監視と検知が可能にする迅速なインシデント対応:ネットワーク運用におけるセキュリティ(1/4 ページ)
さまざまなIT事故による被害を最小限に抑えるには、迅速に事故を「発見」することが重要なポイントとなる。その重要な手段である「監視」と「検知」の技術について紹介しよう。
過去の記事「まずはセキュリティの基本的な考え方から理解する」および「SOCを例としたインシデント対応のポイント」も参照ください。
不正アクセスをはじめ、運用やセキュリティに関わる事故は後を絶たない。そして、事故が発生しているにもかかわらず、それに気付かなかったがために影響が拡大してしまうケースも少なくない。被害を最小限に抑えるには、迅速に事故を「発見」することが重要なポイントとなる。その重要な手段である「監視」と「検知」の技術について紹介しよう。
監視と検知
あなたは、自分が管理しているサーバやネットワークで何が起こっているか把握できているだろうか。また、インストールしたはいいけれど、パッチの適用やバックアップといった最低限の日々の運用を行っているだけで、あとはほったらかしになっていないだろうか?
現状を把握していないと、トラブルが発生した場合に以下のような問題が発生する。
- 状況の把握を行ってからでないと対応が行えない。したがって対応が後手に回る
- 正常時の状況を把握していないと「何が異常なのか」の切り分けができず、対応に時間がかかる
つまり一口で言えば「イケてない」状況になってしまう。このような「リアクティブ」な事態に陥らないためには、日々の監視/検知が重要だ。
サーバやネットワーク機器、セキュリティ機器の運用を行う際に、どうやって障害を監視、検知し、対応するかを表したものが図1である。
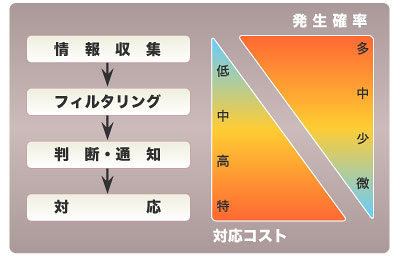 図1●監視・検知のフロー(出典:インターネット セキュリティ システムズ)
図1●監視・検知のフロー(出典:インターネット セキュリティ システムズ)1.情報収集
判断材料となる情報がなければ、そもそも何が起こっているかさえ把握できない。どのような方法で情報を収集するかを考える必要がある。
2.フィルタリング
情報の質が低かったり、あるいは量が多すぎる場合、それほど重要でない大量の情報の中に重要な問題がまぎれてしまい、結果としてこれを見逃す可能性が高くなる。逆に、詳細な分析を行う際に、必要な情報が記録されていないこともある。ここでは、状況証拠を収集するための情報と、対応のトリガーとする情報を明確にしておくことがコツといえる。
3.判断/通知
重要と思われる情報を把握したら、その緊急性を判断し、適切な部門や担当者に通知を行う必要がある。夜中であろうが休日であろうが、必要な場合には連絡を取らなければならないのだが、これはどちらにとっても心理的な負担が大きい。どのようなケースで誰に連絡を取るかをあらかじめ明確にしておき、機械的に連絡が流れるようにすることが望まれる。
4.対応
対応のフェーズは千差万別だが、ぜひここで「悲観的に準備し、楽観的に実施せよ」という言葉を思い出してほしい。事故対応のケースでは、情報が誤って解釈される場合が多い。どうでもよいことに過剰に反応してしまうことも少なくない。まず最悪のケースを想定し、優先順位に基づいて準備を迅速に行い、後は楽観的に作業を進めるようにする。
情報収集とフィルタリング
最終的な判断、対応の詳細はケースや環境によって異なる。ここでは、情報収集とフィルタリング/通知という2つのステップについて、実例を交えながらポイントを紹介する。
ここでは、判断材料となる情報を大きく2つに分けて考えていこう。
1. 監視対象機器自身が発するメッセージ
2. 監視対象機器を監視しているNMS(Network Management System)などが生成するメッセージ
2.のジャンルには「hp OpenView」などの商用アプリケーションのほか、「MRTG」「RRDTool+Cacti」「Nagios」といったGPLライセンスに基づくフリーソフトウェアがある。これらについて紹介しているWebページも多数あるので、詳細は割愛させていただく。ただし、イベントフィルタリングや通知の考え方には共通の部分が多いため、参考になる点もあると思う。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- Microsoft、「Copilot Cowork」の一般提供を開始 プロンプト単価は競合比で約4割安価に
- Claudeをかたる攻撃がアジア太平洋地域で多発 偽広告から不正コード実行へ
- 日立はAX事業にどう臨む? 徳永CEOの話から「成長につなげるための勘所」を探る
- Microsoftが警告 「最新サイバー脅威」の手口と対応策
- Copilotの“元”は取れるのか問題、ついに決着? 住友商事、京都市が掴んだ「AI活用の勝ち筋」
- 7割超の企業はシャドーAIを管理できていない ガートナーがガバナンスの現実解を提唱
- 日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
- 月2000時間のムダをどう削った? 大阪ガスらを変えた「Notion×AI」で情報を資産化する方法
- ネットワークもエージェント型へ HPEのArubaとMistの共通化で運用はどう変わる
- 「内製化の目的はコスト削減」 54.5%が犯す“間違い”をガートナーが指摘
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。