「笑い」や「興奮」も分かるコンピュータ:こばやしゆたか(2/2 ページ)
まず、マッチングではないから速度が速い。メモリもあまり使わないので携帯電話にも搭載できる。そして、どんな信号を入れてもそれなりに答えが返ってくる。入力信号に音楽を入れてしまう実験もあったのだけど、それなりに感情を認識していた。
半面、関数は既にできあがってしまっているから、その場で学習していくということはやりにくい(パラメータを微妙にいじるくらいのことはできるだろうが)。
今回のVer 2.0では、このSTが深化した。いままで「喜び、怒り、哀しみ、平常」の感情を認識していたのが、それに「笑い、興奮」が加わるようになった(*4)。これによって59〜65%の認識率を得られるようになったのだそうだ。AGIによれば、人間の自然発話による感情認識率は(言葉の意味も含んで)60〜70%なので(*5)、ほぼそれに近いところまで来た。
また、Ver.1は一度には一つの感情しか認識しなかったのだけど、これが多感情同時認識をするようになった。「泣き笑い」なんていうのがアリになったわけだ。実際には、それぞれの感情がどのくらいの強さで認識されたかが得られるので、それを見て最終的にどういう感情なのかを決定するのはアプリケーション側の仕事だ。
そして、SDKがリリースされた。このSTをライブラリとしてアプリケーションに組み込むことができるようになったのだ。さっきも言ったように心臓部は「関数」なので、その中身をいじることはできない。それを作るのに使ったデータベースも見られない(このあたりは企業秘密だ)。
SDKは、まずWindows版が10月18日に発売。100万円(保守費:20万円)。Linux版も追って発売(*6)。
デモとして、このSDKに含まれるサンプルアプリケーションを使った感情認識の実際を見せてくれた(*7)。アナウンサーは“平常”(興奮もずっと一定値)で、オリンピックでの喜びのインタビューは“喜び”と認識。
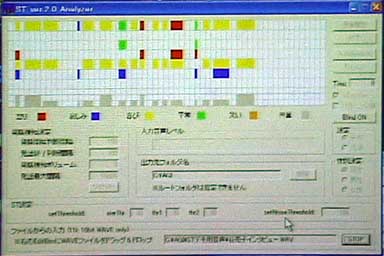 金メダリストのインタビューの認識結果。黄色で示されているのが「喜び」
金メダリストのインタビューの認識結果。黄色で示されているのが「喜び」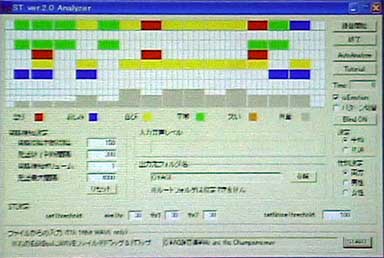 おまけ。QUEENの“We Are The Champion”のサビの周囲を入れた結果。緑は平静、赤は怒り。最上行の長い黄色の部分が「We Are The Champion!」のところになる)
おまけ。QUEENの“We Are The Champion”のサビの周囲を入れた結果。緑は平静、赤は怒り。最上行の長い黄色の部分が「We Are The Champion!」のところになる)今後は、受付嬢のほか、音声入力のついた次世代ゲームマシン用のゲームや、携帯電話のコンテンツといった分野への使用が計画されているそうだ。
*4 「興奮すると声が大きくなる?」と聞いたのだけど、それだけでは「マイクからの距離が変わったら検出できなくなります。ピッチが高くなる? それだけでもないです。この辺がノウハウ」だそうだ。
*5 出典不明。
*6 もっと安いパーソナルなエディションもほしいと言ったら、「考えている」そうだ。アマチュアのオタクたちにSTをつかわせたら変なものが出てくるんじゃないかと思うのだけど。
*7 サンプルデータの著作権があるので、公開できない。
関連記事
 霧のスクリーンからケンカするコンピュータまで〜「IVR2004」
霧のスクリーンからケンカするコンピュータまで〜「IVR2004」
東京ビッグサイトで「産業用バーチャルリアリティ展」が開催されている。「設計・製造ソリューション展」「機械要素技術展」との併催で、会場面積は全体の9分の1程度しかないのだけど、そこにわたしの好きなものがあるのだ。 ゲームのキャラと口げんかできる――“感情”を読み取る音声認識エンジン
ゲームのキャラと口げんかできる――“感情”を読み取る音声認識エンジン
「PS6」の実現に一歩前進?声のトーンからユーザーの感情まで判断し、適切なレスポンスを返せるという音声認識技術が登場した。ゲームキャラと感情のこもった会話ができ、「ナイトライダー」の「キット」のようにドライバーと会話をしながら適切な判断ができるエージェントの開発にも応用可能だ。- レスキューロボット、実用化への道――消防隊員がトライ
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PR


![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。