特許文書を読みやすくする専用解析技術、NTTデータが開発
» 2005年10月11日 21時04分 公開
[ITmedia]
難解な特許文書を読みやすいように表示します──NTTデータは、自然言語処理技術を活用し、特許文書を解析して視覚的に表示したり、類似特許検索のためのキーワードを抽出することができる新技術を開発した。
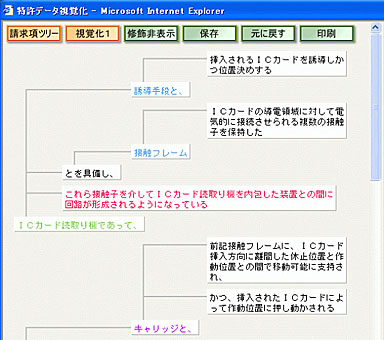 解析して視覚的に表示した例
解析して視覚的に表示した例企業が知的財産を重視する流れが加速し、特許出願件数は年間40万件以上に増加している。他社特許権の侵害などを防ぐため、出願済み特許の調査業務も重要になってきている。
だが特許文書はあいまい性を排除するため、独特の言い回しを多用した回りくどい文章で発明の内容を説明している。文章を解読し、内容を正確に理解するには専門家でも時間がかかるのが実情だ。
NTTデータが開発した新技術は、「パターンマッチング」技術を応用した。同技術は特定の品詞や表記などの「形態素」をパターン化し、パターンに適合した文字列を文書から抽出するなどして文書を解析する。
新技術では、特許文書独特の表現形式をパターン化することで構造解析を可能にした。発明を構成する要素や特徴の関係を視覚的に表示したり、発明を特徴付けるキーワードを抽出するといったことができ、調査業務を飛躍的に効率化できるとしている。
新技術をベースにした調査支援システムの製品化を半年後を目標に進める。10月12〜14日の「特許・情報フェア&コンファレンス」(発明協会主催、東京・科学技術館)で、請求項の構造を視覚化する機能などを中心としたシステムを展示する。
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PRアイティメディアからのお知らせ
SpecialPR
あなたにおすすめの記事PR
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。