ITmedia NEWS >
速報 >
FlickrとInternet Archive、1400万点以上の検索可能な歴史的画像プロジェクト
» 2014年09月01日 09時46分 公開
[佐藤由紀子,ITmedia]
米Yahoo!傘下のFlickrと米Internet Archiveは8月29日(現地時間)、Internet Archiveがデジタル化した書籍から抽出した画像1400万点以上をカタログ化するプロジェクトを発表した。既に約260万点のパブリックドメインの画像をFlickrのInternet Archive Book Imagesで閲覧できる。
Internet Archiveは、誰もが無料で自由に利用できるインターネット図書館構築を目指す非営利団体で、これまでに過去500年以上にわたって出版された著作権の切れた書籍6億ページ以上(容量にして約19ペタバイト)をOCRでPDF化し、Archive.orgで無料で公開している。
Flickrとのプロジェクトでは、この膨大なデータから高精細の画像を抽出し、タグを付けてFlickr上で検索できるようにした。例えば「birds」の検索結果は以下の通り。
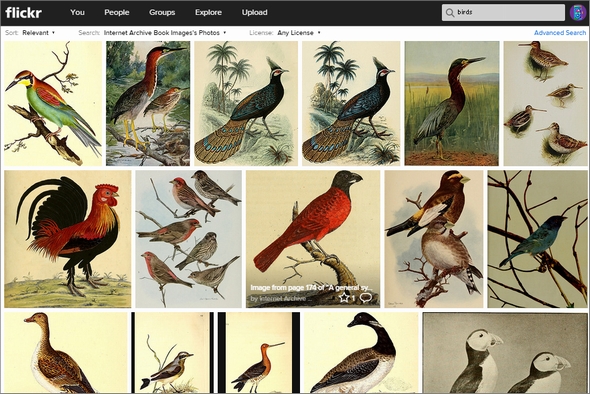
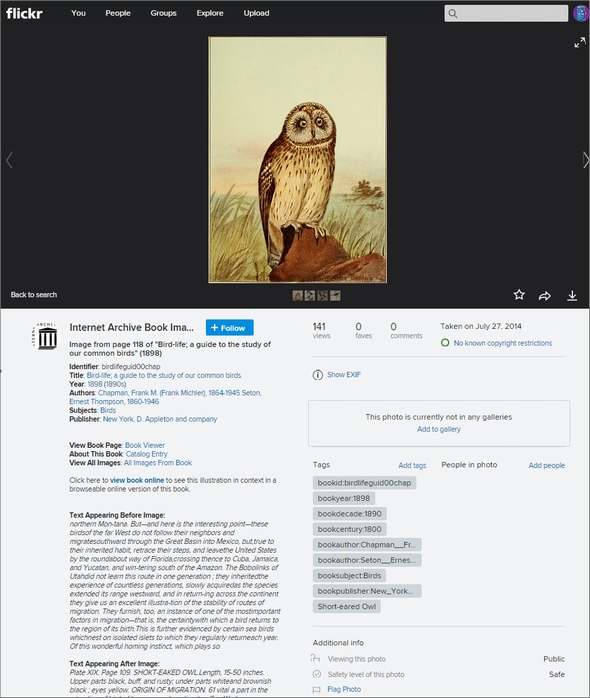
画像をクリックすると、その拡大画像とともに、書籍の詳細が表示される。画像の前後500ワード分がその場で読める他、タイトルをクリックすればArchive.orgで書籍を最初から読むことも可能だ。
Flickrは、ビッグデータ解析により、既にデジタル化されていた膨大なデータから世界でも有数の新たな画像ライブラリを構築できたことは注目に値すると説明している。
関連記事
 Flickr、ユーザーが写真を販売できるライセンスサービスを立ち上げ
Flickr、ユーザーが写真を販売できるライセンスサービスを立ち上げ
FlickrのユーザーはMarketplaceプログラムに参加することで、米Yahoo!のサイトやNew York Times、BBCで自分の写真を有料で採用してもらえるかもしれない。 米Yahoo!、Flickr強化に向けて画像認識のIQ Enginesを買収
米Yahoo!、Flickr強化に向けて画像認識のIQ Enginesを買収
画像認識技術で写真への自動タグ付けを可能にするツールを手掛けるIQ Enginesが、米Yahoo!傘下の写真共有サービスFlickrのチームに参加する。- Internet Archive、10万冊のデジタル化達成
Yahoo!、Adobeらが設立したOCAのアーカイブを運営する非営利団体Internet Archiveが、書籍10万冊のデジタル化を達成した。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
Special
PRアイティメディアからのお知らせ
SpecialPR
あなたにおすすめの記事PR
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。