これからのAIの話をしよう(スケート編)
元フィギュアスケート選手とディープラーニングの華麗な出会い 「選手の役に立ちたい」社会人大学院生の挑戦(3/5 ページ)
まず回転不足を判定するにあたって、データを「回転不足なし(0)・軽度回転不足(1)・重度回転不足(2)」の3種に分ける三値分類という問題設定に落とし込みました。廣澤さんいわく「課題意識を研究テーマとして実現可能なレベルに落とし込むのが難しかった」そうです。
データセットは、2018年~19年のグランプリシリーズの放映映像を中心に、単独ジャンプ部分のみを切り出し、日本スケート連盟のサイトにある競技結果を参考に正解ラベルを付与しました。総データ数は599件で、これを訓練データ(80%)とテストデータ(20%)に分けて機械学習モデルを作成しています。
データ1つ1つに正解ラベルを付ける作業は時間がかかりますが、「ジャンプの判定は専門性がすごく高い作業なので、他の人にやってもらうのは難しかった」といいます。結局、廣澤さん1人でコツコツ作成していきました。
加えて回転不足を判定するのですから、データセットには「回転不足だったときのデータ」が必要になります。しかし、モデルの質を担保するためにはトップレベルの選手や審判のデータを使用する必要があります。「国際大会の中でも一番レベルの高いシニア部門のデータを使ったのですが、技術的に優れた選手が集まっているので回転不足のデータは少なかったです」(廣澤さん)
モデル作成において、オープンに公開されている「Sports-1M データセット」で学習済みの3D CNNを特徴抽出器として使用しました。選手のジャンプ画像を読み込ませ、中間層で4096次元の特徴ベクトルを抽出、それをSVMで学習させました。
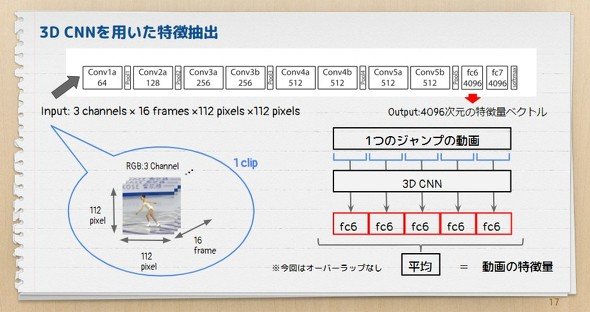 3D CNNを用いた特徴抽出
3D CNNを用いた特徴抽出
廣澤さん自身、実装が不慣れだったこともあり「休日と仕事終わりの時間を利用して、年明けから始めて2カ月ぐらいかかりました」と話します。
「論文で実装されているコードは公開されており、既存の論文の再現であればそんなに時間がかからないので助かりました。ただ、映像データの前処理は特に時間がかかりました。ここは僕が勉強できていなかったところで、学生の手を借りました」(廣澤さん)
テストデータを評価したところ、約73%の精度で回転不足を判定できました。7割を超えたのでなかなかの高精度……と言いたいところですが、分析結果を見るとそう楽観視はできないことが分かりました。
分析結果をどう評価する?
分析結果の内訳をみると、何と「全てのジャンプを回転不足なしと予想していた」のです。先述したように、トップ選手が多いのでもともと「回転不足なし」のデータの割合多いのです。
Copyright © ITmedia, Inc. All Rights Reserved.
これからのAIの話をしよう
いま話題のAI(人工知能)には何ができて、私たちの生活に一体どのような影響をもたらすのか。AI研究からビジネス活用まで、さまざまな分野の専門家たちにAIを取り巻く現状を聞いていく。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
Google、パーソナルAI「Gemini Spark」を日本でも利用可能に Chrome統合は米国から
-
2
新作「レイダース」で初めて「スプラトゥーン」に触れたマンガ家がその面白さに驚愕! と同時に絶望した理由
-
3
ソニー、タムロン買収提案の狙いを説明 「イメージング事業の発展につながる」
-
4
ドコモ、ahamoを30→40GBに増量 8月1日から 料金据え置きの新キャンペーン
-
5
一般消費者が「空調服」と書いたら商標権侵害? 公式Xの注意喚起が波紋、弁理士の見解は
-
6
セブン&アイ、共通会員IDのPayPay統合を正式発表 ソフトバンクや三井住友カードなどが計3000億円出資
-
7
防衛省の「クーラー300台」投稿動画でビックカメラのトラックが注目を集める 同社「販売用の在庫を迅速に提供」
-
8
OpenAI、アクティブユーザー10億人超に 導入企業は200万社超
-
9
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
10
「文スト」スマホゲーム、きょう告知→あす終了 突然のサ終にユーザー混乱 運営元の廃業で
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR