Innovative Tech(AI+)
「時間の矢」が生成AIにも含まれていた? “未来から過去を予測”する逆の訓練をLLMで実施 海外チームが検証
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
スイスのEPFLや英ロンドン大学に所属する研究者らが発表した論文「Arrows of Time for Large Language Models」は、大規模言語モデル(LLM)が、次のトークンを予測する能力に比べて、前のトークンを予測する能力が劣ることを明らかにした研究報告である。研究チームは、この現象が自然言語を学習する際に、時間が過去から未来へと一方向にしか流れない「時間の矢」が影響していると指摘している。
 「時間の矢」が生成AIにも含まれていた?
「時間の矢」が生成AIにも含まれていた?
(関連記事:「なぜ時間は過去→未来にしか進まない?」を“量子もつれ”で説明か 未解決問題「時間の矢」に切り込む)
LLMは、テキスト生成やコーディング、チャットbotの運用、翻訳など、さまざまなタスクに不可欠な存在となっている。その核心は、過去の単語(トークン)に基づいて次のトークンを予測するという考え方にあり、これらのモデルは与えられた文脈から次のトークンを予測するように訓練される。しかし、この研究では逆方向、すなわち前のトークンを予測する訓練も行った。
研究チームは、GPT(Generative Pre-trained Transformer)、GRU(Gated Recurrent Unit)、LSTM(Long Short-Term Memory)など、異なる構造と規模を持つさまざまなLLMを検証。実験では、英語やフランス語を含む複数の言語のデータセットを使用し、モデルのサイズやコンテキストウィンドウ(AIモデルが応答を生成できるテキストの量)の長さを変えて評価を行った。
理論的には、前向きと後ろ向きの予測能力は同等であるはずだが、実験結果は異なることを示した。結果として、全てのLLMは一貫して、次のトークンを予測する場合よりも、前のトークンを予測する場合で精度が低いことが明らかになった。
この現象は英語とフランス語に限らず、ドイツ語、トルコ語、フィンランド語、ベトナム語、ギリシャ語、インドネシア語などの多様な言語でも確認できた。言語によって「時間の矢」の大きさ(前向きと後ろ向きの性能差)は異なるものの、全ての言語で前向きモデルの優位性が見られた。
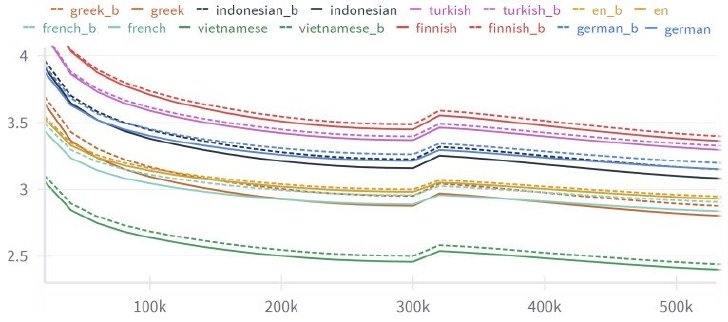 通常の前向き予測と逆向き予測を行う二種類のモデルの性能比較
通常の前向き予測と逆向き予測を行う二種類のモデルの性能比較
研究者たちは、この現象を説明するために、計算複雑性とスパース性(データの疎密さ)という概念を用いた理論的フレームワークを提案した。例えば、素因数分解と乗算の非対称性を利用した合成データセットを作成し、前向きモデルと後ろ向きモデルの性能差を示した。この例では、大きな数の素因数分解(逆方向の計算)が乗算(順方向の計算)よりも計算上困難であることを利用している。
さらに、二値演算に基づく言語モデルを導入し、スパース性と学習可能性の関係を探った。スパースな行列とその逆行列の性質を調べることで、順方向の変換がスパースであれば、その逆変換は一般的により密になる傾向があることを示した。これは、前向きモデルが後ろ向きモデルよりも学習しやすい構造を持つ可能性を示唆している。
これらの結果は、LLMがテキストを処理する方法に根本的な非対称性が存在することを意味している。つまり、AIは人間の言語使用に見られる「時間の流れ」のような特性を、学習過程で自然に獲得している可能性がある。
この研究は、自然言語が本質的に時間の方向性を持っている可能性を示唆している。言語の構造自体が「過去から未来へ」という方向性を持ち、それがモデルの学習過程に反映されているのかもしれない。
Source and Image Credits: Papadopoulos, Vassilis, Jeremie Wenger, and Clement Hongler. “Arrows of Time for Large Language Models.” arXiv preprint arXiv:2401.17505(2024).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
2
Sakana AI、一部「ミュトス越えの性能」うたうAIを提供 複数モデルの“集合知”を活用
-
3
NRIセキュア、未公表の脆弱性を「Mythosと同等のレベルで」検出する診断サービス提供
-
4
東電出資に意欲 孫正義氏が「国内データセンター誘致」で狙うインフラ戦略
-
5
Google、「Gemini 3.5 Flash」に「Computer Use」を標準搭載──AIが画面を見てブラウザやアプリを操作
-
6
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
7
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
8
Flashの再来? Figmaの新機能「Figma Motion」に懐かしいとの声 アニメーション生成するAI機能も
-
9
Amazon Bedrockのトークン処理量、26年1Qだけで過去累計超え AWSが目指す、AIのための「信頼できるインフラ」
-
10
OpenAI、次世代「GPT-5.6」シリーズを限定プレビュー 米政府と調整、命名は「Sol/Terra/Luna」に刷新
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR