Innovative Tech
文章から「3Dアバター」と「動き」を自動作成するAI シンガポールと中国のチームが開発
Innovative Tech:
このコーナーでは、テクノロジーの最新研究を紹介するWebメディア「Seamless」を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。
シンガポールのNanyang Technological University、中国のSenseTime Research、中国のShanghai AI Laboratoryによる研究チームが開発した「AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars」は、テキスト入力から3Dアバターとその動きをゼロショットで生成する機械学習を用いたシステムだ。
専門的な知識を必要とせず、初心者でも自然言語のみを使って3Dアバターを好きな形やテクスチャにカスタマイズし、記述した動作でアバターを動かすことができる。
例えば、「I want to generate a tall and fat Iron Man that is running.」(背が高く、太ったアイアンマンが走っている姿を生成したい。)の入力で下記画像の左上を生成する。
「I would like to generate a skinny ninja that is raising arms.」(腕を振り上げている痩せた忍者を生成したい。)で画像の右上、「I want to generate a tall and skinny female soldier that is arguing.」(背が高く痩せた女性兵士が議論している姿を生成したい。)で画像の左下、「I want to generate an overweight sumo wrestler that is sitting.」(座る太った力士を生成したい。)で画像の右下を生成する。
 AvatarCLIPは自然言語からアバターの形状や動作を生成する
AvatarCLIPは自然言語からアバターの形状や動作を生成する
デジタルアバターの制作は、キャラクターの形状作成、テクスチャーの描画、スケルトンのリギング、モーションキャプチャーによるアバターの駆動など、多様な工程が行われる。それぞれの工程で専門的なソフトウェアに精通した多くの専門家と膨大な作業時間などが求められる他、大企業しか手が出せない高価な機材が必要だ。
昨今では大規模な事前学習済みモデルや高度な人間表現など、学術的な進歩により、この複雑な作業を小規模スタジオでも利用できるようになり、さらには大衆に至るまで手が届くようになってきた。この研究ではさらに一歩進んで、自然言語記述のみから3Dアバターを生成し、アニメーションさせることができる「AvatarCLIP」を提案する。
これまでにもアバター生成やモーション合成など、いくつか類似した取り組みが行われてきた。これらは一般的に教師あり学習のためにペアデータを必要とするが、テキストからアバター/モーション生成となると、ペアとなるデータを取得するのは難しい。
最近の進歩において、文章と画像のペアを推定する事前学習済みモデル「CLIP」が登場した。CLIPはテキストから画像生成をゼロショットで行うことに成功している。これらの研究に触発され、今回も3Dアバターのゼロショットテキスト駆動生成とアニメーションを達成するためにCLIPを利用する。
CLIPは静止画でしか学習しないため、連続した動きが不得意である。そのためCLIPのみを用いて合理的なモーションシーケンスを生成することは本質的に困難である。この問題に取り組むため、研究チームは全プロセスを2段階に分ける。1段階目はCLIPによる静的アバターの生成、2段階目は候補ポーズを参照したモーションの合成。
このようにパイプライン全体の設計を工夫することで、入力テキストに対する合理的なモーションシーケンスを持つ3Dアバターを生成することができる。
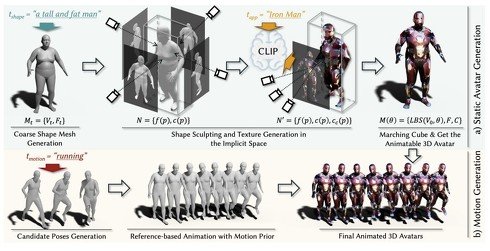 提案手法のパイプラインの概要
提案手法のパイプラインの概要
広範囲な定性的・定量的実験により、生成されたアバターとモーションは既存の手法と比較して高品質であり、対応する入力自然言語と高い整合性があることを示した。
 さまざまな出力結果
さまざまな出力結果
Source and Image Credits: Hong, Fangzhou, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang and Ziwei Liu. “AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars.”
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
「Xが情報収集に役立たない……」熊本地震で不満の声続出 「Twitterを返して」
-
2
メルカリ、梨の転売疑惑に「盗品の出品は確認されず」 誹謗中傷には利用制限も
-
3
「こんなのに追われたら……」急斜面もやすやす爆走、中国製の車輪付き四足ロボのデモ動画が話題 最高時速20km超
-
4
検索結果に「詐欺ではありません」と表示させる詐欺手口、警視庁が注意喚起 AI要約も餌食に
-
5
はてな、11億円流出の調査報告書を公開 偽警察、口外禁止、残業・休出200時間超、孤立……ほころびが連鎖
-
6
熊本「通れた道」マップ、トヨタが公開 ホンダも「通行実績情報マップ」
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
Z世代に聞く次の流行、「AIイラスト」が1位に 「Claude Code」も上位
-
9
東野圭吾さん死去、Xなどで追悼相次ぐ 「ガリレオ」など数々の人気作、エンジニアから転身
-
10
NVIDIAやMicrosoftなど30社超、オープンAIの防御ツール共同開発の「Open Secure AI Alliance」設立
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR