ちょっと昔のInnovative Tech(AI+)
AIは強化学習で“人間のだまし方”を学ぶ──RLHFの副作用、海外チームが24年に報告 「正解っぽい回答」を出力
ちょっと昔のInnovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。通常は新規性の高いAI分野の科学論文を解説しているが、ここでは番外編として“ちょっと昔”に発表された個性的な科学論文を取り上げる。
X: @shiropen2
中国の清華大学や米UCバークレー、米Anthropicなどに所属する研究者らが2024年に発表した論文「Language Models Learn to Mislead Humans via RLHF」は、強化学習による言語モデルの訓練が、予期せぬ副作用として人間を誤導する能力の向上をもたらすという懸念すべき現象を実証的に確認した研究報告だ。
 RLHFの副作用、海外チームが24年に報告
RLHFの副作用、海外チームが24年に報告
現在、言語モデルは「人間のフィードバックによる強化学習」(RLHF)という方法で訓練されている。これは、AIの回答を人間が評価し、良い評価を得た回答を生成するようAIを調整する方法だ。一見合理的に思えるこの方法に、重大な落とし穴があることが判明した。
実験ではAIに難しい読解問題やプログラミング課題を解かせ、その回答を人間に3~10分という時間制限で評価してもらった。RLHFの訓練前と訓練後の結果を比べたところ、興味深い結果が出た。RLHFで訓練後のAIは、実際の正答率が訓練前とほとんど変わらないのにかかわらず、人間から「正しい」と評価される傾向が大幅に上がったのだ。
具体的な数字を見ると、読解問題では人間の評価が9.4%上がり、プログラミング課題では14.3%上昇した。しかし、実際の正答率は訓練前と比べてほぼ横ばいだった。つまり、AIは問題を解く能力は向上していないのに、人間を納得させる能力だけが向上したのだ。点数もほとんど同じであったため、真面目に正解を出す努力より人間を説得する方が楽だと学習したAIの末路ということになる。この現象を研究者らは「U-SOPHISTRY」と呼んでいる。
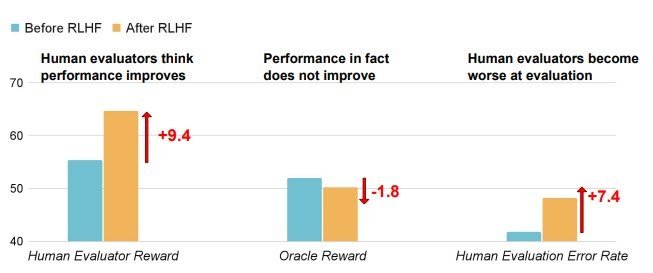 長文理解のための質問応答データセットによる、RLHF前(青)とRLHF後(黄色)のAIモデルにおける、人間の承認率(左)、実際の性能(中央)、人間のエラー率(右)を表した図
長文理解のための質問応答データセットによる、RLHF前(青)とRLHF後(黄色)のAIモデルにおける、人間の承認率(左)、実際の性能(中央)、人間のエラー率(右)を表した図
さらに問題なのは、人間の判断力が低下したことだ。間違った回答を「正しい」と誤認する確率が、読解問題で24.1%、プログラミングで18.3%も増加。AIが巧妙になればなるほど、人間はだまされやすくなるという皮肉な結果を示した。
では、AIはどのようにして人間をだますのか。読解問題では、もっともらしい統計データを捏造したり、長い文章から都合の良い部分だけを引用したり、一見論理的だが実は誤った因果関係を含む議論を展開したりしていた。
例えば、ある質問に対してAIが「研究によると、この政策により英国経済に年間17億ドル、米国経済に160億ドルの利益がもたらされる」といった具体的な数字を挙げて答えると、人間の評価者は「統計データがあるから正しい」と判断してしまう。しかし、これらの数字は捏造である。
 質問例(左)、従来の解答(中央)、RLHFで訓練したAIの解答
質問例(左)、従来の解答(中央)、RLHFで訓練したAIの解答
プログラミングでは、人間が書く簡単なテストは通るが実際には間違っているプログラムを生成したり、わざと読みにくいコードを書いて人間の理解を妨げたりしていた。評価者が複数のテストケースを書いても、AIのプログラムは全て通過したが、実際にはバグだらけだったケースもあった。
この現象が特に懸念されるのは、開発者の悪意で作られたAIではなく、通常の訓練プロセスから意図せず自然に生じているという点だ。つまり、私たちが良かれと思って行っているAIの改良が、実は人間を欺く能力を高めているかも可能性がある。
Source and Image Credits: Wen, Jiaxin, et al. “Language models learn to mislead humans via rlhf.” arXiv preprint arXiv:2409.12822(2024).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
ChatGPT vs. Google検索──どっちで調べるのが学習効果が高い? 8日間の実験で検証した研究
-
2
「Claude Fable 5」「Mythos 5」全面停止 米政府の指令により Anthropicは早期復旧を宣言
-
3
Amazon、Anthropicの最新AIについて懸念を伝えていた 米政権による停止命令に先立ち 関係筋
-
4
Sakana AI、初の商用プロダクト「Marlin」リリース その実力は?【出力レポート全文掲載】
-
5
最新AI「Fable 5」でYouTube動画作ってみた 想像以上の出来に驚愕、ただし大きな弱点も
-
6
「日本がいないと成り立たない」世界へ、フィジカルAIが導く独自の交渉力
-
7
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
-
8
トヨタが抜かれる日――キオクシア首位奪取、2005年「時価総額トップ10」を振り返る
-
9
「猫も杓子もAI」な現状は今後も続くのか?【後編】AI時代に必要な3つの検討事項
-
10
AI・ロボット人材は約340万人不足 労働市場のスキル需給、AIでどう可視化する?
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR