Innovative Tech(AI+)
なぜAIに“日本語”を学習させるのか? 35種類のLLMで実験し分析 東工大などが研究報告
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
9月3日に開催の第261回自然言語処理研究発表会において、東京工業大学と産業技術総合研究所に所属する研究者らが発表した「LLMに日本語テキストを学習させる意義」は、大規模言語モデル(LLM)に日本語を学習する効果について実験結果を基に評価した研究報告である。
この研究では、35種類のLLMに対して日本語と英語の19種類のタスクを用いて評価を実施し、その結果を詳細に分析。評価に用いたLLMは、学習データや構築手法によって大きく4つのカテゴリーに分類される。
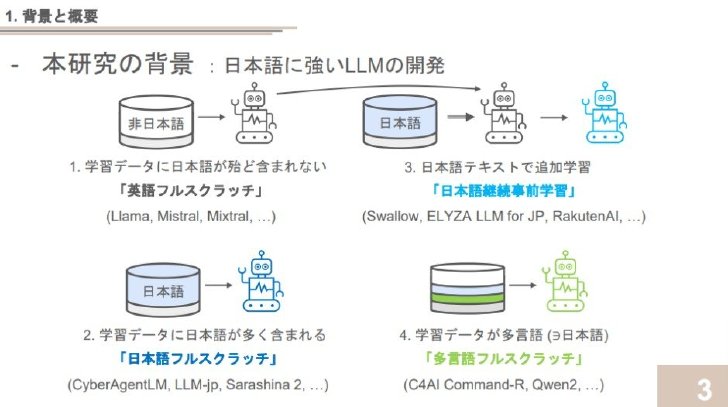 4つのカテゴリーに分類した、実験対象の35種類のLLM
4つのカテゴリーに分類した、実験対象の35種類のLLM
- 「英語フルスクラッチ」は英語中心のデータで学習されたモデル(Llama 3など)
- 「日本語フルスクラッチ」は日本語中心のデータで学習されたモデル(CyberAgentLM 2など)
- 「日本語継続事前学習」は英語モデルを日本語データで追加学習したモデル(Japanese Stable LMなど)
- 「多言語フルスクラッチ」は多言語データで学習されたモデル(Qwen 2など)
これらの多様なモデルを評価することで、日本語学習の効果をさまざまな角度から検証する。
評価タスクは、百科事典的知識・常識、読解、論理推論・算術推論、要約・翻訳、一般教養、コード生成など、幅広い能力を測定するものが選ばれた。これらのタスクの多くは日本語版と英語版に対応するものが用意され、言語間での性能比較が可能になっている。
分析の結果、いくつかの知見が得られた。まず、日本語の一般教養、算術推論、コード生成などの能力は、英語資源のみからでも獲得できる可能性を示唆した。これらのタスクでは、日本語版と英語版で強い相関を確認できた。
例えば「JMMLUとMMLU」(一般教養)、「JHumanEvalとHumanEval」(コード生成)、「MGSMとGSM8K」(算術推論)などのタスクペアで、英語版を元に構築した日本語版タスクである点に留意する必要はあるが、相関係数が0.9以上の相関を確認した。
一方、日本の知識に関する質問応答(NIILCなど)や英日機械翻訳(WMT20-en-jaなど)のタスクでは、日本語資源を学習させることで顕著な性能向上を確認。これらのタスクは他のタスクとの相関が比較的低く、日本語特有の学習効果が現れていると解釈できる。
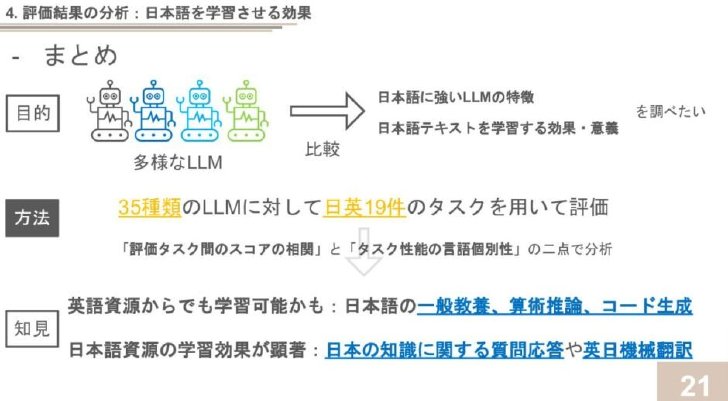 この研究の目的、方法、結果からの知見をまとめた図
この研究の目的、方法、結果からの知見をまとめた図
この研究は、日本語LLMの開発において重要な指針を提供している。英語資源からでも獲得可能な能力(一般教養や算術推論、コード生成など)と、日本語資源の学習が特に効果的な能力(日本の知識に関する質問応答や英日機械翻訳)を明らかにしたことで、効率的なモデル開発の方向性を示唆した。
また、能力因子も特定しており、各因子を強化するための適切な学習データの選択など、今後のLLM開発戦略に有用な指針となる可能性がある。
論文はこちら。
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「AIを使う学生」vs.「使わない学生」、エッセイが創造的なのはどっち? 米大学が2025年に実証実験
-
2
月間売上1億円超、“推しAI”アプリ「Zeta」がオタク女子わしづかみ ただし危うさも
-
3
「AIコーディング」がたった5年で急進化したワケ NTT「tsuzumi 2」開発者が分析
-
4
工数「76%」削減 味の素グループが「経理AIエージェント」導入で先陣を切れたワケ
-
5
AIで要らなくなったSaaS、要るSaaSは、どれ? 日本の「SaaS is dead」の実態
-
6
チームみらい安野氏「牧歌的なAI開発の時代が終わった」 “ミュトス停止騒動”受け
-
7
かんぽ生命、AIで営業支援 “郵便局での一言”拾って保険提案へ 寸劇で分かる活用例
-
8
ChatGPT vs. Google検索──どっちで調べるのが学習効果が高い? 8日間の実験で検証した研究
-
9
話題の「Claude Mythos」登場で変わるセキュリティ AIエージェント時代の防衛策
-
10
「待ちの営業」はもう限界 ホンダがAIエージェントで挑む、商機を逃さない「濃い商談」の創出
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR