DeepSeekで注目された「蒸留」って何だ? 識者が解説(2/3 ページ)
広義と狭義で異なる「蒸留」の定義
蒸留の本質は「大きいモデルで一度学習したエッセンスを小さいモデルに詰め込む」ことにある。「要は学習データが大量にあった時に、学習データから直接学ぶよりも、一回大きなモデルに学ばせておいて、そのエッセンスを抽出した小さいモデルを作る方が精度が高められる」と椎橋氏は説明する。
LLMの開発では、このアプローチが特に効果を発揮するという。「何でも知っている巨大モデルをいったん作り、その分野、コーディングや数学、論理などだけに強い小さいモデルを作りたければ、大きなモデルにその分野の問題をたくさん解かせてみる」(椎橋氏)という方法で、サイズは小さいのに高性能なモデルが作れるわけだ。OpenAIは明言していないが、例えばo1とo1-miniの関係もそれに近いだろう。
そして開発プロセスにおいて重要なのは、蒸留は学習の全過程ではなく、最後の調整段階で使われることだ。「LLMで蒸留を行う場合のほとんどのケースでは、全データを最初から蒸留で学習するわけではない。すでに学習済みのモデルの性能を、質の高いデータで最後に高める。これを業界では『ファインチューニング』と呼び、この段階で蒸留が効果を発揮する」と椎橋氏は指摘する。
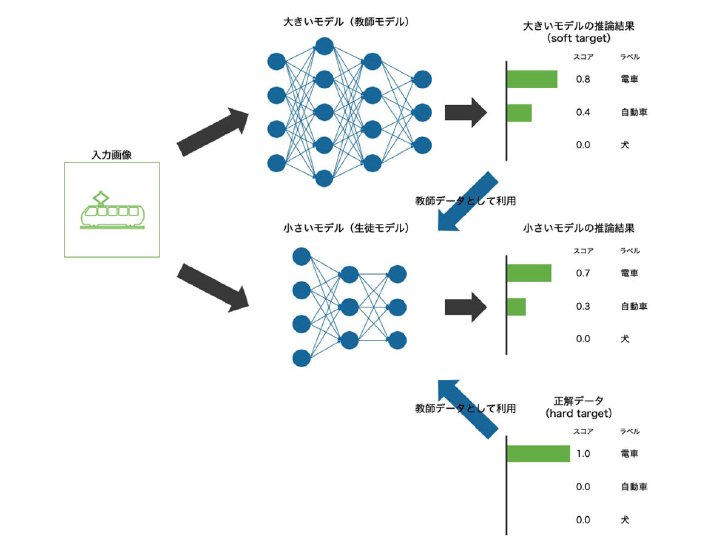 教師となるモデルの出力(確率文武)を使った狭義の蒸留のイメージ(Laboro.ai提供)
教師となるモデルの出力(確率文武)を使った狭義の蒸留のイメージ(Laboro.ai提供)
では、DeepSeekはOpenAIのモデルを蒸留したのか。それを考える前に、「『蒸留』という言葉には広い意味と、技術者が従来使っていた狭い意味がある」と椎橋氏は説明する。
広義の意味では「大きいモデルを学習し、そのモデルにいろいろなデータを生成させ、生成したデータを別の小さいモデルの学習データにする」という手法全般を指す。この意味では、OpenAIの出力データを一部でも学習に使ったら蒸留したといえそうだ。
一方、従来ある狭義の意味では、教師データには本来含まれない確率の情報まで利用して学習する手法を指している。「例えば画像を見て犬か猫かを判定する大きいモデルがあったとする。このモデルは『これは犬の確率が60%、猫の確率が40%』といった確率付きの出力を返す。これを小さいモデルの学習データにすることで、単なるラベルだけの教師データより効率的に学習できる。これが狭義の蒸留だ」と椎橋氏は解説する。
この狭義の蒸留は、モデルの中身が公開されているオープンウェイトモデルでこそ容易な手法だ。OpenAIのような非公開モデルでは内部の確率情報を直接取得することは難しい。
OpenAIには、APIを通じて次の単語の候補とその確率を取得できる機能もあり、技術的には狭義の蒸留も不可能ではないという。しかし、OpenAIが今回問題視しているのは、確率データの利用に絞った話ではなく、「とにかくChatGPTの生成データを追加学習やファインチューニングに使っているのではないか」という疑いのようだ。
「インターネット上にはChatGPTの出力結果が既に大量に存在する。そうした情報をクローリングして使用したのか、それとも意図的にAPIを使って蒸留したのか、その判定は極めて難しい」と椎橋氏は指摘する。ネット上に掲載されたChatGPTの出力結果を意図せずに学習してしまうことで、多くのAIモデルは「私はChatGPTです」「OpenAIのポリシーにより……」などの回答をすることがある。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
2
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
3
東電出資に意欲 孫正義氏が「国内データセンター誘致」で狙うインフラ戦略
-
4
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
5
AIが食い尽くすメモリ供給 企業ITを揺らす価格高騰
-
6
Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
-
7
NRIセキュア、未公表の脆弱性を「Mythosと同等のレベルで」検出する診断サービス提供
-
8
AIコーディングはなぜ後から苦しくなるのか? 技術負債に続く「理解負債」「認知負債」という新たな落とし穴
-
9
【入門】.claudeフォルダの構造と使い方 Claude Codeを思い通りに動かそう
-
10
【役に立つの?】「Google公式」の初心者向けAI講座、受けてみたら想像以上にすごかった
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR