UMLモデリングのノウハウ、最後の秘訣(UMLモデリングの開発過程 開発編その2):【改訂版】初歩のUML(13)
今回は第12回「UMLモデリングの開発過程(開発編その1)」の続きです。自動車専門部品販売店(RacingObjective社)を例に、引き続きアーキテクチャ設計を中心に話を進めていきます。ところで、「初歩のUML」もいよいよ今回が最終回となりました。皆さん、もう少しでゴールです。頑張って読み進めてください。なお、前回から引き続き、表1の作業内容に沿って解説を行っていきます。
| ディシプリン名 UP(統一プロセス) |
ディシプリン名 (本連載での名前) |
チーム名 | 作業内容 (作業観点) |
| 要求と分析 | ・システム分析 ・要求分析 |
システム分析チーム | (1) システム範囲を決める (2) システム要求を定め、管理する (3) 要求の概念構造のモデル化 |
| 設計 (前半) |
システム設計の初期段階 | アーキテクトチーム | (4) アーキテクチャのプロト検証 (5) コア・アーキテクチャの確立 |
| 設計 (後半) |
システム設計の後半 | 設計・実装チーム | (6) システムの詳細設計・実装・テスト |
| 表1 チームによるディシプリンの実施 | |||
(4)アーキテクチャのプロト検証
この作業は、システム設計という観点で、アーキテクトチームが中心になって行う作業です(図1)。
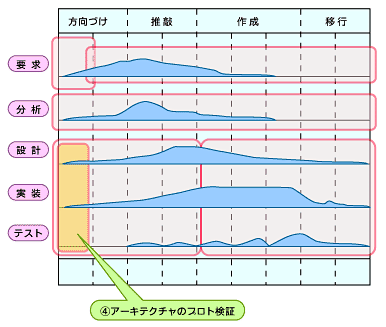 図1 アーキテクチャのプロト検証
図1 アーキテクチャのプロト検証アーキテクチャのプロトタイプを作ることで、推敲(すいこう)フェイズに実現すべきコア・アーキテクチャのベースを確認します。これは、第10回「開発プロセスの上手な組み合わせ」でも説明したとおり、コア・アーキテクチャの上にユースケース単位でインクリメンタルに積み上げていくというのが反復開発の本質となります。もしもコア・アーキテクチャに根本的な問題が発生すると、反復のたびに積み上げられるユースケース機能が不安定になってしまい、以降の反復計画に大きく悪影響を及ぼしてしまいます。
そこで、ユースケース機能を載せる前に、コア・アーキテクチャを安定させることを目的として、ミドルウェアの検証および選択や、アーキテクチャを実現するための各種コンセプト・メカニズムの部分検証を行うのが、この段階におけるプロトタイピングの目的となります。
ここで重要なことは、人は誰でも最初から優れたアーキテクチャは作れないということです。よって新たなドメイン(領域)や新技術を酷使するようなプロジェクトでは、この作業は非常に重要なものとなり、まさにリファクタリング(少しずつよい設計と実装に変えていく)の精神で、取り組んだ方が良い結果が出るものです。よって、アーキテクチャを説明するモデルについても徐々に改善がなされていきますので、初めからあまり詳細な図を描かない方がよい場合があります。ここでのアプローチとしては、簡単なクラス図と、ホワイトボードに描いたシーケンス図程度で、モデルを実装に落とし、動かし、またモデルを改善するというアジャイル(敏速)さが必要とされます。
プロトタイプの開発においては、プロトタイプのゴールを明確に定め、必要最低限の検証にとどめるようにしましょう。また、複数の課題(例えばミドルウェアの検証と画面遷移の検証)を並行して行わせることで時間を短縮するということも検討しなければなりません。
具体的な検証項目については、次のコア・アーキテクチャの確立における課題と一緒に説明します。
(5) コア・アーキテクチャの確立
コア・アーキテクチャの確立とは、システム設計という観点で、アーキテクトチームが中心になって行う作業です。アーキテクトチーム内では、アーキテクチャのプロト検証と並行させることになります。
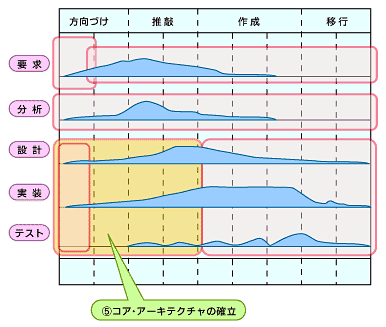 図2 コア・アーキテクチャの確立
図2 コア・アーキテクチャの確立アーキテクチャのプロト検証は、コア・アーキテクチャの確立をスムーズに行うために、先に検証すべき課題を取り上げて実際に動かしてみるものでした。コア・アーキテクチャの確立とは、プロトタイプによって検証された個々のアーキテクチャを統合して、システム全体のコア・アーキテクチャ(アーキテクチャルベースライン)を確立するものです。この作業は、システムに対する非機能要求の実現方式がテーマになることが多いでしょう。
非機能要求とは、ユースケースでは説明できない機能的ではない要求のことで、例えば、パフォーマンス要求や、再利用性・拡張性の要求、信頼性の要求などです。かなり具体的な内容まで提示した形で非機能要求をまとめ、それの実現方式を決定し、コア・アーキテクチャを検証・実装していくのです。具体的なアーキテクチャとしては、非常に複雑な業務ロジック、ビジネスを左右しかねない重要な画面遷移の洗練化・具体化、まだ経験のないアーキテクチャの採用、高パフォーマンスを要求されるユースケースの実現方法、Webサービスによるビジネス連携のビジネス方式も含む検証など、さまざまなものがターゲットとなります。
このほか、コア・アーキテクチャの確立ではさまざまな重要事項の決定を行わなければなりません。アーキテクトチームが中心となり、確立されたアーキテクチャを利用するためのガイドライン作りや、開発ツールを前提とした開発手順作りなど、作成フェイズで、複数のサブシステム開発がスタートするための前準備として、統一的な思想・やり方でソフトウェア開発を進めていくためのパターンを確立することが重要なのです。データベース設計についてもサブシステムで共通的なデータモデルを確立する必要がありますのでこのフェイズで設計を行います(コラム参照)。
さて、今回の例題において検討すべきアーキテクチャにはどのようなものがあるでしょうか。このことについてまず考えてみましょう。
(A)Webサービスアーキテクチャの検討
このシステムの構成は本社に配置される全社在庫管理システムと、各支社に配置される販売管理システムによる統合システムとなります。支社は自社在庫がない場合、本社にあるほかの支社の在庫リストに問い合わせをします。この仕掛けにはWebサービスによる実現が向いていますね。そこで、Webサービスを使ってこの課題を実現するアーキテクチャを「(4)アーキテクチャのプロト検証」のテーマとするわけです。最適なWebサービスによる実現アーキテクチャを検討します。
その結果、今回は図3のアーキテクチャを使用することにしました。図3は、UMLの配置図というダイアグラムを使用しています。モデル要素としては、コンピュータシステムにおける構成単位を表す「(1)ノード」と、システムの物理的リソース構成「ファイルやライブラリ」を表す「(2)コンポーネント」などを使ってシステム構成を表すものです。UMLのコンポーネントは、ソフトウェアの論理単位として使用されるコンポーネントという用語とは異なるものと考えてください。
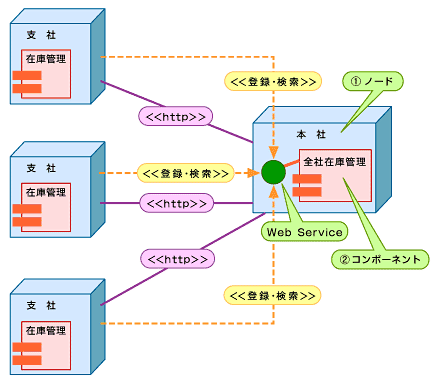 図3 最終的に採用されたWebサービス実現アーキテクチャ(配置図)
図3 最終的に採用されたWebサービス実現アーキテクチャ(配置図)では、図3をもう一度参照してください。このモデルの大きなポイントは、本社側にWebサービスを立てるということです。つまり、支社から在庫状況が変わったタイミングでその情報を本社にプッシュするというわけです。このアーキテクチャに行き着くまでに検討したモデルを図4に示します。この図は、本社が支社から在庫検索というWebサービスを呼び出した際に、同時に各支社の在庫情報取得というWebサービスを呼び出すというものでした。
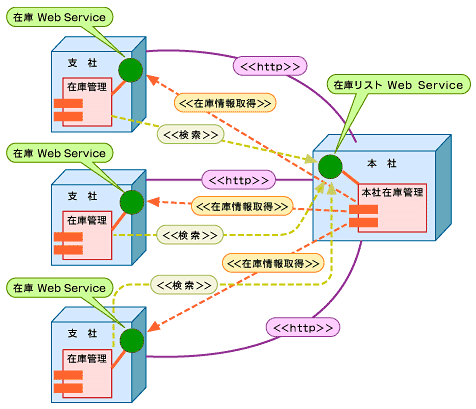 図4 採用されなかったアーキテクチャ(配置図)
図4 採用されなかったアーキテクチャ(配置図)しかし、この方式では、プロトタイプによって満足のいくパフォーマンスを得られませんでした。したがって、図3の方式をプロトタイプとして検証し、最終的には図3の方式で行くことにしました。Webサービスの場合、Webメソッドの呼び出しにはミリ秒のオーダーというかなり遅い呼び出しになってしまい、それがネックになることも多いのです。そのために、キャッシュ機構や、図3のようにサービスを受ける方にWebサービスを立てるという逆転の発想によるプッシュ型Webサービスモデルを考えてみるといいでしょう。
(B)データベース設計
図5は、UMLのクラス図を使ってERD(実態関連図)を書いたものです。この図を第12回の図12のクラス図と比較してみると何が変わったか分かるでしょう。ERDは永続化対象をモデル化しますので、クラスの類別化によって付与されたEntityクラスが対象となります。基本的には1クラス、1テーブルです。さてEntityの属性を見てください。<
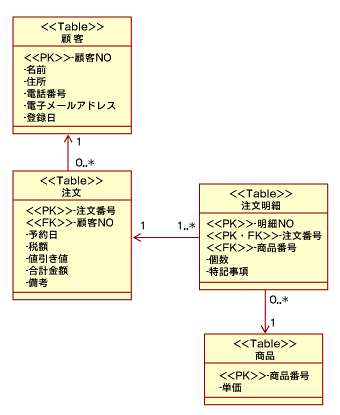 図5 RDBテーブル構造のモデリング
図5 RDBテーブル構造のモデリングさらに、関連が双方向の場合のテーブルマッピングでは、2つのテーブルのリレーションを行うための関連テーブルというものが必要となります。このテーブルは、2つのテーブルのプライマリキーを関係付けるためのキーテーブルとなります。もし、クラス図中、関連クラスとして表現されている個所があれば、それはそのまま関連テーブルにしてあげればよいでしょう。そのほか、データベース設計の課題としては、典型的なクエリを分析し、パフォーマンス面の要求を満たしているのかといった検証などがありますが、ここでは割愛します。
コラム:データベース設計はいつやるの?
データベース設計をどのフェイズで行うかはケース・バイ・ケースです。例えば、すでにデータベースが存在しており、その上にオブジェクト指向でアプリケーションを開発することもあるでしょう。この場合、データの論理設計(ERD)が存在するのであれば、それを参考にビジネス概念モデルや分析モデルのクラス図を作成することになります。また、企業レベルのデータモデルを確立する場合は、ビジネス現状分析・戦略分析にて行う必要があります。奇麗事をいうと、ビジネス現状分析・戦略分析段階で概念モデルを基にデータ論理モデル設計をちゃんと行い、テーブルの主キーと外部キーを明確に定義すべきといいたくなりますが、これは一長一短のように思えます。
なぜかというと、企業レベルでデータベースの論理モデルの共通化を図り、それを土台として個々のシステムとシステム中のサブシステムを開発するというやり方を進めすぎると、システム間やサブシステム間が密結合となってしまうからです。
企業における普遍的なエンティティについては共通化を図るのはいいと思いますが、あまりそのようなエンティティを増やしすぎると、システムが密結合を起こしてしまい拡張性・保守性の問題が出てくるでしょう。そこで、ある程度システムを小さく作り、それぞれのシステムをカプセル化して独立性を高め、システム間の関係は疎結合にしておくというアプローチも必要に思えます。その場合は、システム開発の中でデータベース設計を行うということも考えられるのです。
(C)アプリケーション・パーティショニング
前回説明しましたシステム分析において、ロバストネス分析の結果となる分析モデルを紹介しました(第12回の図12)。この図の中でクラスは論理的なグルーピングがなされています。このような分類方法は簡単に説明するとオブジェクトの存在場所に責務を設けるということです。
つまり、Boundaryとは、オブジェクトのグループ化された場所と考えることもできます。そしてその場所は、システム境界にあり、アクターからイベントを受け付けて、Controlに引き渡すという責務を持つという意味付けがなされているわけです。ロバストネス分析で利用されている(Boundary、Control、Entity)はソフトウェア構造としては、汎用的かつ普遍的なものです。そのほか皆さんがご存じのJ2EEのMVC(Model、View、
Controller)も似たような類別化の1つと考えることができます。UMLには、クラスの論理的なグループを表すパッケージというものが用意されています。そこで、これらをパッケージ図として図6に示します。また、このような分類作業を論理パーティショニングと呼ぶことにします。
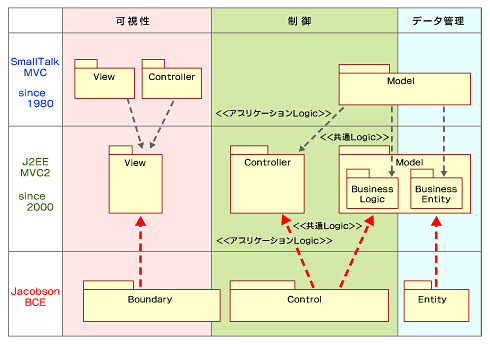 図6 クラスの責務分類(論理パーティション分割)
図6 クラスの責務分類(論理パーティション分割)この図では、Javaの設計文化を支えている根幹と問題を理解していただくために、オブジェクト指向の歴史をさかのぼった図としています。では、まず図6上段を見てください。ここには、Smalltalk-80(スモールトーク)で確立されたMVCモデルを紹介しています。ご存じの方は多いと思いますが、J2EEのMVC2という最新のアーキテクチャは、20年ほど前にSmalltalk-80によって確立されたモデリングスタイル(現在でいうところのデザインパターン)を参考としているのです。
Smalltalkは現代のオブジェクト指向言語および環境の土台となったものですが、そのころのワークステーションまたはパソコン上のソフトウェアは、単純な対話型システムがほとんどで、データを大量に使用するような基幹系システムにはあまり向いていませんでした。そのような理由により、MVCの考え方は、問題領域のオブジェクト(Model)を見ながら(View)、操作(Controller)するというとても自然なものでした。これを鉄人28号に例えると、鉄人28号がModelです。そして操縦卓がControllerであり、正太郎くんの目がViewということになります。つまり、ViewがGUIオブジェクトで、ControllerはModelとViewの整合性を取るための主要なメカニズム部のことをいっていたのです。
J2EEが直面しているソフトウェアターゲットとは、このような単純な対話型システムではありません。そこで、MVCというネーミングを採用し、従来のMVCのViewとControllerの役割をViewにまとめたのです。そして、Controllerには、制御の中のアプリケーションロジックという新たな責務を与えています。また、Modelは、Smalltalk-MVCの構造をそのまま残したのですが、現代のビジネスアプリケーションを適切に表現できるよう、Model内部をビジネスロジックとビジネスエンティティに分類したのです。結果的には、Smalltalk-MVCのModelは、J2EE-MVC2のController(アプリケーションロジック部)とビジネスロジック(共通的なロジック)に分類されたのです。これがJ2EEのMVC2の正体です。
次は、BCEに分類された分析モデルがJ2EE-MVC2の設計モデルにどのように表現されるか見てみましょう。図の中のBCEからJ2EE-MVC2への点線部分を見てください。まず、Boundaryは名前から想像できるとおりViewスーパーセットですので、そのままViewに置き換えます。そして、Controlに分類されたクラスの一部は、アプリケーションロジックを実現するControllerか、ビジネスロジックを実現するModelへ移行されます。EntityはそのままEntityへ移行します。そして、実際の実装手段の選択肢としては、図7のようなものになります。
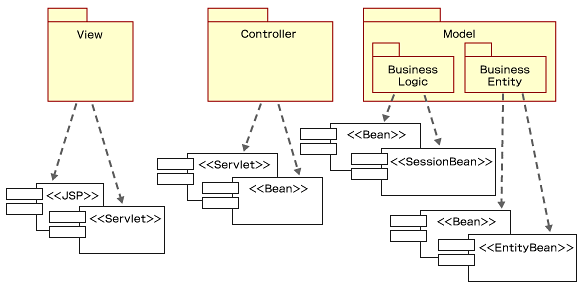
図7をJ2EEでよく使われる5層モデルの図で表すと図8のようになります。5層モデルでは、Webクライアント(クライアント層)とデータベース(リソース層)というオブジェクトの生存している世界の外も含まれていますので、このレベルになるとようやくシステム全体の構造を描いているということになります。
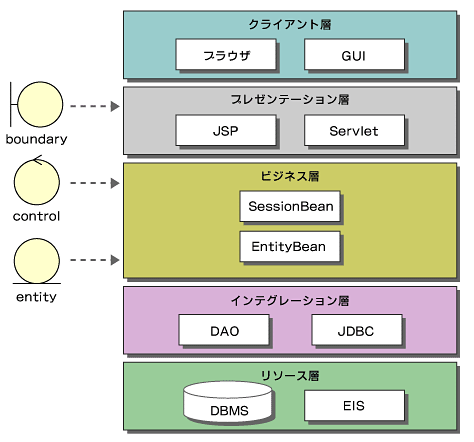 図8 BCEとJ2EEの5階層モデル
図8 BCEとJ2EEの5階層モデルさて、筆者がここで何をお話ししたかったかといいますと、2点重要なことがあります。まず、最初にJ2EE-MVC2を設計に利用した場合、アプリケーションロジックとビジネスロジック(共通的なロジック)を分類するのが難しいのですが、実際には、適当に分類してしまうことが多いようです。
この場合、後で無駄な論理・物理パーティションを作成してしまうという問題につながります。これはささいなことと思われるかもしれませんが、たとえ、論理パーティションが増えたということでも、エラー処理の引き渡し、戻り値の引き渡しなど、ソフトウェアの複雑度が増すというリスクがあります。そもそも、ビジネスロジックの分類は、複数のシステムの計画や、複数のサブシステムで構成される比較的大きなシステムの開発計画でなされない限り、うまくいかないことが多いのです。そのため、経験の浅いプロジェクトチームでは、あまり無理をして分類しようと思わないでください。まずは、Boundary、Control、Entityの構造をそのまま設計に落とすことを考えましょう。
