Googleの限界は「人の手」で破る――国産の新検索「想」
 高野教授は「人間ができることを機械が10倍のスピードでやってくれるなら、たとえ質が7割落ちてもそっちを選ぶ人は多い」と嘆く
高野教授は「人間ができることを機械が10倍のスピードでやってくれるなら、たとえ質が7割落ちてもそっちを選ぶ人は多い」と嘆く
「Googleは確かに便利だが、大きな問題がある」。国立情報学研究所(NII)の高野明彦教授は指摘する。「プロの手による知識を、そこここで台無しにしている」というのだ。
Googleは、被リンク数などを尺度とした独自のアルゴリズムでサイトの重要度を機械的に判定するため、検索結果の表示順と情報の信頼性は必ずしも比例しない。これがGoogleの「唯一最大の問題」という。
「Google上では、記者が現場を歩いて裏を取った新聞記事も、ネット上の情報を写しただけのブログ記事も同列。情報の質や、経過の“差異”が失われる」。ネットが誕生するはるか以前から培われてきたプロの手法も、ロボット検索の前には無力だ。
 文化遺産オンラインの検索結果例。「関連する作品」をテキストマッチングで自動抽出する
文化遺産オンラインの検索結果例。「関連する作品」をテキストマッチングで自動抽出する
高野教授がこれまでに開発してきた検索システムも、同じような問題に直面してきた。例えば、国立博物館の展示物を検索できる「文化遺産オンライン」は、展示物の解説文同士をマッチングし、同じ単語を多く使われていれば「関連する展示物」として自動抽出する仕組みだが、学芸員からは評判が悪いという。「同じ絵が付いているというだけで、生産国の異なる皿が“関連する”と表示される。これが学芸員には耐えられないようだ」
人間+機械の“融合”
学芸員の分類と、ロボット検索の分類。この2つを融合することで、新しい検索の世界が開けるはずと高野教授は語る。学芸員などプロが人力で作った“ホワイトリスト”をカタログ化した上で、機械検索を使ってさらに世界を広げる――こんな検索が、「Googleの次」に必要とされるという。
高野教授が博物館向けに手掛けた別のシステム「遊歩館」がその例だ。学芸員が展示物を自らの視点で分類できるのが特徴で、トップページには学芸員が分類した展示物リストが並ぶ。リスト上の各展示物は「文化遺産オンライン」の展示物ページにリンクしており、クリックすれば、興味を持った展示物に関連する展示物を、機械検索によって幅広く探せる。「これは学芸員に評判が良かった」
 遊歩館
遊歩館
高野教授が新たに開発した「想-IMAGINE-」も、人力の編集とロボット検索を融合したシステムだ。複数のデータベースから検索した結果を、ソース別に並べて表示できる。
例えば、同じ単語や文章に対して、「WikiPedia」と「世界大百科事典」と朝日新聞のデータベースから検索した結果を一覧表示。あらゆるソースの情報をごちゃ混ぜにしてしまうGoogleなどとは異なり、編集スタンス別に結果を比べられる。
検索結果のうち気になるエントリーをチェックし、もう一度検索ボタン(「IMAGINE」ボタン)を押せば、そのエントリーの文章を起点とした検索ができ、検索結果を絞り込んでいける。「検索者の『想い』を読み取ってくれる」――絞り込みの過程を、高野教授はこう表現する。
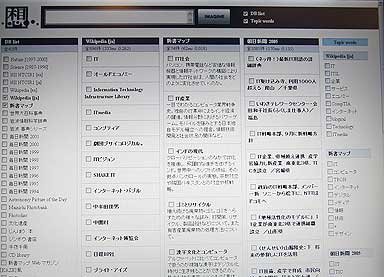 想-IMAGINE-を使って「IT」の検索結果を「WikiPedia」「新書マップ」「朝日新聞」で比較。実験サイトでは、海外の学術誌や毎日新聞の写真データベースなどからも検索できる
想-IMAGINE-を使って「IT」の検索結果を「WikiPedia」「新書マップ」「朝日新聞」で比較。実験サイトでは、海外の学術誌や毎日新聞の写真データベースなどからも検索できる
検索エンジンには、高野教授らが開発した全文検索エンジン「GETA」を活用。1つの文書や長文を検索キーとし、文書・文章内に現れる複数の単語の関連性(連想)を分析することで、その文書・文章と関連性の高いものを検索できる仕組みだ。(関連記事参照)。
「想」は今年秋ごろに一般公開する予定。まずは、まずは、図書情報「Webcat Plus」や「新書マップ」「文化遺産オンライン」といった、GETAをベースに構築した非営利でオープンなコンテンツを横断検索できるようにする(関連記事参照)。その後、新聞記事やオンライン百科事典などとも連携できるよう交渉する計画だ。
「データをたくさん持っている人の所には、GoogleやAmazonから、『何億ページビューをあげますからうちのエントリーに入れてください』などと魅力的な提案が来る。しかしそれでは結局、GoogleやAmazonに情報が集まってしまう」――高野教授はこんな風に語り、GoogleやAmazonに頼らない、“人の想いをくみ取る検索”を提供していきたいとした。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
防衛省の「クーラー300台」投稿動画でビックカメラのトラックが注目を集める 同社「販売用の在庫を迅速に提供」
-
2
「文スト」スマホゲーム、きょう告知→あす終了 突然のサ終にユーザー混乱 運営元の廃業で
-
3
ドコモ、ahamoを30→40GBに増量 8月1日から 料金据え置きの新キャンペーン
-
4
「楽天ドライブ」アプリから「データ漏洩」「ハッキングした」通知? 運営元「緊急調査中」「通知を開かないで」
-
5
“ダサい”不評の「ドコモの銀行」、従来のアプリアイコン選択可能に 「ご意見・ご要望も踏まえ」
-
6
イオンモール熊本のドローン捜索、状況を現場キーマンに聞いた 撮影を阻んだのは……
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
“脳のゴミ”は鼻から捨てられていた? 老化で詰まる排出路、薬を鼻から投与で改善 韓国主導チーム研究
-
9
光学25倍ズームのソニー「RX10 V」はもう“レンズ一体型α” 1台で何でも撮れそうな万能感に浸れるぞ
-
10
タムロン、ソニーからの買収提案認める 特別委員会を設置して検討
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR