年々難しくなる「障害検知」のコツ:システム管理入門(6)(2/2 ページ)
監視ツール、2つのタイプ
ただ、どのメーカーの監視ツールを導入する場合でも、監視対象は大きく2種類に分けられます。それは、次の2種類です。
(1)「使えるか使えないか」という、0か1かの監視
(2)しきい値を設定することで障害を検知するタイプの監視
(1)は簡単です。ハードウェアの物理的な故障や、それが引き金となってのネットワークの寸断は、「使えるか使えないか」の世界ですから比較的分かりやすいと言えるでしょう。pingなどを使ってサーバのヘルスチェックを行い、ping が到達しなければ「障害」とみなします。この場合は、「何を監視するか」ということが重要な要素となります。
一方(2)は、CPU使用率、メモリ使用率、ハードディスクの空き容量、ネットワークのトラフィック量など、本来「性能管理で監視すべき範ちゅうのものを監視しよう」というものです。
これはサーバの一部の機能がダウンしたためにサーバが縮退運転を開始し、結果として過負荷が発生したり、逆に過負荷が原因でサーバがダウンしたりする、というような場合もあるためです。
つまり、障害によって性能が悪くなる場合、性能を監視することで障害を検知できますし、同様に、性能を監視することで、障害が起こる可能性を、実際に障害が発生する前に知ることもできるのです。
先日、こんなことがありました。あるサーバのレスポンスタイムが極端に遅くなったのですが、実際には、ある日突然遅くなったのではなく、徐々に徐々に遅くなっていました。調べると、CPU使用率が常に80%を超えていました。しかし、特にそのサーバの処理件数が増えているわけではありませんでした。
そこでよくよく調べてみると、サーバの冷却ファンの部分にホコリがたまり、冷却効率が悪くなってCPUの温度が上がったために、CPUが熱暴走を起こさないように縮退運転をしていたことが分かりました。そのとき使っていた監視ツールには、筺体内の温度やCPU温度を監視する機能がなかったため、そのことに気付かなかったのです。結局、そのホコリを取り去ることでサーバは元通り元気になりましたが、そのままこのサーバを使い続けていたら、ある日突然、熱暴走していたかもしれません。
「何を監視するか」「何をもって障害とするか」が大切
また、この(2)の場合は、「何を監視するか」ということに加えて、「何をもって障害、もしくは障害の可能性とみなすか」という、しきい値の設定が特に重要になります。例えば、単に「サーバのCPU利用率80% 以上」というのをしきい値にしてしまったら、一時的な過負荷も検知の対象に入ってしまうことになります。その都度サーバを調べるのは作業として負荷が掛かりますし、「また問題なかった」ということが何度も起きると、障害検知がいわゆる「オオカミ少年」になってしまって、本当に障害が発生したときに役に立たない、ということもあり得るからです。よって、「サーバのCPU利用率80%以上が30分以上続く」といったしきい値の方が理にかなっていると言えます。
また、この「80%」とか「30分」というような設定も妥当なものかどうかは、きちんと記録を取った上で3カ月、もしくは半年単位で見直しを行った方が良いでしょう。
極端な例ではありますが、下記は平成21年の情報処理試験(ITサービスマネージャ)で出題された問題の一部です。試験問題なのでもちろんフィクションですが、これに似たような話は十分あり得ます。
情報処理技術者試験「ITサービスマネージャ(平成21年秋)」問3より
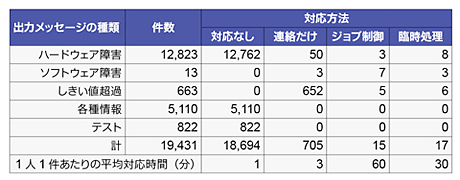
ハードウェア障害で、対応方法を「対応なし」としている出力メッセージの大部分は、店舗の端末障害を示すものであった。これは、オンラインサービス開始時に電源が入っていなかったり、レジ系の交換時にいったん電源を切る運用になっていたりすること、などに起因するものであった。
しきい値超過で対応方法が 「連絡だけ」となった出力メッセージのほとんどは、運用管理システムから出力される、CPU使用率のしきい値超過による警告メッセージであった。
システム運用部では、表中で、対応方法が「対応なし」及び「連絡だけ」である出力メッセージに対する運用オペレータの対応工数を削減するために検討を開始した。まず、「対応なし」のメッセージ件数を削減することによってもたらされる工数の削減について検討し、次に、「連絡だけ」のメッセージ件数を削減することによって改善される工数の削減について検討した。
この問題では、合計で 2万2219分を出力メッセージの対応に追われていることになります。しかし、表をよく見ると、「ハードウェア障害」のメッセージへの対応時間、1万2762分は、本来であれば対応する必要のない 「対応なし」の処理に掛かっています。これは「ハードウェア障害のメッセージが出力される条件」を吟味すれば減らせる可能性が高いということです。
また、連絡だけで済む「しきい値超過」の対応にも652件×3分=1956分が掛かっています。これも、しきい値を調整することで削減できる可能性があります。「ハードウェア障害」と「しきい値超過」、それぞれのメッセージへの対応時間を半分に減らすことができれば、合計で7,359分、約122時間を削減できることになります。
障害監視の設定をした場合は、その監視結果と対応の種類を、上記の表のようなスタイルで必ず記録しておき、定期的に見直す仕組みを設けておく方が良いでしょう。
次回は、障害対応についてお話しします。お楽しみに。
著者紹介
▼著者名 谷 誠之(たに ともゆき)
テクノファイブ株式会社 阪神支社 ラーニング・コンシュエルジュ。IT技術教育(運用系/開発系)、情報処理試験対策(セキュリティ、サービスマネージャ、ネットワークなど)、対人能力育成教育(コミュニケーション、プレゼンテーション、チームワーク、ロジカルシンキングなど)を専門に約20年にわたり、活動中。「講習会はエンターテイメントだ」を合言葉に、すぐ役に立つ、満足度の高い、そして講義中寝ていられない(?)講習会を提供するために日夜奮闘している。
ディジタルイクイップメント株式会社(現:日本HP)、グローバルナレッジネットワーク、ウチダスペクトラム、デフォッグなどを経由して現職。
テクニカルエンジニア(システム管理)、MCSE、ITIL Manager、COBIT Foundation、話しことば協会認定講師、交流分析士1級などの資格や認定を持つ。近著に『高度専門 ITサービスマネジメント』(アイテック、2009年6月)
がある。
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 江崎グリコ、基幹システムの切り替え失敗によって出荷や業務が一時停止
- Microsoft DefenderとKaspersky EDRに“完全解決困難”な脆弱性 マルウェア検出機能を悪用
- 生成AIは2025年には“オワコン”か? 投資の先細りを後押しする「ある問題」
- 「Copilot for Securityを使ってみた」 セキュリティ担当者が感じた4つのメリットと課題
- 「欧州 AI法」がついに成立 罰金「50億円超」を回避するためのポイントは?
- 日本企業は従業員を“信頼しすぎ”? 情報漏えいのリスクと現状をProofpointが調査
- 「プロセスマイニング」が社内システムのポテンシャルを引き出す理由
- AWSリソースを保護するための5つのベストプラクティス CrowdStrikeが指南
- トレンドマイクロが推奨する、長期休暇前にすべきセキュリティ対策
- VMwareが「ESXi無償版」の提供を終了 移行先の有力候補は?
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。