膨大なテキストからビジネスのヒントを探せ:テキストマイニングの基礎(1)
本連載は、テキストマイニングがビジネスでどのように活用できるかを数回に渡って解説する。ビジネスにおける利用シーンを具体的に述べるため、次回以降は多くの企業で設置す るようになったコンタクトセンターにおける最新の利用方法、事例、ポイントを述べる。
1-1 テキストマイニングとは文字情報の可視化技術
テキストマイニングとはどのような技術か。テキストマイニングはその用途や考え方によってさまざまな定義が存在するが、一般的には、自然文章(特に定型化されていないテキストデータ)を自然言語処理技術によって分割し、その出現頻度や出現傾向を統計解析技術・データマイニング技術を使って解析することで、傾向や特徴を可視化する技術とされている。
1-2 テキストマイニングの流れ
テキストマイニングの処理のプロセスを、技術的な側面から説明する。最初に断っておくが、今回での説明だけでは、ビジネスにおいてどのように利用できるか、読者にはイメージしにくい部分があると思う。なのでここでは、概念だけをざっと把握していただきたい。ビジネスでの活用例については、次回からは事例を交えて詳細に説明していく。
テキストマイニングを支える技術には、前述のとおり、「自然言語処理技術」と呼ばれる技術と、「データマイニング技術」の2つがある。
テキストデータと呼ばれるものは非定型なデータである。文字や文章で書かれたデータは、性別や都道府県など、入力ルール・コードが定まっている場合(これを定型データという)を除き、そのままの状態では活用しにくい。Excelのピボットをイメージしていただくと分かりやすいが、生データのままだと集計や分析できないのである。そのため、自然言語処理技術、具体的には、「形態素解析」といった処理を行い、単語の出現の有無などを解析するために定量的なデータに変換することが有効になる。
データマイニング技術は定量的なデータを集計する技術である。代表的なものに「アソシエーション分析」(同時に出現する単語間の関連性を見る分析)や、「クラスター分析」(テキスト間の類似性からグループ化する分析手法)がある。
ではテキストマイニングの典型的な処理の流れを見ていこう。
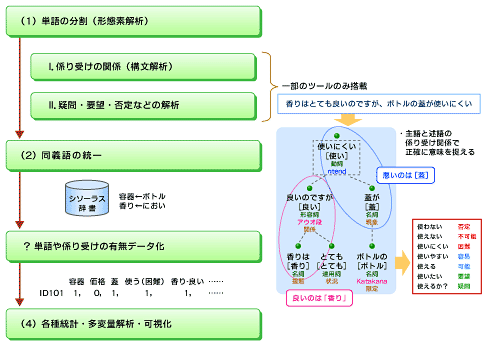 図 テキストマイニング処理の流れ (
図 テキストマイニング処理の流れ (上の図をご覧いただきたい。(1)〜(4)でテキストマイニング処理の流れを示している。
テキストマイニング処理では、1つ目のステップとして、文章を「形態素」と呼ばれる単位に分解する。形態素とは、これ以上細かくしてしまうと、その意味を成さなくなってしまう最小の文字列を意味する。これは「単語」という概念に近い。理解しやすいよう、あえて本連載では、単語という表現で説明を進めたいと思う。
なぜこのような処理が必要かというと、日本語の文章は数値データと異なり、単語が連続して記述されているため、集計処理できるよう定量化する必要があるからである。なお形態素解析では単語に分解するだけでなく、それぞれの単語の品詞(名詞、動詞、形容詞など)の判定も行う。
図中のI〜IIのように、一部のツールでは、構文解析や意味解析の処理を加えているものもある。このような処理を行うことで、文章の構造や意味をより正確にとらえて集計・分析することが可能になる。
2つ目のステップでは、同義語をまとめる。例えば「テレビ」と「TV」をまとめる。検索で経験のある人もいると思うが、テレビとTVは、検索する際に全く別の文字列として認識される。そのため、TVと検索しても、テレビという表現のみのページがヒットすることは非常に稀(まれ)だろう。そこで、このような同義語のまとめ上げが必要になってくる。ひらがなやカタカナ、固有名詞や省略形の表現も、この段階で統一する。ツールによっては、1つ1つ手作業で同義語を入力する手間を回避するために、同義語登録支援機能を備えているものもある。
3つ目のステップでは、定量データへの変換を行う。「テキストデータ1行1行に、どのような単語が出現していたか」といった単語の出現パターンを取得し、統計処理が可能な定量データへ変換する。例えば、1つ目のテキストデータには「香り」や「容器」が含まれているかどうかなど、データベース上で0/1の数値情報で保持する。
4つ目のステップでは、前段階で抽出した出現パターンを基に統計処理を行う。これで各種分析作業のための準備が完了する。
1-3 ビジネスへの展開例
このテキストマイニング技術は、ビジネスにおけるさまざまなシーンで利用されている。
例えば、アンケートに目を向けてみよう。
アンケートには、選択形式と自由回答形式がある。
選択式とは、年齢や性別、そのほか、商品に関するアンケートであれば、購入した理由や比較した他社製品など、サービスであれば、利用頻度や満足度を選択しながら回答していく形式である。
自由回答形式とは、選択肢が与えられておらず、回答者が自由に文章で意見や感想を書く形式である。「そのほか、もしお気付きになったことやご意見がありましたらご自由にお書きください」という設問を指す。選択肢形式は表計算ソフトで簡単に集計できるが、自由回答形式は前述のとおり、そのままで集計することができない。そこで、自由回答欄の内容を集計したり、キーワードを特定するために、テキストマイニングを利用する。
最近では、インターネット上の掲示板・コミュニティサイト、SNS、ブログなどに大量の文字情報が蓄積され、年々その数は増加傾向にある(本連載では上記をすべて総称して「ネット上の書き込み」と呼ぶことにする)。参考までに2007年12月に野村総合研究所が発表した予測を見てみよう。
『ネットビジネス市場のうち、2007年度から2012年度までの成長率が最も高いのは、ブログ・SNS市場で、その年平均成長率は31.7%に及ぶと見られます。ブログサイト数は2012年度末に約2200万サイト、SNS登録者数は約4,900万登録にまで拡大すると予測されます。特にSNSは、携帯電話向けサイトの充実、動画投稿サイトやECサイトなどとの連携によって拡大が見込まれます』
このようにブログ数だけでも2200万サイトという膨大な数が見込める。ネット上の書き込みの中には、企業にとって有益な情報や、早期に察知しなくてはいけない情報が多く存在している。例えば、自社の製品・サービスの利用体験談や比較情報、および誹謗(ひぼう)・中傷などである。これらを見つけたり、分析したりするのは困難である。このような情報の抽出や分析にもテキストマイニングは活用されているのである。
また、企業が蓄積している文字情報の代表的なものとして、営業日報がある。営業日報には、顧客と日々接しているセールスパーソンや店舗の担当者の“気付き”が眠っている。このような情報を分析する技術にもテキストマイニングは利用できる。
上記の例は主にマーケティング分野での活用例だが、マーケティングとは異なる領域でも利用例が多数ある。例えば、知財部は特許情報を取り扱う。従来は、特許の専門家が1件1件の明細書を読み込み、必要な情報を抽出・分析する人的アプローチが中心だった。テキストマイニング技術を利用することで、瞬時に各企業が保有する知的財産を分析でき、強み・弱みを可視化することが可能になる。
近年、利用が増えている事例として、コンタクトセンターに寄せられる履歴分析が挙げられる。コンタクトセンターに電話をかけると、その問い合わせ履歴はデータベースに文字情報として入力される。2000社を対象とした「企業の返答力調査」によると、コンタクトセンターに寄せられる問い合わせをデータベースに蓄積している企業は、全体の約62%だという(2006年6月26日日経MJ)。これらの履歴を分析することで、コンタクトセンターの効率化に寄与する情報を導き出すという動きがある。
次回以降、コンタクトセンターでの利用に注目して議論を深めていきたいと思う。テキストマイニングを利用してコンタクトセンターを高付加価値化する方法、ポイントについて述べていく。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- 500万件のWebサーバでGit情報が露出 25万件超で認証情報も漏えい
- 中国電力、RAGの限界に直面し“電力業務特化型LLM”の構築を開始 国産LLMを基盤に
- 一気読み推奨 セキュリティの専門家が推す信頼の公開資料2選
- 2025年、話題となったセキュリティ事故12社の事例に見る「致命的なミス」とは?
- 「SaaSの死」騒動の裏側 早めに知るべき“AIに淘汰されないSaaS”の見極め方
- LINE誘導型「CEO詐欺」が国内で急増中 6000組織以上に攻撃
- NTTグループは「AIがSI事業にもたらす影響」をどう見ている? 決算会見から探る
- 「年齢で落とされる」は6割超 シニアエンジニアが直面する採用の壁と本音
- なぜ日本のITエンジニアは優遇されない? 「世界給与ランキング」から見えた課題
- 年収1000万を超えるITエンジニアのキャリアは? 経験年数と転職回数の「相関関係」が明らかに
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。