そのほか、もう一点、オブジェクト指向開発者の中には、Smalltalk-MVCのような分類法を好むエンジニアがいます。この人たちは、データ処理系システム開発ではなく、ツールや制御系開発の経験を積んでいる人々です。この場合、ModelをControllerとEntityに分類しないやり方で開発を進めます。そうなるとデータの永続化やデータベースとのマッピングにおいてうまく設計に結び付けられないケースも出てきます。もし読者自身がそのような手法を身に付けている場合、Entityの重要性を再度認識していただければ、ビジネスアプリケーションの設計を適切に行うことができるようになるでしょう。
では、今回のモデルはどのような論理パーティションに分割すればいいでしょうか。実際には、対象システムの発展に応じて決定すべきことです。しかし、ここでは最も簡単でシンプルな方法を採用しました。つまり、BCEを設計時の論理パーティションとしてそのまま採用することにしました。また、システム関連系を行うためのWebサービスのプロキシクラスを置くためのSystem Integrationパッケージを新たに設けることにしました(図9)。
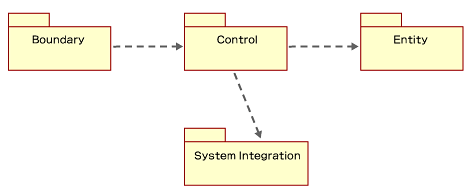 図9 販売管理システムの論理パーティション分割
図9 販売管理システムの論理パーティション分割では、実際のクラスをこのパッケージに入れて表現したものを図10に示します。このようにして見るとクラスの役割分割が明確になり、分かりやすくなったように思えます。しかし、このクラス図はまだ論理設計といったところです。なぜなら、データベースとかServletやASP.NETなどの実装アーキテクチャが含まれていないモデルだからです。このような図は、システムアーキテクチャの抽象イメージをつかむために、コア・アーキテクチャの確立という作業の初期段階にホワイトボードなどで議論されるものと考えてください。
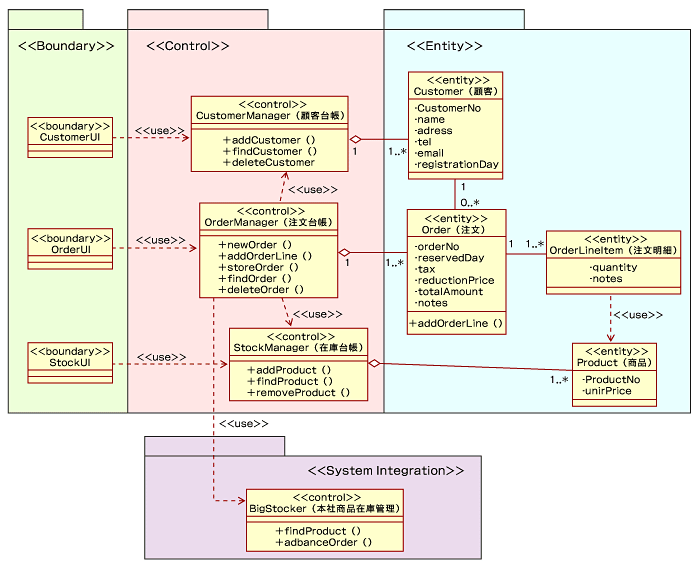
そして、その次の段階には、アーキテクチャのプロト開発によって実装アーキテクチャについての知識や実際の利用イメージも明らかになることでしょう。この事例では、実際に本社にどのようなルールで在庫を登録するのかといった業務ルールも決めなければならないことに気が付くことになるでしょう。しかし、この段階で気が付くのは少々うそっぽいですね。本当は第11回「UMLモデリングの開発過程(ビジネスモデリング編)」で説明した戦略分析フェイズでこのようなビジネスルールは検討しておく必要があります。しかし、このように実際にプロトタイプを作っているうちにシステムの具体的な問題が見えてくることも実際にはよくあることです。
この例では、試験運用期間の業務ルールとして、在庫内容と在庫数をシステムに入力することにしました。そこで、システム分析チームが作成した在庫登録ユースケース図を見てみると、在庫を本社に登録するというユースケースがありません。よって、システム分析チームにその必要性を説明し、ユースケースモデルを拡張してもらうことにしました。この作業は、システム分析チームとの並行作業であることを思い出してください(第12回・図2参照)。
このようにして、ビジネスアイデアやビジネス課題を盛り込んだアーキテクチャを創造していくのです。実装アーキテクチャを含んだモデルの簡単な例を図11に示します。このクラス図は、将来Webを使ったユーザーからの直接利用を想定して、Webアプリケーションとして一部のサービスを実装する際の設計モデルの例です。
Webアプリケーションの実現については、JavaのServletを使用しています。また、GUIはJSP、データベース(JDBC)アクセスを行うオブジェクトはDAO(DataAccessObject)と表現しています。システム連携にはWebサービスを使っています。

