インメモリDBの「SAP HANA」、Intelの不揮発性メモリに正式対応 サーバダウン時もデータを失わず高速起動:Publickey(3/4 ページ)
メインストアとは、リード処理に最適化されたカラムストア
SAP HANAのデータベースは、3つの領域「L1デルタ」「L2デルタ」「メインストア」に分かれています。
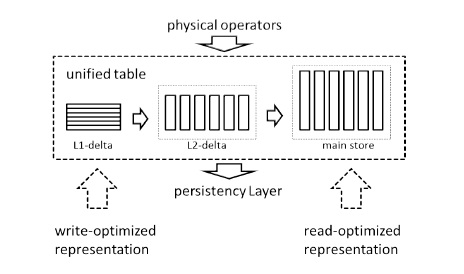 HANAのカラムストア「Efficient Transaction Processing in SAP HANA Database - The End of a Column Store Myth」から引用
HANAのカラムストア「Efficient Transaction Processing in SAP HANA Database - The End of a Column Store Myth」から引用このメインストアが、SAP HANAのデータベース本体といっていい領域です。そしてSAP HANAのメインストアは、データを列ごとに管理する「列指向データベース」あるいは「カラム型データベース」と呼ばれる構造となっています。
通常のリレーショナルデータベースは、データを「行」で管理し、行ごとにデータの追加・削除・更新などを行うのに対し、カラム型データベースによって、列方向でデータを管理する利点は、列方向には同じ種類のデータが並んでいるため、データの圧縮効率が高くなり、列方向に計算を行う集計処理なども高速に行えることです。すなわち、カラム型データベースは大量のデータの分析処理を高速で行うことに向いているのです。
カラム型データベースの特長については、下記の記事を参照してください。
しかし、カラム型データベースは通常のリレーショナルデータベースで行われる行の追加や削除といった行単位の処理、トランザクションは苦手です。その処理には非常に時間がかかります。
SAP HANAではこれを克服するため、カラム型データベースであるメインストアの手前に「L1デルタ」「L2デルタ」の2つの領域を設けているのです。
L1デルタの内部は、通常のリレーショナルデータベースと同様に「行」指向でデータが管理されています。アプリケーションからのデータベースに対する行の追加・削除・更新などの処理は、このL1デルタ内で高速処理されます。そして、L1デルタで処理が完了すれば、外部からはSAP HANAがトランザクションを高速に終えたように見えます。
ただし、SAP HANA内部ではまだ処理は終わっていません。L1デルタに書き込まれた内容は、バックグラウンドでL2デルタに変換されます。L2デルタはカラム型データベースの形式になっています。そして、L2デルタでカラム型に変換されたデータは、最後にメインストアにマージされます。
SAP HANAの内部構造については、下記の記事を参照してください。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 大手コンサル15社も「対応できない」 なぜ、ある大企業はシステム刷新を断られたのか?
- なぜ「おじさん人材」が選ばれる? 新卒採用が鈍化するIT部門の実像
- Windows 11、Dell製PCの不具合を修正する緊急パッチを配信 自動配信の条件と手動の導入手順は?
- 「Windows+R」は絶対に押さないで! 2026年Q1「Microsoft」記事トップ10
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Copilotの“元”は取れるのか? 住友商事らに学ぶ、投資判断の「物差し」
- 「AI使うなら値引きできる?」の“暴論”に、日立はどう立ち向かう? レガシー刷新でのAI活用の現在地
- AIエージェント時代、なぜデータ基盤の進化が求められるのか? 次世代アーキテクチャの基本を解説
- ドローンいらず? 飛行動画作成できる「Google Earth Studio」登場
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。