第1回 オペレーションを変えるマシンデータの活用とは?:実践 Splunk道場(2/4 ページ)
マシンデータとは何か
マシンデータはいろいろなところで記録されている。Webサーバ、メール、データベース、セキュリティデバイスが吐き出すログやパケット、さまざまな計器のログ、センサー情報や設定ファイルなど多種多様だ。ここでまず課題が生まれる。大量のデータを読み込みたいのはいいが、そのようなさまざまな形式のマシンデータをどのように扱うのか。また、データが理解できなければ経営にとっても大きな課題になるのは必然だろう。ある顧客のケースでは、さまざまなデバイスからのマシンデータのフォーマットが4万3000種類に及んでいた。

もしリレーショナルデータベースに取り込むのであれば、データベース側に4万3000種類のフォーマット、すなわちスキーマを用意しなければならなくなる。しかも、データフォーマットはアプリケーションやセンサー、モバイルのソフトウェアの変更や躍進によって毎年増え続けていくという始末だ。
この課題を解決すべくSplunkは、シンプルにデータをそのまま取り込めるようにしている。今まではデータ取り込みのスキーマの定義に膨大な時間を費やしていたが、簡単に取り込むことで、取り込んだデータに対して必要な情報だけを後付けで定義し、必要に応じてその都度扱う。
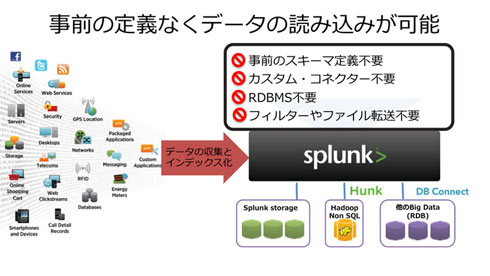
データは「Key=Value」ペアで表す。Keyの部分は、いわゆるテーブル構造の先頭行の列名を表し、Valueは実データを表す。後で触れるが、Splunkのサーチ機能の中で、このKey=Valueペアを動的に組み込むこともできる。この動的な動作を「スキーマオンザフライ(Schema on the Fly)」と呼んでいる。その瞬間にスキーマが現れてサーチが実行され、サーチを終えるとスキーマが消える。Map Reduceや分散ファイルシステムのアーキテクチャ構成によって、多様なフォーマットのデータを柔軟かつ高速に処理している。ビジネスに「速度」を与えることが大きなメリットとの考えからである。
関連記事
 「あけおめメール」に備えろ! KDDIが装備したデータ分析基盤とは?
「あけおめメール」に備えろ! KDDIが装備したデータ分析基盤とは?
元日になった瞬間に飛び交う「あけおめメール」は、トラフィックを圧迫される通信事業者にとって、実に悩ましい存在だ。年末年始に向けてKDDIが約2カ月で構築した秘策とは? 怪しい動きは自社でも調査 大成建設に聞くセキュリティの取り組み
怪しい動きは自社でも調査 大成建設に聞くセキュリティの取り組み
昨今のセキュリティ対策ではサイバー攻撃などのインシデント(事故や事件)へ迅速な対応をできることが強く求められている。大成建設はそのためのチーム「T-SIRT」を2013年に結成した。T-SIRT誕生の経緯や日々の活動とはどのようなものか――。- 理化学研究所、ログ分析の効率化に「Splunk」を試験導入
理化学研究所は、ネットワークサービスのログ管理を効率化するために、NTTデータが販売するログ管理ツール「Splunk」を試験導入する。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- PC需要がついに縮小 IT部門を揺さぶる「値上げ」の理由は?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 多要素認証も飛び越えるフィッシング iOS 27の"新たな防波堤"
- AIエージェントのコスト、どこに「消えて」いる? Google Cloud調査で浮上した“クラウド利用の盲点”
- 6.5年かかるコード解析を20時間で完了 4.6億行のレガシーコードに挑んだClaude活用術
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 「足りないのはCOBOL人材じゃない」 日立が語る、AI時代のシステム刷新における“人”の役割
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。