テキストマイニングで顧客対応力強化を図る:テキストマイニングの基礎(3)(2/2 ページ)
3-3 FAQの有効活用ポイントは、テキストマイニング
ところがこのFAQを紙媒体で管理・運用しているコンタクトセンターでは、なかなか思うような成果が生まれにくいようだ。そのため、検索の利便性や内容更新のしやすさを考え、データベース化して管理・運用する企業が最近は多くなってきたことが、野村総合研究所が2007年10月に実施した調査結果にもそれが表れている。
同調査によると、約47.28%の企業がFAQをシステム化しているというが、約44.77%の企業はシステムではない形式でFAQを運用しているという(グラフ4)。
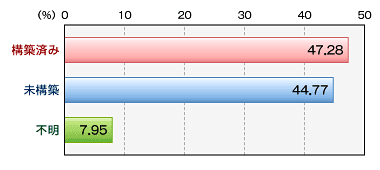 グラフ4 FAQを用意している企業は92.05%に上るが、システム化している企業はその約半数の47.28%。なお、不明は7.95%。『“顧客の声”分析・活用術』(リックテレコム刊)の71ページの図2−2−1を引用。このグラフは、上記野村総合研究所の発表を基にしたもの
グラフ4 FAQを用意している企業は92.05%に上るが、システム化している企業はその約半数の47.28%。なお、不明は7.95%。『“顧客の声”分析・活用術』(リックテレコム刊)の71ページの図2−2−1を引用。このグラフは、上記野村総合研究所の発表を基にしたものしかし、FAQをただ単にデータベース化すれば期待した効果が得られるものでもない。「FAQに登録されている内容をいかに精度よく検索できるようにするか」や、「内容の質・量をいかに高めるか」という工夫が必要となる。ここで重要になってくるのがテキストマイニング技術である。
検索精度を高めるテキストマイニング
まず、FAQの検索精度について見ていこう。コンタクトセンターにおいてオペレータが検索するのに時間がかかってしまうと、電話をしてきた顧客のイライラが募ってしまう。しかし残念ながら、近年の商品・サービスの多様化・複雑化も影響して、現実としてこの検索に、相当の時間がかかってしまう場面も多い。
よく耳にする課題を列挙しよう。「文字列検索ではうまくキーワードが設定できない」や「どのカテゴリやフォルダに含まれているか分からない」などがよく挙がる。その結果、「検索を試みても、なかなか目的のコンテンツにたどり着けない」という不満がオペレータから上がる結果になる。
もちろん、熟練オペレータであれば、これまでの経験からある程度のアタリをつけ、例えばAND条件、OR条件を駆使して発見できるかもしれない。
ところが多くの現場では、回答らしき大量の候補が表示されてしまい、それを1つ1つ目で追う羽目に陥るか、逆に条件を詳細に設定し過ぎて、検索結果に何も表示されないという状況に陥るかのどちらかではないだろうか。
こうした検索の課題は、何もオペレータ用のFAQだけでなく、一般向けの公開FAQにも該当することが多い。どのカテゴリに存在するか分からない、また専門用語を知らない一般消費者は、この検索の時点ですでにイライラ度は急増していそうだ。
こういう場合は、キーワード検索だけでなく、テキストマイニング技術を用いた自然文検索機能が有効であることが多い。例えば、「操作中に変な音がする」といった平易な文章を入力することで、目的の文章を要素に分け、類似度順に表示できる。
オペレータや一般消費者などの「検索者」と、「FAQ作成者」の表現の統一を図るために、辞書をチューニングすることも重要なポイントになり得る。
例えば、FAQに「コンピュータ本体の裏面にある***を参照してください」と記載されているとしよう。
ここで、検索者が「パソコン」や「PC」といった内容で検索しても、キーワード検索では上記の回答はなかなかヒットしない。せいぜいヒットしても検索順位は下になってしまう。そこでFAQ作成者と検索者の間で表現の統一を行う必要がある。また、FAQ作成者同士の間でも、同様に表現を統一させる必要もあるだろう。
そのため、FAQシステムで同義語を簡単に統一できる仕組みが必要となる。第1回 「膨大なテキストからビジネスのヒントを探せ」で見たように、辞書をチューニングすることで表現の統一を行うことができる。
FAQの質と量を充実させるテキストマイニング
次に、FAQのコンテンツの質や量について見ていこう。仮に答えが見つかったとしても、それで解決しなかった場合、顧客の信頼を結果的に損なうことになる可能性が高い。これは、分かりにくい回答であっても同様である。さらに、ある程度の(回答の)量が用意されていないと、探してもまったく見つからない結果になってしまうこともある。よってどのようにFAQの品質を高め、量を充実させ、いかに検索者に満足してもらうかが、2つ目の重要なポイントになる。
品質を高める方法としては、検索者のFAQの参照履歴に注目する方法がある。ある問い合わせに対して、1回のFAQ検索で済んでいるのか、その後複数のFAQを検索・参照しているのかを把握するのである。後者のような検索の状況をきちんと把握しておくことで、1回目の検索によって、FAQの記述に何が不足していたかが明らかになる。
また、「このFAQで問題は解決されましたか?」という項目をFAQのページに設けるケースがある。さらにその項目に評価理由を書き加えられるようにしてあれば、その評価理由を手掛かりにすることができる。すると例えば、「1回で必要な情報が得られるように、複数のFAQを統合する」や「評価理由にあったように図表を追加してみる」といったブラッシュアップのためのヒントが得られるであろう。
このケースの場合、評価理由の解析にもテキストマイニングが効果的である。
次に量を充実させる手段としては、検索ボックスに打ち込まれた検索ワードと参照したコンテンツの掲載内容を解析することで、不足しているFAQを発見できる可能性が高くなる。例えば検索した文字列に対応したFAQが実際にあったのかどうかを調べるとしよう。
すると、FAQに漏れている質問(これを“コンテンツホール”と呼ぶ)を発見しやすくなる。そのコンテンツホールに対応した新規のFAQを追加作成することで、効率よくコンテンツを拡充していくことができる。
例えば、Yahoo! JAPANの事例を見てみよう。Yahoo! JAPANでは、24時間365日、オークションやショッピングなど80種類以上のサービスについて、全ユーザーに対してメールサポートを行っている。
FAQのコンテンツの質と量を高めるために、1万5000程度だった定型文の数は、10カ月後には約2万となった。また単純に数が5000増えただけではなく、質的にもかなり向上したという。
このように、コンタクトセンターにおいて顧客対応力を高めるためにも、テキストマイニング技術は有効なのである。
筆者プロフィール
神田 晴彦(かんだ はるひこ)
野村総合研究所
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。