「ビッグデータという呼び方は嫌いだ」とTeradataのブロブストCTO:Teradata PARTNERS 2013 Report(2/2 ページ)
「Hadoopオープンソースの取り組みは素晴らしいが、それだけではデータから価値を引き出すことは難しい。Hadoopでは、エンジニアがMapReduceフレームワークでプログラミングする必要があるからだ」とブロブスト氏。
Teradataが買収したAster Data Systemsは、スタンフォード大学の学生寮から生まれた。プログラミングに精通したエンジニアでなくとも、ビッグデータという無限の宇宙の中から新たなビジネスチャンスを見つけ出せるようにしたい、という学生のアイデアが始まりだった。彼らのnClusterデータベースは、安価なIAサーバでクラスタを構築し、「SQL-MapReduce」フレームワークによって、使い慣れたSQL操作でビッグデータ分析を並列処理させることができた。
Teradataによる買収後、AsterはHadoopとの統合が進められ、「Aster Big Analytics Appliance」もリリースされたほか、Teradata、Aster、そしてHadoopという3種類の並列処理型データベースをシームレスに連携できる「Unified Data Architecture」(UDA)では、「ディスカバリープラットフォーム」としてその中核をなしている。
データの「実験」を担うデータサイエンティスト
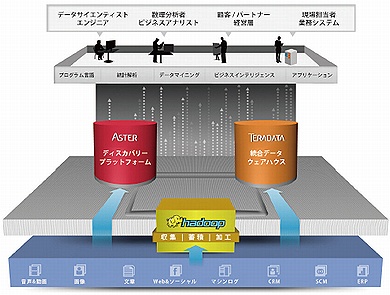 TeradataのUnified Data Architecture
TeradataのUnified Data Architecture「われわれのビッグデータに対するアプローチは、UDAだ。1つのテクノロジーでは、膨大かつ多様なビッグデータから価値を見つけ出し、より良いアクションに結び付けていくのは難しいからだ」とブロブスト氏。
UDAは、統合データウェアハウスのTeradata、ディスカバリープラットフォームのAster、データプラットフォームとしてのHadoopを適材適所で活用するアプローチだ。
いま最もセクシーともてはやされている「データサイエンティスト」の仕事は、仮説を立て、膨大かつ多様なデータの中から例えば、購買に結び付くパターンを見つけ出すこと。その「実験室」のツールとしては、コンピュータのエンジニアではなくても分析処理できるAsterが適している。一方、データサイエンティストが見つけ出したデータへの「問い」を活用し、ビジネスの課題を解決し、価値を引き出すのはビジネスアナリストだ。
「Hadoopに取り込んだビッグデータを素材とし、Asterという実験室で研究開発し、Teradataという工場で商用化してデータの価値を引き出していく」(ブロブスト氏)
人材不足が懸念されているデータサイエンティストだが、ブロブスト氏は、応用化学や応用物理学、あるいは社会学を学んだ人たちが向いているのではないかと指摘する。
「大学の研究室で埋もれてしまっている能力がデータサイエンティストとして生きるはず。わたしは甥(おい)にも“データサイエンティストになれ”と言っている」とブロブスト氏は笑う。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 開発者が突然「2026年はあの定番データベースをやめろ」と言い出した理由とは? 愛された技術の裏事情
- KDDIの最大1422万件の情報漏えい事件 その裏には陸自USB問題と同様に中国の影?
- AIはITエンジニアを淘汰しない Microsoft調査が示す、AI委任とキャリアの好機
- FDEとリコーの新コンサルサービス、どこが違う? AXのパートナー選びを考察
- 北陸電力は紙と手入力をどう“捨てた”? 年間で3万時間削減
- 住信SBIネット銀行、勘定系をクラウドに全面移行 コスト30%削減の鍵を握る「次世代基盤」とは
- たった1件の不備でマイナス1万点 AIの物量攻撃に耐える“基礎の強度”
- AWSの「静かな」戦略シフト OpenAIとAnthropic“1日違い登壇”の意味を読み解く
- 世界のランサムウェア攻撃、4217件に データ流出規模の上位5件を占めた国は?
- スマホはもはや「実印」? パスワード870件分の警告をAIはどう救うのか
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。