
▼著者名 福田 慎(ふくた しん)
日本コンピュウェア 営業本部 シニアソリューションアーキテクト。長年に渡り、ITサービス管理の分野に従事。 BMCソフトウェアや日本ヒューレット・パッカードなど、米国リーディングカンパニーの日本法人にて、プリセールスとして数多くの案件に携わり、IT部門が抱える課題解決を支援。現在は日本コンピュウェアにて、シニアソリューションアーキテクトとして顧客企業への提案を推進する傍ら、講演活動にも積極的に取り組み、アプリケーションパフォーマンス管理の啓発活動を展開している。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- サイバー攻撃17%増 生成AIプロンプト「26件に1件」が高リスク
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- Microsoft、7月の月例更新で約570件を修正 悪用済みゼロデイ2件にまず対応を
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。