Innovative Tech(AI+)
AIの大規模化→“人間には簡単な質問”への間違えが増加 スペインの研究者らが発表
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
スペインのバレンシア工科大学に所属する研究者らが発表した論文「Larger and more instructable language models become less reliable」は、大規模言語モデル(LLM)の規模を拡大し、より指示に従う能力を高めるほど、AIモデルの信頼性が低下する可能性があることが明らかになった研究報告である。
 AIの大規模化→“人間にとって簡単な質問”への間違えが増加
AIの大規模化→“人間にとって簡単な質問”への間違えが増加
AI開発者は通常、LLMの性能を向上させるために2つの主要な方法を用いる。1つは「スケールアップ」と呼ばれ、より多くのトレーニングデータと計算能力を投入すること。もう1つは「シェイプアップ」と呼ばれ、人間のフィードバックに基づいてモデルを微調整することである。
この研究では、米OpenAIの「GPT」、米Metaの「LLaMA」、国際研究プロジェクトのBigScienceによる「BLOOM」という3つの主要なLLMファミリーを詳細に分析した。研究チームは、単純な足し算から語彙(ごい)の並べ替え、地理的知識や科学的質問、情報変換といった5つの異なるベンチマークを用いて、これらのモデルの性能を多角的に評価した。
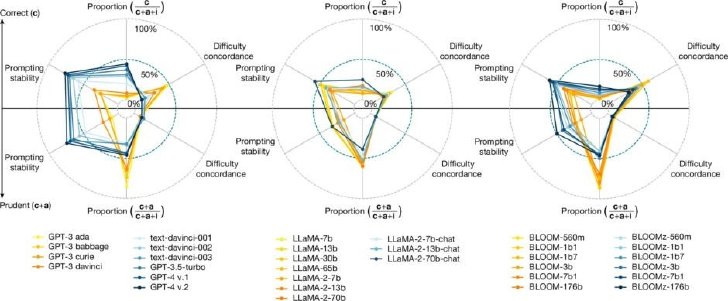 GPT、LLaMA、BLOOMファミリーのいくつかのモデルの主要な指標
GPT、LLaMA、BLOOMファミリーのいくつかのモデルの主要な指標
分析の結果、スケールアップとシェイプアップにより、複雑な問題への対応能力は向上したが、基本的な問題に対する正確性は向上しないことが判明した。具体的には、人間にとって比較的簡単な課題でも誤りを犯すようになり、回答を控えるべき場合でも、もっともらしいが間違った回答をする傾向が強まった。
これは、モデルが「知らない」ことを認めるよりも、常に回答しようとする姿勢が強くなったためと考えられる。
また、プロンプトの微妙な変化に対するモデルの安定性は向上したものの、難易度に関係なく不安定な領域が依然として残っていることも分かった。これは、同じ質問でもわずかな言い回しの違いで異なる回答が得られる可能性があることを意味し、LLMの実用化に向けて重要な課題となっている。
Source and Image Credits: Zhou, L., Schellaert, W., Martinez-Plumed, F. et al. Larger and more instructable language models become less reliable. Nature(2024). https://doi.org/10.1038/s41586-024-07930-y
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
Claude、利用制限を全リセット 競合「GPT-5.6」公開と同日……OpenAI幹部「ビビってるね」
-
3
「Claude Fable 5」サブスク、突如5日間延長 ユーザー悲喜こもごも「寝ずに頑張ったのに」「制限リセットして」
-
4
1万9000人が利用するソフトバンクの「全社RAG基盤」 構築の泥臭い舞台裏
-
5
「まるで人間」 OpenAIの新モデル「GPT-Live」のトーク力が話題 間を空けずに考えながら会話できる
-
6
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
-
7
AIがExcel作業を丸ごと自動化? 企業の定型業務を効率化へ
-
8
FDEとリコーの新コンサルサービス、どこが違う? AXのパートナー選びを考察
-
9
「生成AIをもう手放せない人」が約6割 逆に“使わなくなったもの”1位は?
-
10
CEOの利用額も「全社員に丸見え」 LayerXがAI予算を「第二の人件費」にした真意
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR