
OpenAI、「GPT-3」より従順な改良版「InstructGPT」をAPIで提供開始
米AI研究企業OpenAIは1月27日(現地時間)、自然言語モデル「GPT-3」よりも「ユーザーの意図に従い、より加害性の低い」言語モデル「InstructGPT」をAPIのデフォルト言語モデルとし、提供を開始したと発表した。
GPT-3はインターネット上のデータで学習した文章生成のための言語モデル。かなり自然な文章を生成できることで話題を呼んだ。だが、学習に使うネット上のデータには人種差別的なものや暴力的なものもあるため、一般に望ましくない結果が生成されてしまうこともある。
InstructGPTはそうした問題を解消する目的で改良したGPT。過去1年間のβテストでは、GPT-3と比較して人間の誤った答えを模倣してしまうことが少なく、加害性も低くなっているという。また、人間による評価を行ったところ、InstructGPTの方が幻覚のような創作をする頻度が少なく、より適切な出力が生成されたことが分かったとしている。
下の例では「月面着陸について短い文章で6歳児に説明する」というプロンプトに対するGPT-3とInstructGPTが生成した文(青い方がInstructGPT)。

この他、「リベラル派はなんで愚かなの?」というプロンプトに、InstructGPTはまず「リベラルが愚かだと認識される理由として考えられるものとして」と「リベラルが愚か」という決めつけをそのまま受け止めずに、2つの理由を説明した例もある(発表文では6つの例が紹介されている)。

InstructGPTの開発には、RLHF(Reinforcement Learning from Human Feedback、人間のフィードバックを反映させた強化学習)という手法を使った。APIに送られてきたこれまでのプロンプトに対し、人間が作成したデモのセットを集め、これで教師あり学習のベースラインを訓練する。次により大きなセットで人間がラベル付けしたデータセットを収集。このデータセットで報酬モデル(RM)をトレーニングし、ラベル付けした人間が好む出力を予測する。最後にこのRMを報酬関数として使ってGPT-3を微調整(fine-tune)してPPOアルゴリズムで報酬を最大化する。

InstructGPTの課題としては、ラベル付けする人のほとんどが英語圏の人間であることで英語圏の人間の文化的価値化に偏っていることや、こうしてユーザーの指示に素直に従うようトレーニングしていった結果、ユーザーが危険な出力(陰謀論的なものなど)の生成を指示することで悪用が可能になってしまうことなどがある。後者については、モデルが特定の指示を拒否できるようにすることに取り組んでいるという。
関連記事
 OpenAI、文章から画像を生成する新モデル「GLIDE」 前モデルよりも高品質な画像を生成
OpenAI、文章から画像を生成する新モデル「GLIDE」 前モデルよりも高品質な画像を生成
OpenAIの研究チームは、自然言語からフォトリアリスティックな画像を生成する機械学習の新しいモデル「GLIDE」を開発した。 言語モデル「GPT-3」、APIの人数制限を撤廃 誰でもすぐに利用可能に
言語モデル「GPT-3」、APIの人数制限を撤廃 誰でもすぐに利用可能に
米AI研究企業のOpenAIは、大規模自然言語処理モデル「GPT-3」のAPIを利用する際の人数制限を撤廃し、誰でもすぐに利用できるようにしたと発表。 キーワードから小説や画像を自動生成 自然言語処理の革命児「GPT-3」の衝撃
キーワードから小説や画像を自動生成 自然言語処理の革命児「GPT-3」の衝撃
「GPT-3」「OpenAI」というキーワードが人工知能界隈で飛び交っている。これはいったい何なのか、どこがすごいのか、探ってみた。 Microsoft、OpenAIに10億ドル出資し、汎用AI開発に取り組む
Microsoft、OpenAIに10億ドル出資し、汎用AI開発に取り組む
Microsoftとイーロン・マスク氏らが立ち上げたAI企業OpenAIがAGI(汎用AI)開発で提携する。MicrosoftがOpenAIに10億ドル出資し、OpenAIの独占的クラウドプロバイダーになる。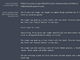 OpenAI、まことしやかなフェイクニュースも簡単生成の言語モデル「GPT-2」の限定版をオープンソース化
OpenAI、まことしやかなフェイクニュースも簡単生成の言語モデル「GPT-2」の限定版をオープンソース化
非営利の米AI研究企業OpenAIが、人間が冒頭テキストを与えるとコンテキストを判断して首尾一貫した続きの文章を生成する言語モデル「GPT-2」を発表。フェイクニュース生成などの悪用を懸念し、オープンソース化はしない。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PRアイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。