では、この図の見方について説明しましょう。まず、図が煩雑になったので操作と属性は省略しています。また、スーパークラスについても省略しています。ステレオタイプはどの種別に属するクラスかを判別するために使用しています。GUIはJSPとして作成しますので、依存関係としてステレオタイプ<
次は、この図の実装アーキテクチャを含む実装アーキテクチャの考慮点について説明します。まず、図10でXXXManagerと呼んでいたものは、DAO(DataAccessObject)とすることにしました。DAOは、データベースへのアクセスを抽象化するクラス群のことです。実際には、DataAccessというスーパークラスを作成し、DataAccessの中でJDBCへのアクセスを行うように考えました。DataAccessは、RDBの行とオブジェクトのマッピングを行う役割を責務として持っています。
また、図10では、OrderManagerがStockManagerやCustomerManagerを使用するよう考えていましたが、OrderManagerの責務が多くなりすぎてしまうので、OrderControllerというクラスを新たに作り、そのクラスにStockManagerとCustomerManagerのコントロールを任せるようにしています。OrderControllerは、HttpServletのサブクラスとします。
次は、このクラス図の動的モデルについて説明しましょう。
図12は、注文一覧の表示を行う際のシーケンス図となります。この例では、EJBなどのオブジェクトラッピングコンポーネントを利用していませんので、OrderManager(DataAccessのサブクラス)が頑張ってデータベースにアクセスし、注文テーブルの行を複数行取り出し、その行からOrderオブジェクトを生成します。また、Orderオブジェクトの主キーにより注文明細テーブルの行を複数取り出し、OrderLineItemオブジェクトを生成します。
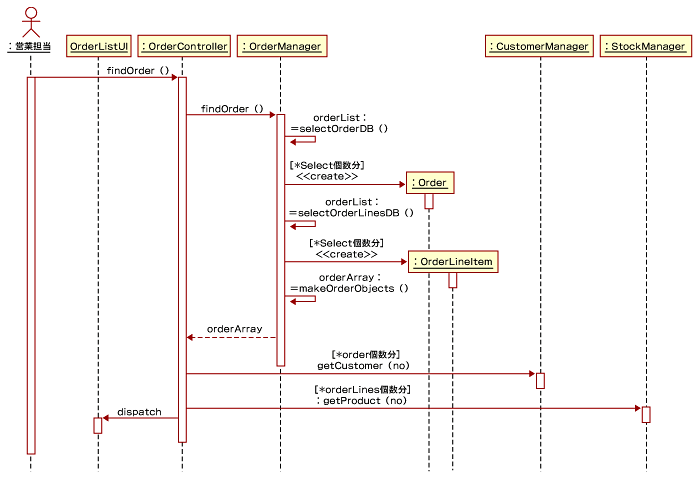
そして、その両オブジェクトにより、Orderオブジェクトを完成させ、orderArrayに入れ込むのがmakeOrderObjectsメソッドとなります。その後、OrderControllerがorderArrayに入っているOrderオブジェクトに顧客(Customer)と商品(Product)をsetするために、CustomerManagerとStockManagerを使っています。CustomerManagerとStockManagerは、初期化時にすでにデータベースからCustomerとProductを読み込み、キャッシュしているということにしています。このようにデータベースへのアクセスをできるだけ一挙に行う理由はパフォーマンスを考慮しているためです。
もし、実装にEJBを使用する場合は、OrderManagerがSessionBean、OrderとOrderLineItem、Customer、ProductはEntityBeanとなるでしょう。モデルは簡潔になり、シーケンス図も異なるものになります。
(6)システムの詳細設計・実装・テスト
システムの詳細設計・実装・テストを行います。この作業は、コア・アーキテクチャ確立の後に続くものです。システムの詳細設計を行い、すべてのユースケースを実装し、テストするということを役割として、1個以上のチームにより実施される作業ですが、モデリングの観点で特に説明するものはありません。ただ、この作業では、より細かなレベルでシステムが果たすべきサービスを見ていきますので、より詳しいクラス図やシーケンス図が必要とされることになるでしょう。また、テスト仕様書は、かなり前段階(要求分析)で作成しておくべきでしょう。そうすることで、クラスの細かな動きをユーザーから見たサービスで検証できるようになります。
