第4章 映画・小売に見るデータマイニング導入手順の実例:マーケターのためのデータマイニング講座(1/2 ページ)
前章「“CRISP-DM”に基づくデータマイニングの進め方」にて詳述した“CRISP-DM”データマイニング手法にのっとった実例を2社ご紹介したいと思います。これら2社はいずれもマーケティングのテーマから端を発し、経営の根幹にかかわるテーマに進展しています。
それではまず国内事例の考察です。
1.株式会社 ギャガ・コミュニケーションズ事例
ビジネスの理解
映画配給産業全般のビジネスフローは、作品情報収集、作品買い付け、予算策定、宣伝方針決定、劇場公開の順に進んでいくのが一般的です。これらの各ステップをくまなく理解し、どの段階でどのような目的のためにどういったデータマイニングテクニックを利用して解決していくかを明確にする必要があります。
通常、それらの策定にはかなりの時間を要するものですが、幸い当事例のギャガ・コミュニケーションズの場合は、先進的に5年前からこの作業に取り組んでいたため、速やかに次のステップに移っていくことができました。
ギャガ・コミュニケーションズでは、収集された作品情報は電子化、データベース化され、作品買い付けの意思決定支援となるシステムが構築されています。予算策定の段階ではすでに興行収入予測モデルが導入されており、かなりの精度でリスク回避に役立てています。さらに、宣伝方針決定から劇場公開までの間、広告効果を含めた映画人口への浸透度をモニターするシステムも確立されています。
このように同社ではすでにデータマイニングの活用は定常化されており、ビジネス要件が明確になっていました。そこで現在実施中のコンサルティング・プロジェクトでは、これまでのデータマイニング・プロセスをSPSSが推奨するCRISP-DM手法に沿って再現、整理し、改良を行っていくというファイン・チューニングが主目的となっています。
データの理解・準備
ギャガ・コミュニケーションズには、KISS、LINDA、ADAM、CINEMA RESEARCH 2000の4種類のデータベースがあり、それぞれ目的に応じた情報を分けて管理、運用しています。
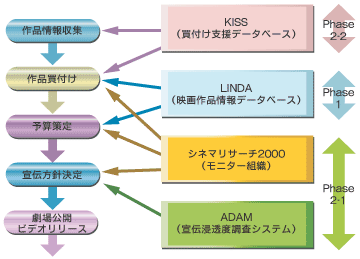 図1 ギャガ・コミュニケーションズのワークフローと各システムの関係
図1 ギャガ・コミュニケーションズのワークフローと各システムの関係■KISS
KISSは、買い付け作品情報のデータベースです。買い付け対象となり得る海外映画作品の企画段階から完成までの各ステージにおける進ちょく情報などを管理のうえ、買い付けに関連する一連のデータを一元化しています。
■LINDA
LINDAは、興行収入予測のための情報を登録したデータベースで、監督や主演俳優などの作品情報、米国での興行成績や評価、広告費、国内における実績などに関する情報を持っています。
■ADAM
ADAMは、Webアンケートによって集められた各映画作品に関する宣伝浸透度や観賞意欲度の情報を管理しています。
■CINEMA RESEARCH 2000
CINEMA RESEARCH 2000は、事前の試写会などでモニター調査を行うことにより、配収予算や宣伝プランの策定の際の参考情報としています。また当該データベースにより、宣伝材料(ポスターなど)の評価を通じた宣伝方向の確認なども行っています。
モデリング
ここでは、進行中のこのデータマイニングプロジェクトで実施されたモデリングの中で、前述のLINDAデータベースにおける既存モデルの改良と拡張に絞ってその概要を説明します。ここではモデリングステップを以下3つのフェーズに分けています。
・第1フェーズ
まずLINDAデータベースでの既存の予測モデル(線形回帰)をClementineで再現し、モデルの長所・短所を評価しました。既存のモデルの精度は高く、例えばモデルがなければ興行収入40億円の作品を10億円しか稼がないと予測してしまうところ、モデルを使うと37億円という数値を導き出せる程度の精度があります。
プロジェクトでは、再現されたモデルの特徴を理解したうえで、検証済みの精度をモデリングの評価基準として比較検討を行いました。次に、Clementineで利用可能なほかの手法(ニューラルネットワーク、決定木)を使ってモデリングを行い、比較検討しました。
また、ADAMデータベースでは既存モデルとして認知度と意欲度の散布図を作成していましたが、グラフ内での作品プロットの動きが実際の興行収入と一致した動きをしていないということが問題になっていました。例えば興行収入50億円の作品と20億円の作品がグラフの近い位置にプロットされていたりするわけです。そこで、それぞれの変数と実興行収入との相関が高くなるよう、変数を分解、重み付け、統合を行いました。
ニューラルネットワーク
脳や神経系の仕組みを応用したモデルである。データマイニングにおいては、精度を基準として自動的に反復計算を行うマシンラーニングに分類される。あらゆるタイプのデータに対応することができ、非線形の関係をも検出可能な、予測モデルとして知られている。
決定木分析
マシンラーニングに分類される、あらゆるタイプのデータに対応可能な予測モデルである。樹木のような図形出力を生成することから分析名を決定木という。特徴として、非線形の関係も含めての要因特定、セグメンテーション、高次の相互作用の検出などが挙げられる。
・第2フェーズ
LINDAについては第1フェーズで選択されたモデルを参考に、決定木での予測モデルを作成、改良し、興行収入予測ランクが低・中・高となるパターンを検出しました。これにより、キャスト、ジャンル、米国での興行収入実績などの組み合わせから、公開劇場チェーン、広告費をどの程度にすれば、日本での興行収入が中ランク(例えば10億から20億円くらい)になるといった予測することができます。
ADAMでは、実興行収入の高い作品が多く分布する、しかも興行収入との相関が高いエリアを検出し、これをセーフティ・ゾーンとしました。この段階では、例えばセーフティ・ゾーンに達した作品については、興行収入30億円が期待できるということが判断できるわけです。
・第3フェーズ
LINDAとADAMを統合してのモデリングが行われています。LINDAではかなり高い精度の予測モデルがすでに作成されていますが、さらにこのモデルでの残差について、ADAMからの情報を用いて再分析し、予測モデル改善の余地、あるいは興行収入と浸透度の関係が考察されています。
また、LINDA単独では、興行収入予測モデルは既存のビデオ販売収入予測モデルと結合されました。このモデルは、1つの作品が映画として公開されてからビデオとして販売されるまでの総収入を予測するものであり、広告費の予算策定を行う際に、非常に貴重な情報となるものを提供していることになるわけです。
ADAM単独では、第2フェーズで作成された浸透度のプロットをさらに精緻化する試みが行われました。第2フェーズまでの出力からは、セーフティ・ゾーン付近に位置する作品については感覚的に浸透度の良しあしを判断せざるを得ませんでした。この問題を解決するために、セーフティ・ゾーンの閾値の信頼区間を統計的に算出し、これをグレー・ゾーンとしました。現状では、グレー・ゾーンにも入らない作品が時間的推移を経てセーフティ・ゾーンまで到達するパターンを作品ごとに確認しています。ここで何らかのパターンが検出されれば、例えば公開1週間前にはグレー・ゾーンに位置していないと、公開週にセーフティ・ゾーンに達することはまずないという推測が可能になります。このフェーズは現在、引き続き進行中です。
評価
統計的な観点からのみならず、モデルそのものの理解しやすさ、ビジネスフローに沿った解釈ができるか、システムとして導入するに十分に簡便な手続きでモデルを利用することができるか、などから評価を行いました。
展開
例えばLINDAデータベースでの決定木モデリングから、キャスト、ジャンル、米国興行収入実績などの組み合わせにより、公開劇場チェーン、広告費をどの程度にすれば、日本での興行収入がいくらになるかを予測することができます。
これらの全組み合わせが帳票としてデータベース化され、迅速に検索できるシステムが確立されています。これを利用して、映画の作品力に米国での実績が情報として加わると、採算ベースに乗せるためにはどの劇場チェーンで公開し、どれだけ広告を打てばよいのか意思決定する際のかなり信頼性の高い情報が得られることになります。逆に、広告費を伸ばしても収益に影響がないと予測されれば、過剰な投資を防ぐためのリスク回避にもなります。さらに、広告費の投入量を大きくすれば興行収入が高くなるということがあらかじめ分かっていれば、作品公開資金の調達手段としてジョイント・ベンチャーを組むといったような戦略を取ることもできます。
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 江崎グリコ、基幹システムの切り替え失敗によって出荷や業務が一時停止
- 生成AIは2025年には“オワコン”か? 投資の先細りを後押しする「ある問題」
- Microsoft DefenderとKaspersky EDRに“完全解決困難”な脆弱性 マルウェア検出機能を悪用
- 「Copilot for Securityを使ってみた」 セキュリティ担当者が感じた4つのメリットと課題
- 「欧州 AI法」がついに成立 罰金「50億円超」を回避するためのポイントは?
- 日本企業は従業員を“信頼しすぎ”? 情報漏えいのリスクと現状をProofpointが調査
- 「プロセスマイニング」が社内システムのポテンシャルを引き出す理由
- AWSリソースを保護するための5つのベストプラクティス CrowdStrikeが指南
- VMwareが「ESXi無償版」の提供を終了 移行先の有力候補は?
- トレンドマイクロが推奨する、長期休暇前にすべきセキュリティ対策
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。