日本人のアタマを救え――書籍検索でネットに“知の信頼性”を:書籍とネットの微妙な関係(1/2 ページ)
ネット上の情報がこのままの状態だと日本人の“アタマ”が危ない――国立情報学研究所(NII)の高野明彦教授は警告する。日本語ネットコンテンツの多くは、企業が運営する商用サイトか、裏づけのない情報が飛び交うブログや掲示板。中立的で信頼の置ける情報が充実しているとはいえない。
「情報の質が下がれば、それに合わせて脳も貧弱になってしまう」と高野教授は心配し、ネット上に信頼できる情報を増やしたいと話す。切り口は、コンテンツとの出会いを増やしてくれる検索技術「GETA」(ゲタ)と、編集者の目を通し、信頼性がある程度担保されている書籍だ。
 後述の「
後述の「「ネット上は責任を持たない情報だらけ。その中で人は育つ」――裏の取れた確実な情報はそれほど多くないにも関わらず、ネットの世界だけで情報を完結させ「Google検索で出ないものはこの世に存在しないと同然」ととらえる人は少なくないと、高野教授は指摘する。
街に道路や公園があるように、ネット上にも、日々の生活に役立つ公共コンテンツ――知識の公共財――が必要と高野教授は言う。公共財とは「便益が非競合的な財」。利用者が増えても、他の利用者が損しない財産を指し、政府が税金で整備すべきものという。
しかし政府は電子コンテンツ整備にはそれほど積極的でない。「官報など誰も読まないものを言い訳的に、莫大なお金をかけて電子データ化しているだけ」――だから、国立の研究所で働く自分が政府に代わってやるのだと高野教授は話す。
書籍をネットに引っ張り出す「連想検索」
知識の公共財としてまず、書籍に着目した。書籍の情報なら編集者の目を通っているため情報の信頼性もある程度担保されており、共用してもそれほど価値が薄れない。NIIは書籍のデータベース「Webcat」を保有しており、コンテンツを丸ごと使えるという背景もあった。
書籍の情報をネット上に引っ張り出すために活用したのが、高野教授が中心となり、NIIと日立製作所などが共同開発した連想検索エンジンGETA(Generic Engine for Transposable Association)だ。
GETAは、人がものごとを連想するように、文章の固まりから関連情報を次々に見つけ出す「連想検索エンジン」。文章を検索窓に入力すると、瞬時に形態素解析し、最大1000万件規模の大容量データベースから関連文書を検索できる。
GETAとWebcatを組み合わせ、2002年に書籍検索サービス「Webcat Plus」をオープンした。同サイトの検索窓に文章を入力すれば、Webcatから関連書籍を大量に抽出できる。
例えば、GETAのリリース記事の全文を入力すると「情報検索と言語処理」「ファジィ・データベースと情報検索」など100万冊以上の関連書籍を瞬時に拾い出す。「検索」「データベース」など関連するキーワードも一覧表示。キーワードをクリックして再検索すれば、関連する書籍がまた一覧表示される。
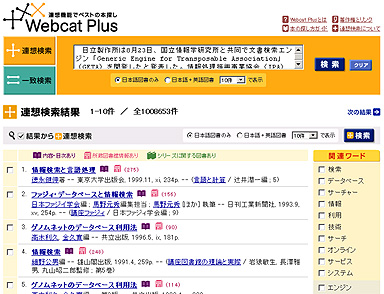
単純なキーワード検索と違って周辺情報を含めた幅広い書籍を検索でき、予想外の書籍とも出会える。関連検索ワードから、検索の幅も広がる。
GETAを使った“書籍に出会うネットの糸口”は、もう1つある。昨年6月に構築した「新書マップ」だ。
新書で時代のニーズを汲み取る
新書マップはいわば読書の入門サイト。検索窓に任意の文章を入力すれば、関連するテーマのアイコンがマップ上に浮かび上がり、アイコンをクリックすると、テーマに関する新書一覧とその解説が読める。
新書や選書は、時代のニーズをくみとってテーマ決めされているため、今まさに必要とされている情報が抽出できると高野教授は考えた。入門書も多く、読書の入り口としてもうってつけというわけだ。
1万冊以上の新書や選書を買い集め、約1000のテーマに分類。新聞記者や研究者などに頼んでテーマごとに解説文も書いてもらい、プロの手による高品質なサイトを目指した。
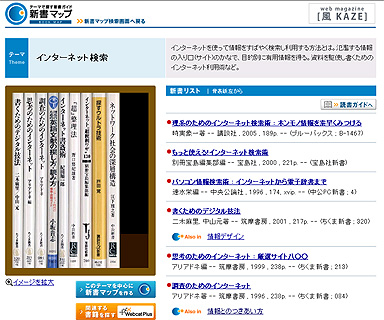
Webcat Plusと新書マップで、ほぼすべての書籍と、書籍の入り口となる新書はカバーした。次に狙いを向けたのは、現物の書籍と出会える実店舗だ。
ネットの住人を古書店へ
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PRアイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。