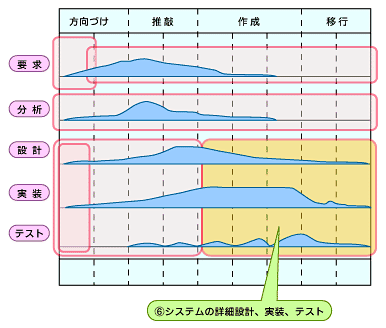 図13 システムの詳細設計・実装・テスト
図13 システムの詳細設計・実装・テスト3回にわたって、自動車専門部品販売店(RacingObjective社)の開発を例に、ビジネスモデリングから開発までUMLモデリングを中心に説明を進めてきましたが、いかがでしたでしょうか。少々細かすぎて分からなかったと思われる方、結構駆け足での解説でよく分からないと思われた方、両方いらっしゃるでしょう。筆者としては、もう少し詳しく説明したいというのが本音です。しかし、Web連載の都合上、あまり文章が長くなってしまうと読みづらくなるため、少し圧縮して説明することになりました。もう少し表現力があれば簡潔にまとめることもできたのでしょうが、現在の筆者の能力ではこれが限界のようです。「初歩のUML」では、連載当初Javaの実装まで含めた形で進めていこうと考えていましたが、それが実現できなかったのが少々残念です。しかし、「初歩のUML」で、中途半端にJavaの実装を説明するより、「Javaオブジェクトモデリング」などの連載を皆さんに紹介した方がよいと思い直し、この連載では取り上げませんでした。
何度も挫折しかけた連載ですが、ようやく自分なりにもある程度、満足のいくものに仕上がったように思えます。また、うれしいことに、この連載が書籍化されることが決まりました。書籍では、さらに内容を濃くする予定ですので、発刊の際には、またお付き合いくださいね。
では、皆さん、長い間ありがとうございました。
(編集局より: なお、【改訂版】初歩のUMLは書籍化する予定です)
- 第5回 少しだけ高度なモデリング技術(その2)クラスの依存関係と実現関係
- UMLモデリングのノウハウ、最後の秘訣(UMLモデリングの開発過程 開発編その2)
- UMLモデリングの開発過程 開発編
- 第11回 UMLモデリングの開発過程(ビジネスモデリング編)
- 第10回 開発プロセスの上手な組み合わせ
- 第9回 UMLベース開発プロセスの流れ
- 第8回 顧客の要求をユースケースに反映させる
- オブジェクトの動的側面を見極める
- 第6回 「関連」の理解をさらに深める
- 第4回 少しだけ高度なモデリング技術(その1)関連クラスと集約、コンポジション
- 第3回 モデリングにおける「汎化」と「特化」
- 第2回 クラス図の詳細化とその目的
- 第1回 まずはUMLのクラス図を書いてみよう
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- AIは本当に「考えている」のか Apple論文が問いかけた推論モデルの限界とその行方
- Microsoft、7月の月例更新で約570件を修正 悪用済みゼロデイ2件にまず対応を
- ロジャー・フェデラー氏が明かす「2ポイントに1つは落としていた」事実 勝負どころを見極めるデータ活用
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 多要素認証も飛び越えるフィッシング iOS 27の"新たな防波堤"
- なぜ、JFEスチールは「非ITエンジニア9割」でシステムモダナイズに挑んだのか? 刷新成功の舞台裏
- 「足りないのはCOBOL人材じゃない」 日立が語る、AI時代のシステム刷新における“人”の役割
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。