NVIDIA製GPUの数十倍速い? 次々に出てくる「AI専用チップ」とは何者か 識者に聞く高速化の仕組み(3/3 ページ)
──トランスフォーマーの特徴は、ハードウェア設計にどのような影響を与えるのでしょうか?
椎橋:トランスフォーマーモデルの特性は、従来のGPUで効率的に処理するのが難しい面があります。
トランスフォーマーの処理はRNNと比較するとGPUの計算に向いているものの、先ほど説明したように複雑に絡み合っているため、単純な並列計算に持ち込むのが難しいのです。
また、GPUとメモリの間でデータをやりとりする回数が多くなります。トランスフォーマーモデルの処理では、入力されたデータをメモリに置いて、それを何度も参照しながら計算を行います。そのため、メモリアクセスと演算処理の切り替えが頻繁に発生します。これは処理効率を下げる要因になります。
このような特性に対応するため、トランスフォーマーモデルに最適化されたハードウェア設計が重要になってきています。
その鍵となる基本的な考え方は、ハードウェア(チップ)が実行できる計算処理(命令セット)をそのモデルアーキテクチャの処理に必要な種類の計算に絞って、それぞれの種類の計算をする処理ユニットをちょうど良いバランスでそろえて配置することです。
手工業に例えるならば、CPUはどんな作業でもこなせる多能工が1人でいろいろな製品を作っている状態、GPUはどんな作業でもこなせる多能工が複数人で並行していろいろなパーツを作り組み立てている状態です。作りたい製品が多様な場合は効果的な方法ですが、作りたい製品と組み立てのプロセスが決まっている場合、これは非効率なやり方です。
ではどうしたらいいか。それは、必要な各作業に特化した単能工をそれぞれちょうど良い人数をそろえて、作業分担をする形で配置し、流れ作業のラインを作ることです。
先ほど述べたGroqのLPUは、その仕組みに「Tensor Streaming Processor」、つまり言語モデルの処理の中心になる行列(テンソル)のいくつかの種類の計算をユニット化して、ユニット間で処理データを受け渡していく流れ作業(ストリーミング)にする、という考え方を採用することで、言語モデルの推論の大幅な高速化を実現しています。
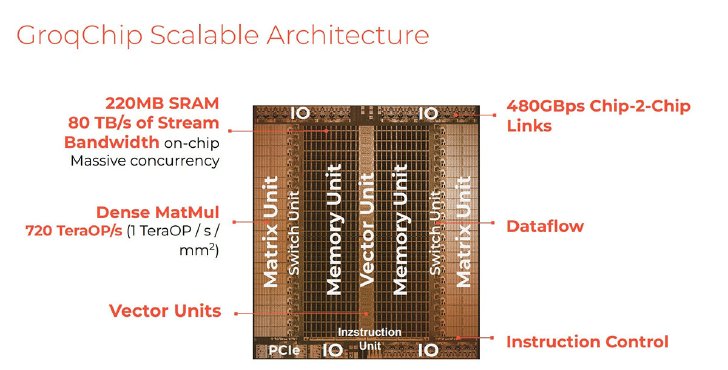 Groqチップのアーキテクチャ。やりたいことを言語モデルの処理に絞れば、「Matrix Unit=密行列の掛け算をする部分」「switch unit=データを流す処理の部分」「メモリ」「Vector Unit=ベクトルの計算を扱う部分」のようにシンプルな処理ユニットの種類を作って並べることができる
Groqチップのアーキテクチャ。やりたいことを言語モデルの処理に絞れば、「Matrix Unit=密行列の掛け算をする部分」「switch unit=データを流す処理の部分」「メモリ」「Vector Unit=ベクトルの計算を扱う部分」のようにシンプルな処理ユニットの種類を作って並べることができる
また、大胆にトランスフォーマーアーキテクチャのみに照準を定めるEtchedのSohuは、さらに細かくトランスフォーマーの計算処理プロセスにピッタリ合わせた計算ユニットの設計と配置を行いました。トランスフォーマーの処理であれば、従来GPUが計算リソースの30%程度しか有効に稼働させられていなかったところを、90%以上の稼働を実現しているとうたっています。
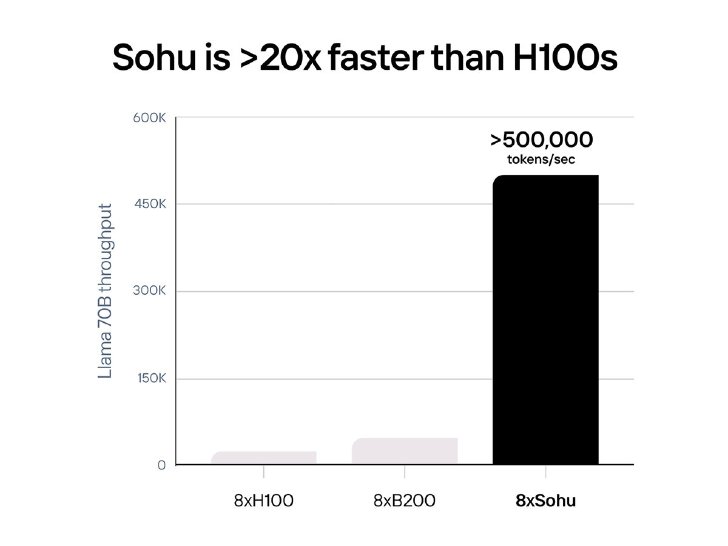 Sohuは、Llama70Bのスループットで毎秒50万トークンを超え、現在の主流GPUであるH100に比べて20倍の速さ、NVIDIAの次世代GPUであるBlackwell(B200)に比べても桁違いに高速で安価になることを狙っている
Sohuは、Llama70Bのスループットで毎秒50万トークンを超え、現在の主流GPUであるH100に比べて20倍の速さ、NVIDIAの次世代GPUであるBlackwell(B200)に比べても桁違いに高速で安価になることを狙っている
──トランスフォーマーモデルに特化したハードウェアには課題はありませんか?
椎橋:最大の課題は汎用性の低さです。トランスフォーマーモデルに最適化されたハードウェアは、他タイプのAIモデルをそもそも実行できなかったり、実行できても効率が大きく低下する可能性があります。
また、AIのアーキテクチャは急速に進化しています。例えば、最近では米MicrosoftのRetentive Networkや、画像処理分野でのMamba(選択的状態空間モデル)など、トランスフォーマー以外の新しいアーキテクチャも登場しています。特定のアーキテクチャに過度に最適化されたハードウェアは、新しいモデルが登場した際に陳腐化するリスクがあります。さらに、トランスフォーマーモデル自体も進化を続けています。ハードウェアの開発サイクルはソフトウェアよりも長いため、最新のモデルの特性に常に対応し続けることは難しい課題です。
ただ、こういった課題がある一方で、可能性もあります。トランスフォーマー向けASICがある程度普及すると、ハードウェアも含めて考えた場合、中期的にはトランスフォーマーモデルの方が有利な状況が続くかもしれません。
なぜかというと、現在のトランスフォーマーアーキテクチャは、特に大規模言語モデルの分野でほぼ独占状態にあるからです。そこにトランスフォーマー向けASICが普及すると、ソフトウェアの効率だけで見れば優れた新モデルが登場しても、ハードウェアも含めて考えるとトランスフォーマーの方が全体的に性能が良いという状況が生まれるかもしれないからです。この相互作用が、トランスフォーマーモデルの優位性をさらに強化する可能性があるのです。
AIチップで垂直統合のアプローチが増える?
これまでのコンピュータ産業、特にソフトウェア産業は、水平分業によって急速な発展を遂げてきた。ハードウェアとソフトウェアを分離することで、それぞれの分野で専門性を高め、イノベーションを加速させてきたのである。しかし、AIの世界では状況が少し異なるようだ。大規模な言語モデルの学習や推論には膨大な演算能力が必要で、エネルギー効率も重要な課題となっている。このリソースの制約に対処するためには、ハードウェアとソフトウェアを緊密に連携させる必要があるからだ。
そのため、AIチップの開発では、従来の水平分業よりも、ソフトウェアとハードウェアをすり合わせた垂直統合型のアプローチが増えていく可能性がある。これは、製造業における「すり合わせ」の文化を持つ日本にとって、新たな機会となるかもしれない。自動車産業や産業用ロボットなど、日本が強みを持つ分野でのAI応用と組み合わせることで、日本の半導体産業が再び世界で競争力を持つ可能性もあるだろう。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」「Mythos 5」全面停止 米政府の指令により Anthropicは早期復旧を宣言
-
2
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想
-
3
最新AI「Fable 5」でYouTube動画作ってみた 想像以上の出来に驚愕、ただし大きな弱点も
-
4
トヨタが抜かれる日――キオクシア首位奪取、2005年「時価総額トップ10」を振り返る
-
5
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
-
6
「人型ロボ世界シェア1位」中国Unitreeに聞く“普及戦略” 日本市場をどう開拓?
-
7
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
-
8
時価総額3兆ドルの原動力 NVIDIAトップが貫く「誰もやらない」逆張りの経営
-
9
中国が人型ロボット開発競争をリードする「納得の理由」 日本に残された逆転シナリオは?
-
10
Anthropic、最上位「ミュトス」級モデルを一般提供 悪用防ぐ保護機能を備えた「Claude Fable 5」
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR