OpenAI、AIの経済的価値を測る新指標「GDPval」発表 トップ性能はClaude
米OpenAIは9月25日(現地時間)、AIモデルの性能を、幅広い業界や職種における人間の専門家と比較する新たなベンチマークテスト「GDPval」を発表した。同社は、汎用人工知能(AGI)が全人類に利益をもたらすことを確実にするというミッションの一環として、AIモデルが現実世界で人々をどのように支援できるかについての進捗状況を透明性をもって伝えるためにGDPvalを導入したとしている。
GDPvalは、モデルが経済的に価値のある現実世界のタスクでどれだけ優れたパフォーマンスを発揮するかを追跡するために設計された新しい評価手法という。AIが労働に与える影響を測定する最初の一歩であると位置づけている。
OpenAIは、GDPvalのような評価を通じて、将来のAIの改善に関する議論を推測ではなく証拠に基づかせることができるとし、AIモデルの社会的な影響を評価するためのより良いデータを得るために、この作業がモデルの進捗状況を追跡する科学に貢献することを望んでいるという。
GDPvalの名称は、主要な経済指標である国内総生産(GDP)の概念から来ており、米国のGDPに最も貢献している主要産業の職業からタスクが抽出されている。この評価は、米国のGDPに貢献するトップ9のセクターから選ばれた44の職業にわたる、複雑なマルチモーダルタスクを対象としている。
 GDPvalには44の職業の実際の仕事が含まれる(画像:OpenAI)
GDPvalには44の職業の実際の仕事が含まれる(画像:OpenAI)
GDPvalのタスクは、ソフトウェア開発者、弁護士、看護師、機械エンジニアなど、幅広い職種の経験豊富な専門家(平均14年以上の経験)によって作成され、現実の作業成果物(法務概要、エンジニアリングの設計図、顧客サポートの会話など)に基づいている。従来のベンチマークが学術的な試験形式(MMLUなど)に偏りがちだったのに対し、GDPvalは現実性と多様性において際立っており、単純なテキストプロンプトではなく、参照ファイルやコンテキストが付属し、ドキュメント、スライド、スプレッドシート、マルチメディアなどの成果物を要求する。この評価のフルセットには1320の専門タスクが含まれており、そのうち220のタスクがオープンソース化されている。
業界の専門家が採点者となり、モデルが生成した成果物と人間の専門家が作成した成果物をブラインド形式で比較する評価の結果、今日の最先端モデルはすでに業界の専門家が生み出す仕事の質に近づいていることが判明したという。
この評価には、OpenAIのモデル(GPT-4o、o4-mini、o3、GPT-5)に加えて、米AnthropicのClaude Opus 4.1、米GoogleのGemini 2.5 Pro、米xAIのGrok 4などの他社の主要モデルも含まれた。その中で、Claude Opus 4.1が最高のパフォーマンスを発揮したモデルで、人間の専門家による成果物と「同等かそれ以上」と評価された割合が、タスクの約半数に達した。
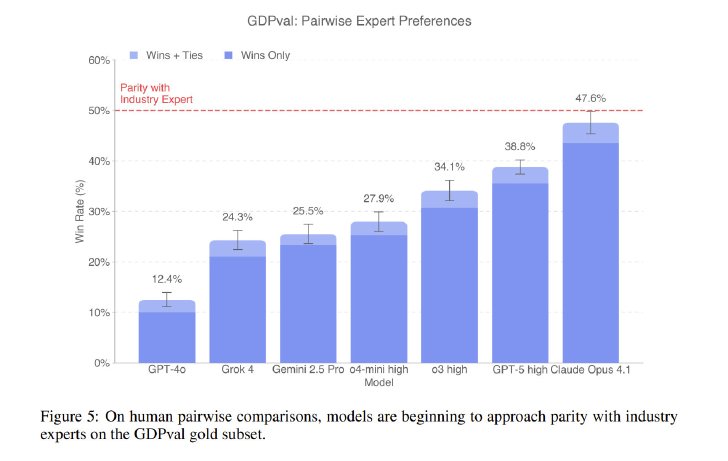 経済的に価値のあるタスクの性能評価(画像:OpenAI)
経済的に価値のあるタスクの性能評価(画像:OpenAI)
性能は過去1年間でほぼ線形に増加しており、特にOpenAIのモデルにおいては、昨年春にリリースしたGPT-4oから今夏リリースのGPT-5にかけて性能が2倍以上に向上するなど、この1年でGDPvalタスクにおける自社モデルのパフォーマンスは3倍以上になったという。
さらに、フロンティアモデルの場合、現実の職場でモデルを使用するために必要な人間の監視や反復のステップは含まれていないものの、業界の専門家よりも約100倍速く、100倍安くGDPvalタスクを完了できることも判明したという。
OpenAIは、テストの範囲を拡大し、より有意義な結果を得るために、アプローチを継続的に改良していくとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
-
2
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想
-
3
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
-
4
中国が人型ロボット開発競争をリードする「納得の理由」 日本に残された逆転シナリオは?
-
5
「もはや宗教」のClaudeに焦るOpenAI 流出メモが暴いた覇権交代のリアル
-
6
「今、Codexのレート制限を解除したい」を解決? “付与したリセット権の貯蓄”可能に 有料ユーザー向け
-
7
東大松尾研が「LLM講座 基礎編」の講義資料を無料公開 期間限定で
-
8
JASRAC、「AI作曲・人間作詞」の曲は管理します――「人間の創作的寄与の有無」で線引き
-
9
「人型ロボ世界シェア1位」中国Unitreeに聞く“普及戦略” 日本市場をどう開拓?
-
10
「日本がいないと成り立たない」世界へ、フィジカルAIが導く独自の交渉力
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR